Yesterday, Verizon experienced a major outage. The company hasn’t released any details about how the outage happened yet, so there’s no quick takes to be had. And I have no personal experience in the telecom industry, and I’m not a network engineer, so I can’t even make any as-an-expert commentary, because I’m not nan expert. But I still thought it would be fun to make predictions about what the public write-up will reveal. I can promise that all of these predictions are free of hindsight bias!
Maintenance
On Bluesky, I predicted this incident involved planned maintenance, because the last four major telecom outages I read about all involved planned maintenance. The one foremost on my mind was the Optus emergency services outage that happened back in September in Australia, where the engineers were doing software upgrades on firewalls
Work was being done to install a firewall upgrade at the Regency Park exchange in SA.
There is nothing unusual about such upgrades in a network and this was part of a planned
program, spread over six months, to upgrade eighteen firewalls. At the time this specific
project started, fifteen of the eighteen upgrades had been successfully completed. – Independent Report – The Triple Zero Outage at Optus: 18 September 2025.
The one before that was the Rogers internet outage that happened in my Canada back in July 2022.
In the weeks leading to the day of the outage on 8 July 2022, Rogers was executing on a seven-phase process to upgrade its IP core network. The outage occurred during the sixth phase of this upgrade process. – Assessment of Rogers Networks for Resiliency and Reliability Following the 8 July 2022 Outage – Executive Summary
There was also a major AT&T outage in 2024. From the FCC report:
On Thursday, February 22, 2024, at 2:42 AM, an AT&T Mobility employee placed a new network element into its production network during a routine night maintenance window in order to expand network functionality and capacity. The network element was misconfigured. – February 22, 2024 AT&T Mobility Network Outage REPORT AND FINDINGS
Verizon also suffered from a network outage back in September 30, 2024. Although the FCC acknowledged the outage, I couldn’t find any information from either Verizon or the FCC about the incident. The only information I was able to find about that outage comes from, of all places, a Reddit post. And it also mentions… planned maintenance!

So, we’re four for four on planned maintenance being in the mix.
I’m very happy that I did not pursue a career in network engineering: just given that the blast radius of networking changes can be very large, by the very nature of networks. It’s the ultimate example of “nobody notices your work when you do it well, they only become aware of your existence when something goes wrong. And, boy, can stuff go wrong!”
To me, networks is one of those “I can’t believe we don’t have even more outages” domains. Because, while I don’t work in this domain, I’m pretty confident that planned maintenance happens all of the time.
Saturation
The Rogers and AT&T outages involved saturation. From the Rogers executive summary (emphasis added), which I quoted in my original blog post
Rogers staff removed the Access Control List policy filter from the configuration of the distribution routers. This consequently resulted in a flood of IP routing information into the core network routers, which triggered the outage. The flood of IP routing data from the distribution routers into the core routers exceeded their capacity to process the information. The core routers crashed within minutes from the time the policy filter was removed from the distribution routers configuration. When the core network routers crashed, user traffic could no longer be routed to the appropriate destination. Consequently, services such as mobile, home phone, Internet, business wireline connectivity, and 9-1-1 calling ceased functioning.
From the FCC report on the AT&T outage:
Restoring service to commercial and residential users took several more hours as AT&T Mobility continued to observe congestion as high volumes of AT&T Mobility user devices attempted to register on the AT&T Mobility network. This forced some devices to revert back to SOS mode. For the next several hours, AT&T Mobility engineers engaged in additional actions, such as turning off access to congested systems and performing reboots to mitigate registration delays.
Saturation is such a common failure pattern in large-scale complex systems failures. We see it again and again, so often that I’m more surprised when it doesn’t show up. It might be that saturation contributed to a failure cascade, or that saturation made it more difficult to recover, but I’m predicting it’s in there somewhere.
“Somebody screwed up”
Here’s my pinned Bluesky post:
I’m going to predict that this incident will be attributed to engineers that didn’t comply with documented procedure for making the change, the kind of classic “root cause: human error” kind of stuff.
I was very critical of the Optus outage independent report for language like this:
These mistakes can only be explained by a lack of care about a critical service and a lack of disciplined adherence to procedure. Processes and controls were in place, but the correct process was not followed and actions to implement the controls were not done or not done properly.
The FCC report on the AT&T outage also makes reference to not following procedure (emphasis mine)
The Bureau finds that the extensive scope and duration of this outage was the result of
several factors, all attributable to AT&T Mobility, including a configuration error, a lack of adherence to AT&T Mobility’s internal procedures, a lack of peer review, a failure to adequately test after installation, inadequate laboratory testing, insufficient safeguards and controls to ensure approval of changes affecting the core network, a lack of controls to mitigate the effects of the outage once it began, and a variety of system issues that prolonged the outage once the configuration error had been remedied.
The Rogers independent report, to its credit, does not blame the operators for the outage. So I’m generalizing from only two data points for this prediction. I will be very happy if I’m wrong.
“Poor risk management”
This one isn’t a prediction, just an observation of a common element of two of the reports: criticizing the risk assessment of the change that triggered the incident. Here’s Optus report (emphasis in the original):
Risk was classified as ‘no impact’, meaning that there was to be no impact on network traffic, and the firewall upgrade was classified as urgent. This was the fifth mistake.
