Over the years, mathematicians, logicians and computer scientists have developed various calculi. If you have a background in computer science, you’ve likely heard of the lambda calculus, a model of computation that was developed by Alonzo Church. If databases are more your thing, then you’ve been exposed to the relational calculus without even knowing it, since SQL is based on the relational calculus. If you are into formal methods, then you’ve worked with the predicate calculus, better known as first-order logic. Finally, if you enjoy reading academic papers on programming languages, you’ve almost certainly run into the sequent calculus. However, when someone says “calculus” without modification (e.g., “I’m taking calculus next semester”), there’s no ambiguity about which calculus they are referring to: it’s always one particular calculus. Or, rather, two calculi that happen to be deeply related to each other: differential calculus and integral calculus.
Visually, you can think of differential calculus as being about calculating the slope of a function at a given point. For example, consider this graph:
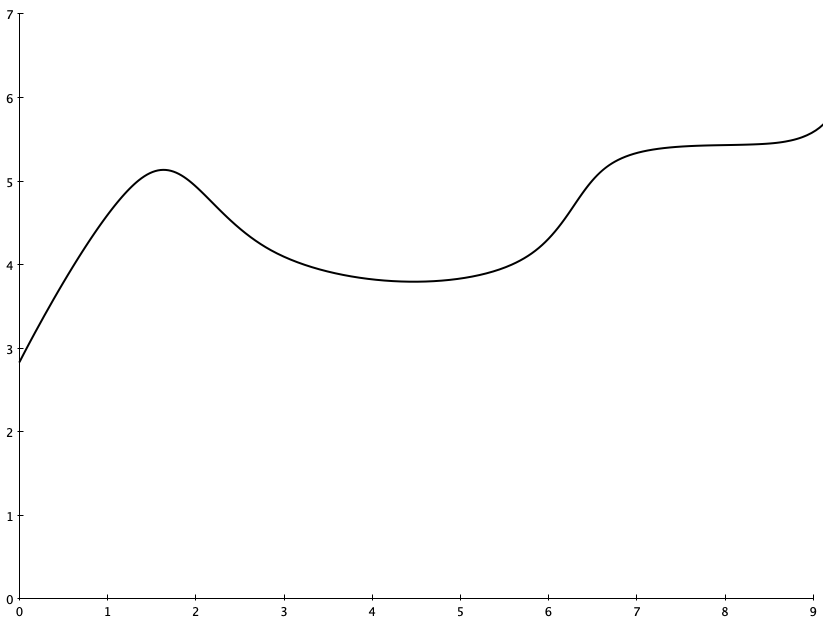
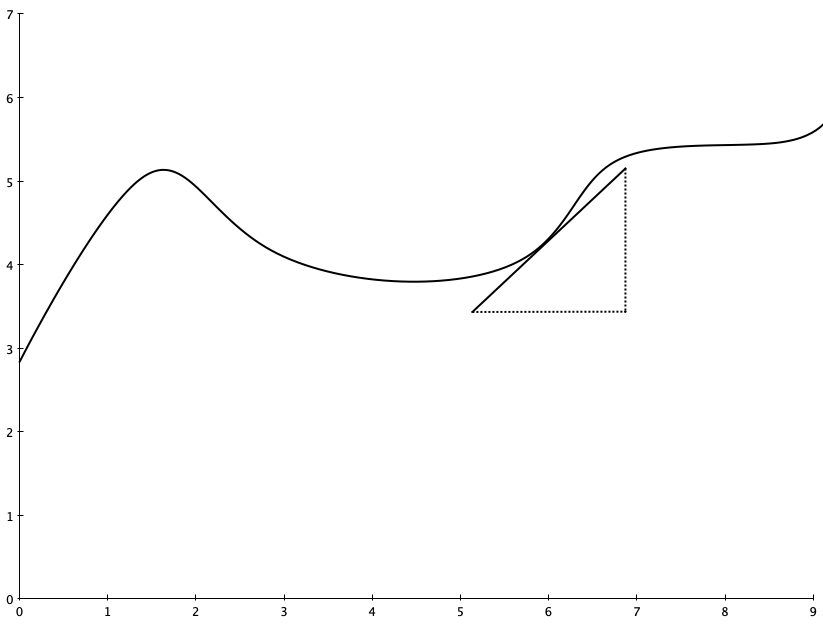
You might ask, “how quickly is this curve changing when x=6?” In other words, what is the slope of this function right in a neighborhood very close to x=6?
