My colleagues recently wrote a great post on the Netflix tech blog about a tough performance issue they wrestled with. They ultimately diagnosed the problem as false sharing, which is a performance problem that involves caching.
I’m going to take that post and write a simplified version of part of it here, as an exercise to help me understand what happened. After all, the best way to understand something is to try to explain it to someone else.
But note that the topic I’m writing about here is outside of my personal area of expertise, so caveat lector!
The problem: two bands of CPU performance
Here’s a graph from that post that illustrates the problem. It shows CPU utilization for different virtual machines instances (nodes) inside of a cluster. Note that all of the nodes are configured identically, including running the same application logic and taking the same traffic.

Note that there are two “bands”, a low band at around 15-20% CPU utilization, and a high band that varies a lot, from about 25%-90%.
Caching and multiple cores
Computer programs keep the data that they need in main memory. The problem with main memory is that accessing it is slow in computer time. According to this site, a CPU instruction cycle is about 400ps, and accessing main memory (DRAM access) is 50-100ns, which means it takes ~ 125 – 250 cycles. To improve performance, CPUs keep some of the memory in a faster, local cache.
There’s a tradeoff between the size of the cache and its speed, and so computer architects use a hierarchical cache design where they have multiple caches of different sizes and speeds. It was an interaction pattern with the fastest on-core cache (the L1 cache) that led to the problem described here, so that’s the cache we’ll focus on in this post.

If you’re a computer engineer designing a multi-core system where each core has on-core cache, your system has to implement a solution for the problem known as cache coherency.
Cache coherency
Imagine a multi-threaded program where each thread is running on a different core:
- thread T1 runs on CPU 1
- thread T2 runs on CPU 2
There’s a variable used by the program, which we’ll call x.
Let’s also assume that both threads have previously read x, so the memory associated with x is loaded in the caches of both. So the caches look like this:

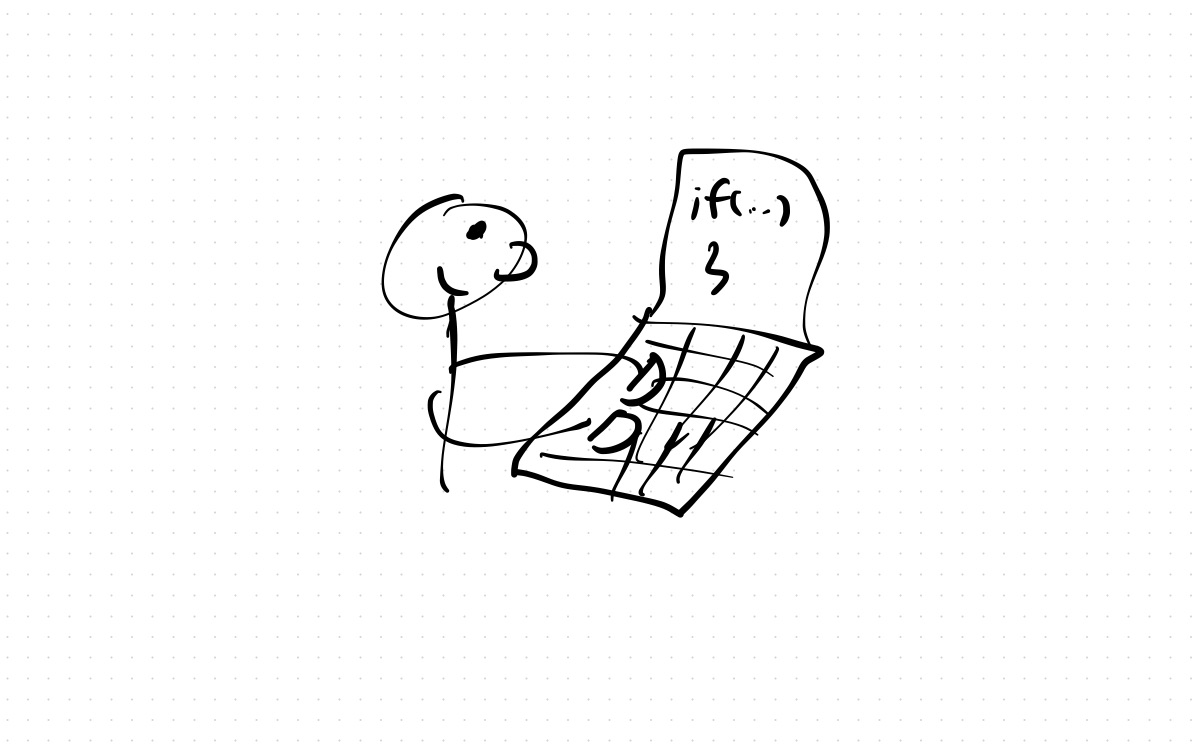
Now imagine thread T1 modifies x, and then T2 reads x.