Similarly, the Rogers outage independent report blames the engineers for misclassifying the risk of the change:
Rogers classified the overall process – of which the policy filter configuration is only one of many parts – as “high risk”. However, as some earlier parts of the process were completed successfully, the risk level was reduced to “low”. This is an oversight in risk management as it took no consideration of the high-risk associated with BGP policy changes that had been implemented at the edge and affected the core.
…
Rogers had assessed the risk for the initial change of this seven-phased process as “High”. Subsequent changes in the series were listed as “Medium.” [redacted] was “Low” risk based on the Rogers algorithm that weighs prior success into the risk assessment value. Thus, the risk value for [redacted] was reduced to “Low” based on successful completion of prior changes.
The risk assessment rated as “Low” is not aligned with industry best practices for routing protocol configuration changes, especially when it is related to BGP routes distribution into the OSPF protocol in the IP core network. Such a configuration change should be considered as high risk and tested in the laboratory before deployment in the production network.
Unfortunately, it’s a lot easier to state”you clearly misjudged the risk!” then to ask “how did it make sense in the moment to assess the risk as low?”, and, hence, we learn nothing about how those judgments came to be.
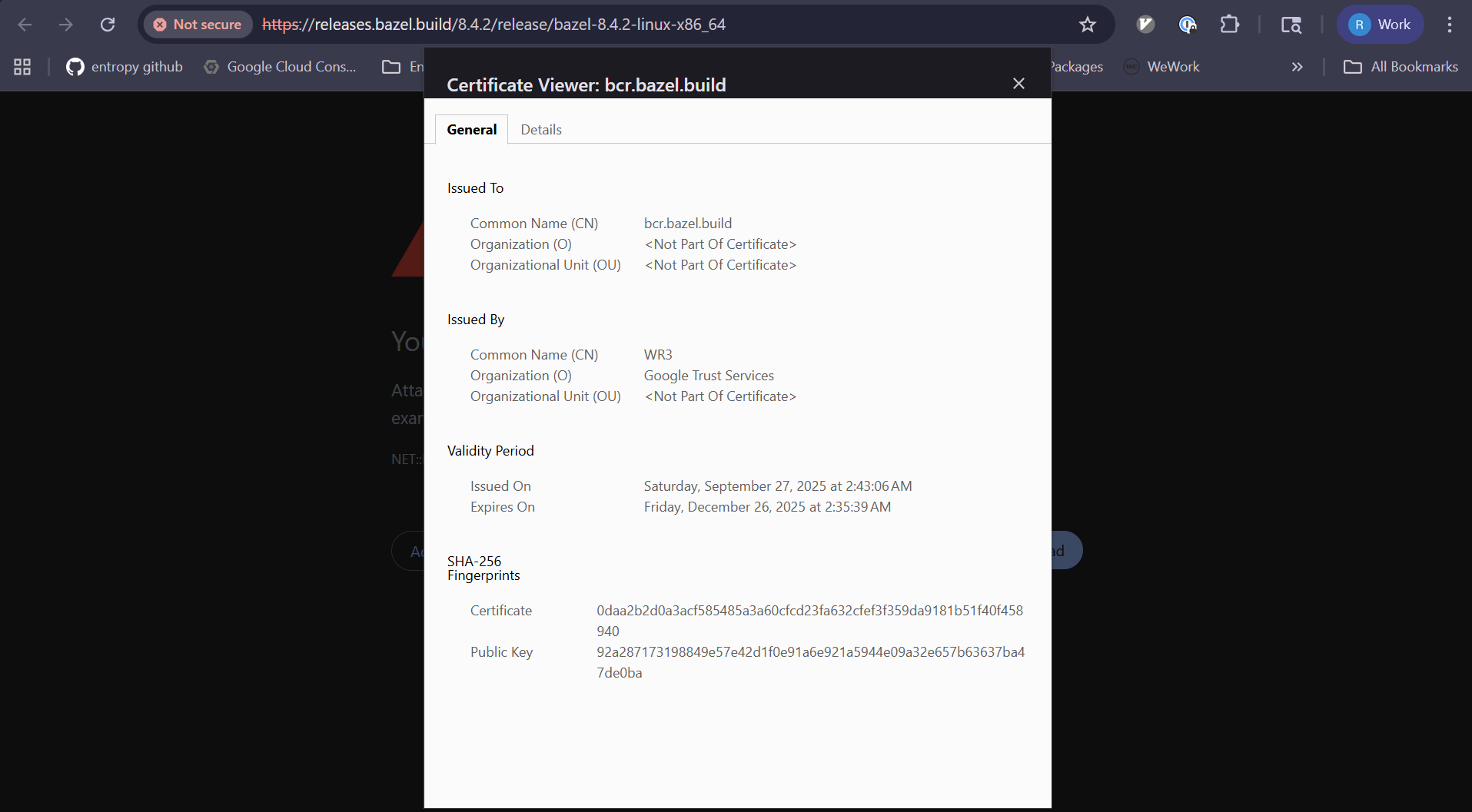
I’m anxiously waiting to hear any more details about what happened. However, given that neither Verizon nor the FCC released any public information from the last outage, I’m not getting my hopes up.