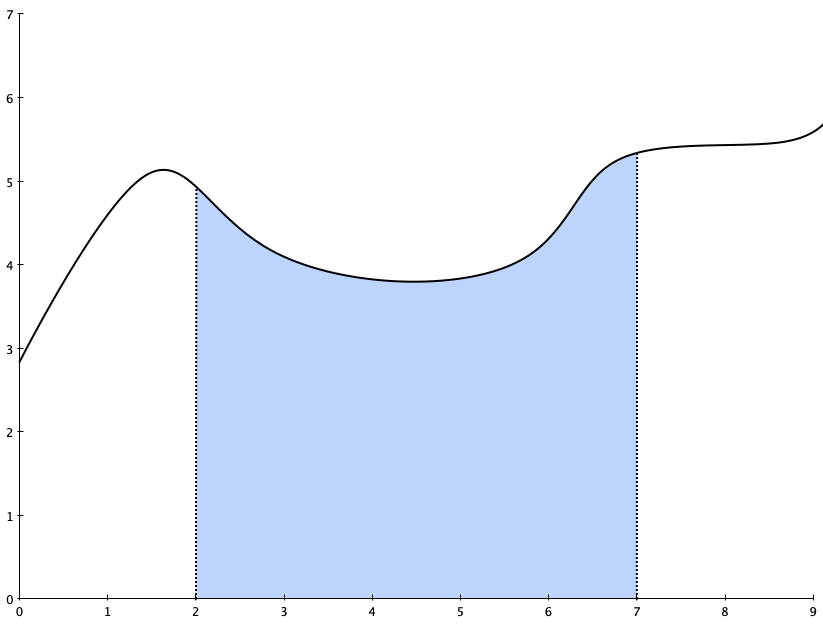
Integral calculus, on the other hand, is about the area under the graph over a particular interval. For example, you might ask “what is the area under this curve between x=2 and x=7?
If you study calculus, you’ll first be taught differential calculus (sometimes referred to “Calculus 1” or “Cal 1”) and then you’ll be taught integral calculus (“Cal 2”). When you study differential calculus, you learn the rules for calculating the derivative (slope-at-a-point) of a function. And it turns out that it’s quite straightforward to calculate a derivative, no matter what type of function it is. It’s just an algorithm, which means you can easily program a computer to compute derivatives if you wanted to. (As an aside, automatically computing derivatives is a fundamental element in the process of training LLMs. If you’re curious, look up automatic differentiation).
And then, you get to Cal 2, and you learn about how to compute an integral (area-under-a-curve). You will soon discover that, unlike in Cal 1, there is no algorithm for computing the integral of an arbitrary function. Instead, what you learn is a bag of tricks on how to compute integrals for different kinds of functions. You also learn that for some functions, there’s no closed-form solution at all for the integral! As an example, consider the Gaussian function, which shows up in the normal distribution. With zero mean and unit variance, it looks like this:
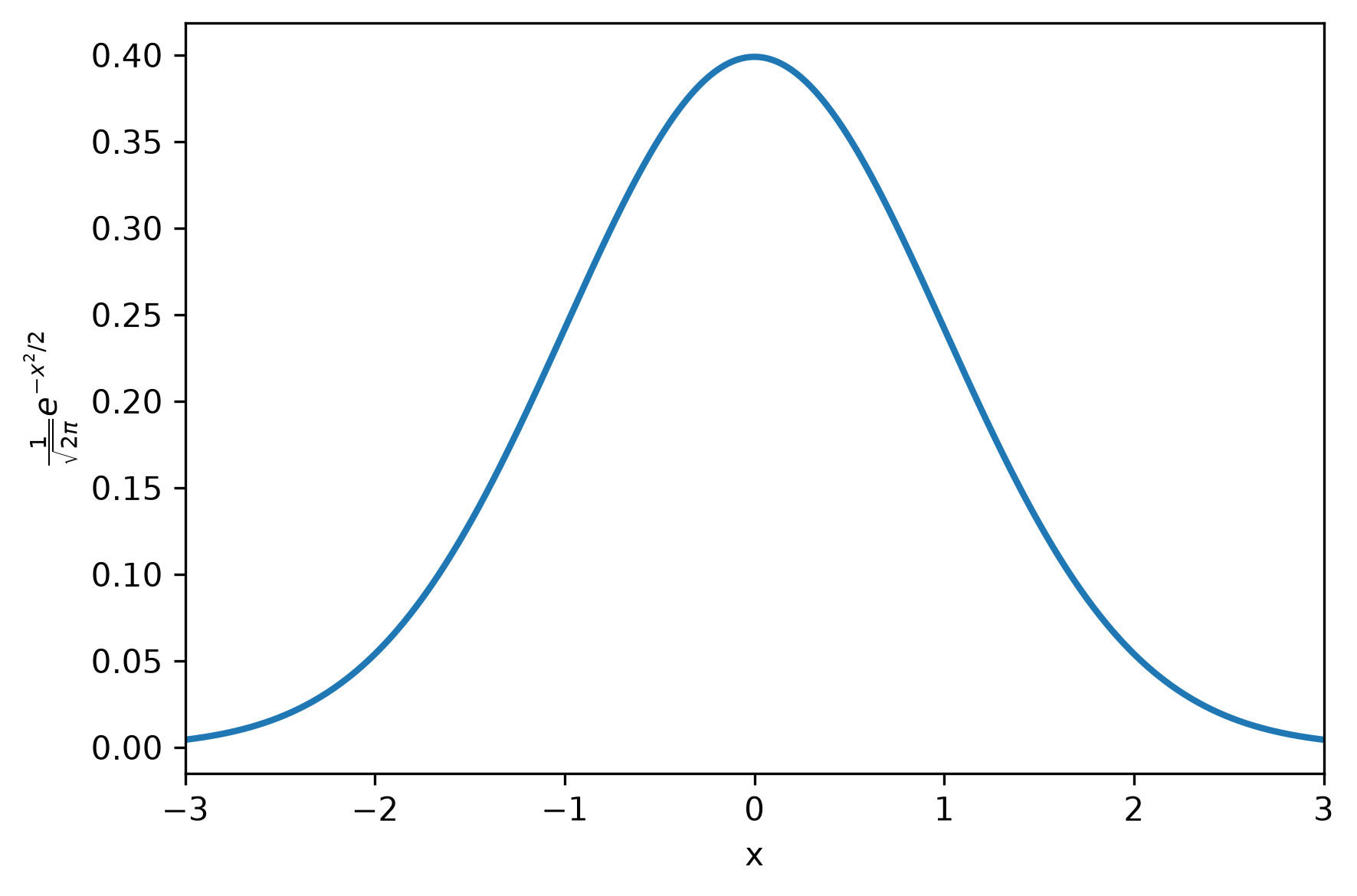
Asking students to compute the derivative of this function would be a perfectly reasonable question on a Cal 1 final exam, the answer looks like this:
But asking students to compute the integral of this function on a Cal 2 final exam would be unfair, because it’s not possible to do with the techniques they learned in class (at least, I didn’t learn the technique you’d need until Cal 3). Because the integral doesn’t have a closed-form solution, you need to express the solution as an infinite series, like:
(Note: I asked AI for the integral of the Gaussian, I hope it got it right!)
It’s not obvious (at least, not to me) that differential calculus and integral calculus are related to each other. However, it turns out that these two calculi are opposite sides of the same coin, because integrals are anti-derivatives. That is, if f(x) is the derivative of F(x), then F(x) is the integral of f(x). This result is known as the Fundamental Theorem of Calculus.
This connection between differential and integral calculus raises an almost philosophical question: why is it so much easier to compute a derivative than it is to compute an integral? Back in 2011, somebody asked about this on the Mathematics Stack Exchange: Why is integration so much harder than differentiation? The top-voted answer was written by Qiaochu Yuan, and here’s the heart of it (emphasis mine):
