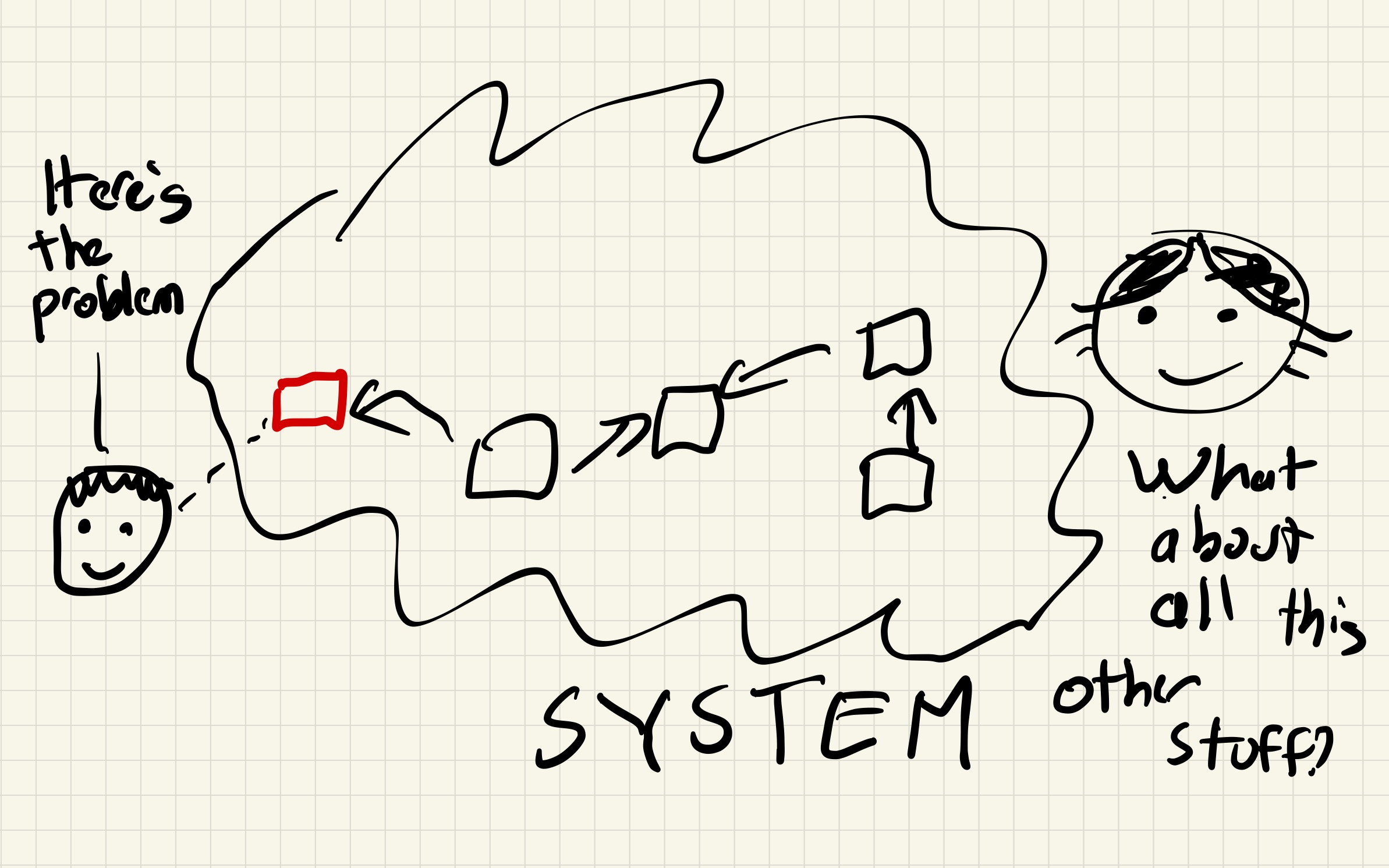
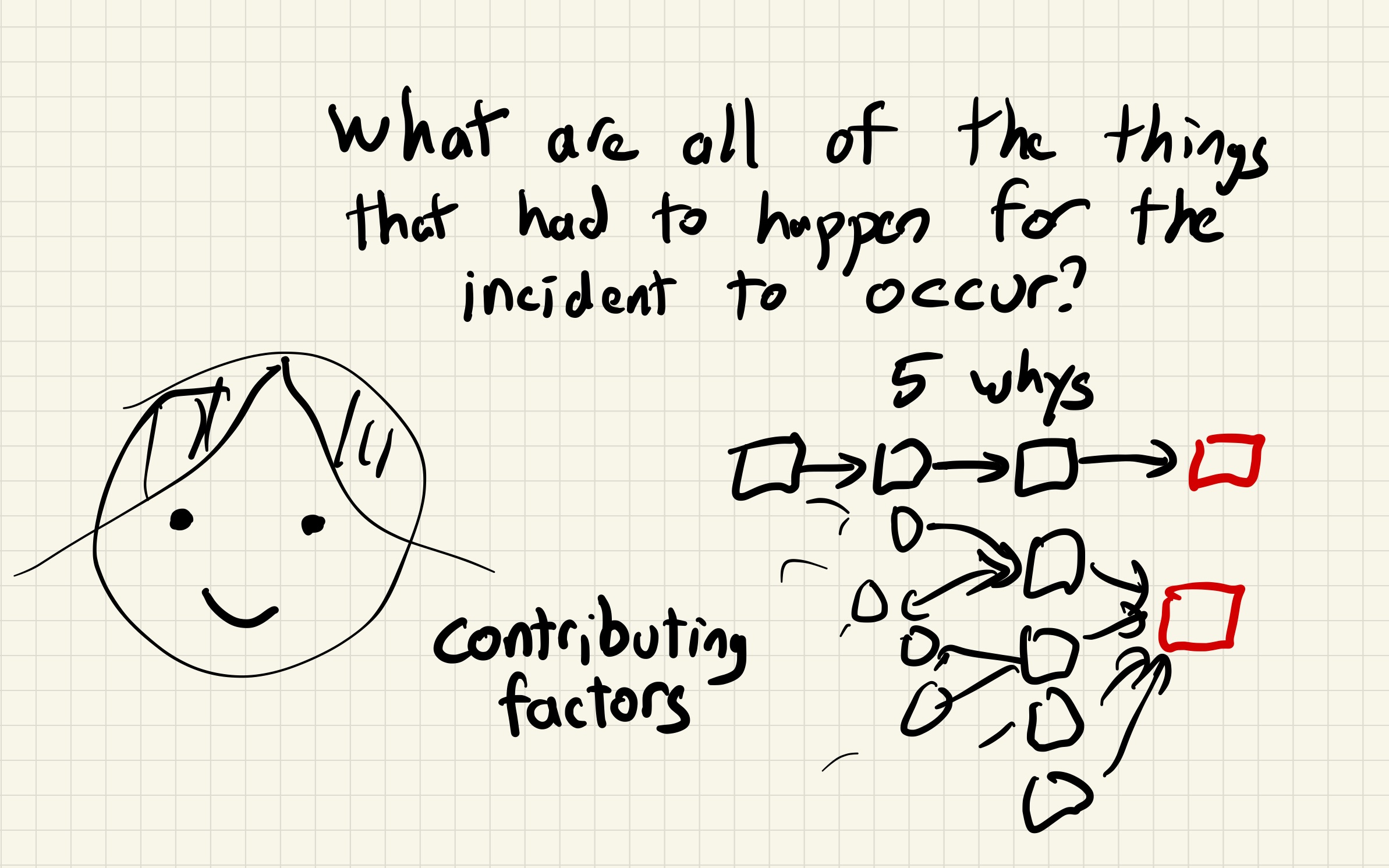
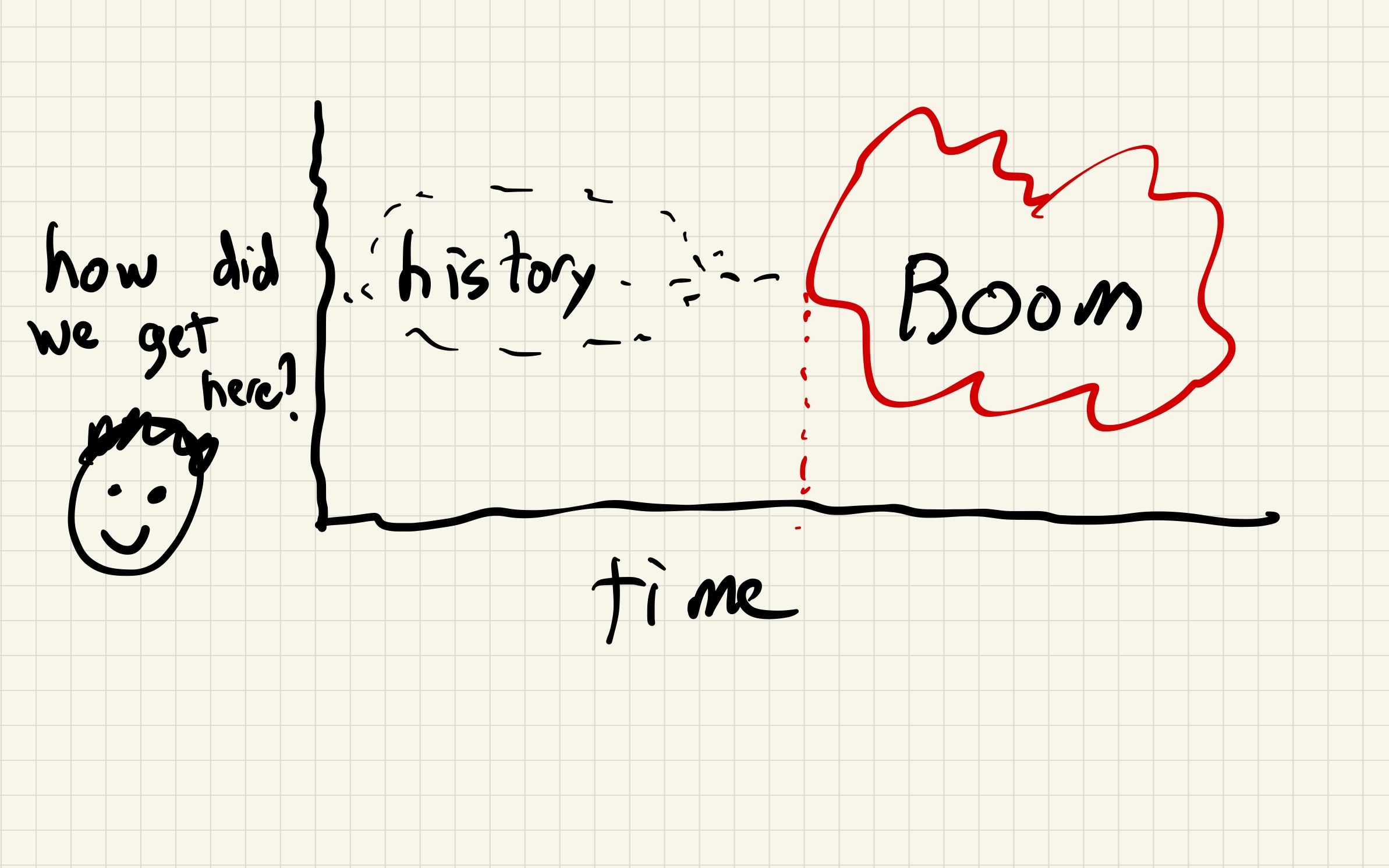
As I’ve posted about previously, at my day job, I work on a project called Managed Delivery. When I first joined the team, I was a little horrified to learn that the service that powers Managed Delivery deploy itself using Managed Delivery.
“How dangerous!”, I thought. What if we push out a change that breaks Managed Delivery? How will we recover? However, after having been on the team for over a year now, I have a newfound appreciation for this approach.
Yes, sometimes there’s something that breaks, and that makes it harder to roll back, because Managed Delivery provides the main functionality for easy rollback. However, it also means that the team gets quite a bit of practice at bypassing Managed Delivery when something goes wrong. They know how to disable Managed Delivery and use the traditional Spinnaker UI to deploy an older version. They know how to poke and prod at the database if the Managed Delivery UI doesn’t respond properly.
These strange loop failure modes are real: if Managed Delivery breaks, we may lose out on the functionality of Managed Delivery to help us recover. But it also means that we’re more ready for handling the situation if something with Managed Delivery goes awry. Yes, Managed Delivery depends on itself, and that’s odd. But we have experience with how to handle things when this strange loop dependency creates a problem. And that is a valuable thing.