T1 T2
-- --
x = x + 1
if(x==0) {
// shouldn't execute this!
}
The problem is that T2’s local cache has become stale, and so it reads a value that is no longer valid.
The term cache coherency refers to the problem of ensuring that local caches in a multi-core (or, more generally, distributed) system stay in sync.
This problem is solved by a hardware device called a cache controller. The cache controller can detect when values in a cache have been modified on one core, and whether another core has cached the same data. In this case, the cache controller invalidates the stale cache. In the example above, the cache controller would invalidate the cache in T2. When T2 went to read the variable x, it would have to read the data from main memory into the core.
Cache coherency ensures that the behavior is correct, but every time a cache is invalidated and the same memory has to be retrieved from main memory again, it pays the performance penalty of reading from main memory.

Data gets brought into cache in chunks
Let’s say a program needs to read data from main memory. For example, let’s say it needs to read the variable named x. Let’s assume x is implemented as a 32-bit (4 byte) integer. When the CPU reads from main memory, the memory that holds the variable x will be brought into the cache.
But the CPU won’t just read the variable x into cache. It will read a contiguous chunk of memory that includes the variable x into cache. On x86 systems, the size of this chunk is 64 bytes. This means that accessing the 4 bytes that encodes the variable x actually ends up bringing 64 bytes along for the ride.

These chunks of memory stored in the cache are referred to as cache lines.

False sharing
We now almost have enough context to explain the failure mode. Here’s a C++ code snippet from the OpenJDK repository (from src/hotspot/share/oops/klass.hpp)
class Klass : public Metadata {
...
// Cache of last observed secondary supertype
Klass* _secondary_super_cache;
// Array of all secondary supertypes
Array<Klass*>* _secondary_supers;This declares two pointer variables inside of the Klass class: _secondary_super_cache, and _secondary_supers. Because these two variables are declared one after the other, they will get laid out next to each other in memory.

The _secondary_super_cache is, itself, a cache. It’s a very small cache, one that holds a single value. It’s used in a code path for dynamically checking if a particular Java class is a subtype of another class. This code path isn’t commonly used, but it does happen for programs that dynamically create classes at runtime.
Now imagine the following scenario:
- There are two threads: T1 on CPU 1, T2 on CPU 2
- T1 wants to write the _secondary_super_cache variable and already has the memory associated with the _secondary_super_cache variable loaded in its L1 cache
- T2 wants to read from the _secondary_supers variable and already has the memory associated with the _secondary_supers variable loaded in its L1 cache.
When T1 (CPU 1) writes to _secondary_super_cache, if CPU 2 has the same block of memory loaded in its cache, then the cache controller will invalidate that cache line in CPU 2.
But if that cache line contained the _secondary_supers variable, then CPU 2 will have to reload that data from memory to do its read, which is slow.

This phenomenon, where the cache controller invalidates cached non-stale data that a core needed to access, which just so happens to be on the same cache line as stale data, is called false sharing.
What’s the probability of false sharing in this scenario?
In this case, the two variables are both pointers. On this particular CPU architecture, pointers are 64-bits, or 8 bytes. The L1 cache line size is 64 bytes. That means a cache line can store 8 pointers. Or, put another away, a pointer can occupy one of 8 positions in the cache line.
There’s only one scenario where the two variables don’t end up on the same cache line: when _secondary_super_cache occupies position 8, and _secondary_supers occupies position 1. In all of the other scenarios, the two variables will occupy the same cache line, and hence will be vulnerable to false sharing.
1 / 8 = 12.5%, and that’s roughly the number of nodes that were observed in the low band in this scenario.

And now I recommend you take another look at the original blog post, which has a lot more details, including how they solved this problem, as well as a new problem that emerged once they fixed this one.