(With apologies to Alan Sokal)
Boundary according to Rasmussen
Jens Rasmussen was a giant in the field of safety science research. You can see still his influence on the field, in the writings of safety researchers such as Sidney Dekker, Nancy Leveson, and David Woods.
One of Rasmussen’s most famous papers is Risk management in a dynamic society: a modelling problem. In that paper, Rasmussen proposed a model of system safety illustrated by the following diagram:
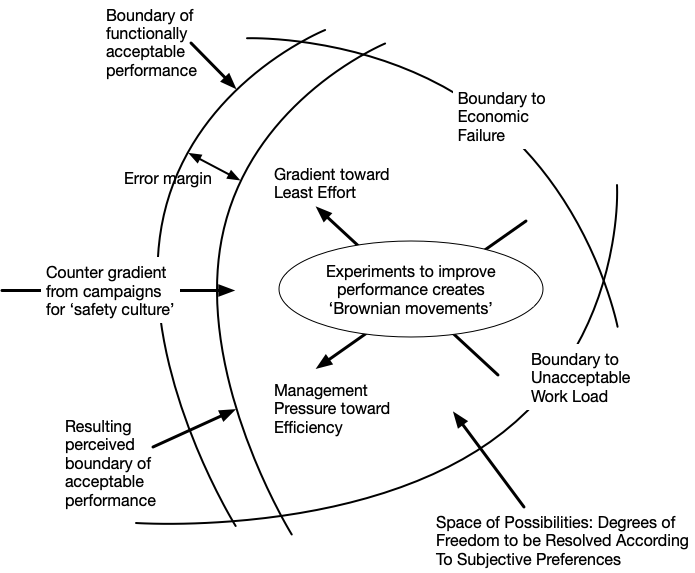
This model looks like it views the state of the system as a point in a state space. But, Rasmussen described it as a model of the humans working within the system. He used the term “work space” rather than “state space”. In addition, Rasmussen used the metaphor of a gas particle undergoing local random movements, a phenomenon known as Brownian motion.
Along with the random movements, Rasmussen saw envisioned different forces (he called them gradients) that influenced how the work system would move within the work space. One of these forces was pressure from management to get more work done in order to make the company more profitable. Woods refers to this phenomenon as “faster/better/cheaper pressure“. This is the arrow labeled Management Pressure toward Efficiency, which pushes away from the Boundary to Economic Failure.
One way to get more work done is to give people increasing loads of work. But people don’t like having more and more work piled on them, and so there is opposing pressure from the workforce to reduce the amount of work they have to do. This is the arrow labeled Gradient toward Least Effort which pushes away from the Boundary to Unacceptable Work Load.
The result of those two pressures is movement towards what the diagram labels “the Boundary of functionally acceptable performance”. This is the safety boundary, and we don’t know exactly where it is, which is why there’s a second boundary in the diagram labelled “Resulting perceived boundary of acceptable performance.” Accidents happen when we cross the safety boundary.
Boundary according to Woods
In David Woods’s work, he also writes about the role of boundaries in system safety, but despite this surface similarity, his model isn’t the same as Rasmussen’s.
Instead of a work space, Woods refers to an envelope. He uses terms like competence envelope or design envelope or envelope of performance. Woods has done safety research in aviation, and so I suspect he was influenced by the concept of a flight envelope in aircraft design.
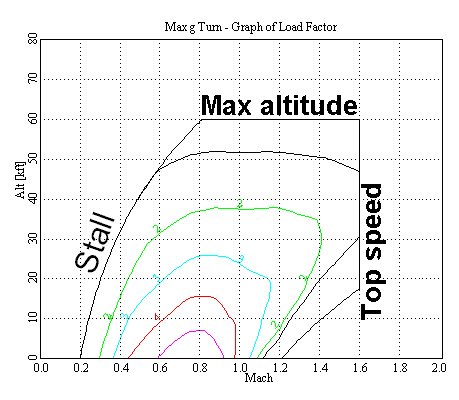
The flight envelope defines a region in a state space that the aircraft is designed to function properly within. You can see in the diagram above that the envelope’s boundaries are defined by the stall speed, top speed, and maximum altitude. Bad things happen if you try to operate an aircraft outside of the envelope (hence the phrase pushing the envelope).
Woods’s competence envelope is a generalization of the idea of flight envelope to other types of systems. Any system has a range of inputs that it can handle: if you go outside that range, bad things happen.
Summarizing the differences
To Rasmussen, there is only one boundary in the work space related to accidents: the safety boundary. The other boundaries in the space generally aren’t even reachable, because of the natural pressure away from them. To Woods, the competence envelope is defined by multiple boundaries, and crossing any of them can result in an accident.
Both Rasmussen and Woods identified the role of faster/better/cheaper pressure in accidents. To Rasmussen, this pressure resulted in pushing the system to the safety boundary. But to Woods, this pressure changes the behavior at the boundary. Woods sees this pressure as contributing to brittleness, to systems that don’t perform well as they get close to the boundary of the performance envelope. Woods’s current work focuses on how systems can avoid being brittle by having the ability of moving the boundary as they get closer to it: expanding the competence envelope. He calls this graceful extensibility.