Differentiation is a “local” operation: to compute the derivative of a function at a point you only have to know how it behaves in a neighborhood of that point. But integration is a “global” operation: to compute the definite integral of a function in an interval you have to know how it behaves on the entire interval (and to compute the indefinite integral you have to know how it behaves on all intervals). That is a lot of information to summarize. Generally, local things are much easier than global things.
In one sense, local things are easier than global things is a banal statement. Everybody knows that, for example, local optimization is much easier than global optimization. But it’s also a very deep one. And it gets at the title of this post, which is synthesis is harder than analysis.
I previously wrote about the difference between analysis and synthesis in the demon of the gaps. In analysis, we’re breaking a larger problem into smaller problems that separate out cleanly. These smaller problems are more localized, and hence easier to solve. This is why we advocate for principles like encapsulation and separation of concerns, to ensure our smaller problems are local.
The work of synthesis involves integrating(!) multiple things together. This pushes in the other direction: we are creating a problem that is less local. And global things are much harder than local things. The challenge we face is that some kinds of problems are just inherently synthesis problems. As I wrote in that previous post, incident response is one area where we are frequently confronted with synthesis problems: we have to understand how the pieces normally fit together in order to make sense of what is currently going wrong.
That’s why I think that this sort of synthesis work is important for SREs. Now, because synthesis is harder than analysis, and because SREs don’t have super-human cognitive abilities, it means that there is a limit to how deeply they will be able to understand any given component in the system. But the more they understand how the different components interact, the better positioned they are for helping resolve the tougher incidents.
Unfortunately, in our industry we haven’t recognized building up synthesis expertise as a first-class thing. That’s understandable because this work is very situated, it depends on the messy details of the particular system in the organization that an SRE works in. On the other hand, we can get better at learning how to learn about the operational details of a system. And that’s what I’d like to see more of.




{kind=link}
{kind=link}
{kind=link}