My SREcon talk is now up.
Life comes at you fast
Now, here, you see, it takes all the running you can do, to keep in the same place. – Lewis Carroll, Through the Looking-Glass, and What Alice Found There
LLM coding may be revolutionizing software development productivity, but it doesn’t seem to be generating the same sorts of gains in software reliability yet. Two events that caught my eye today, although only one is directly related to LLMs.
The first event was that Anthropic suffered from another incident today, which lasted about an hour and a half.
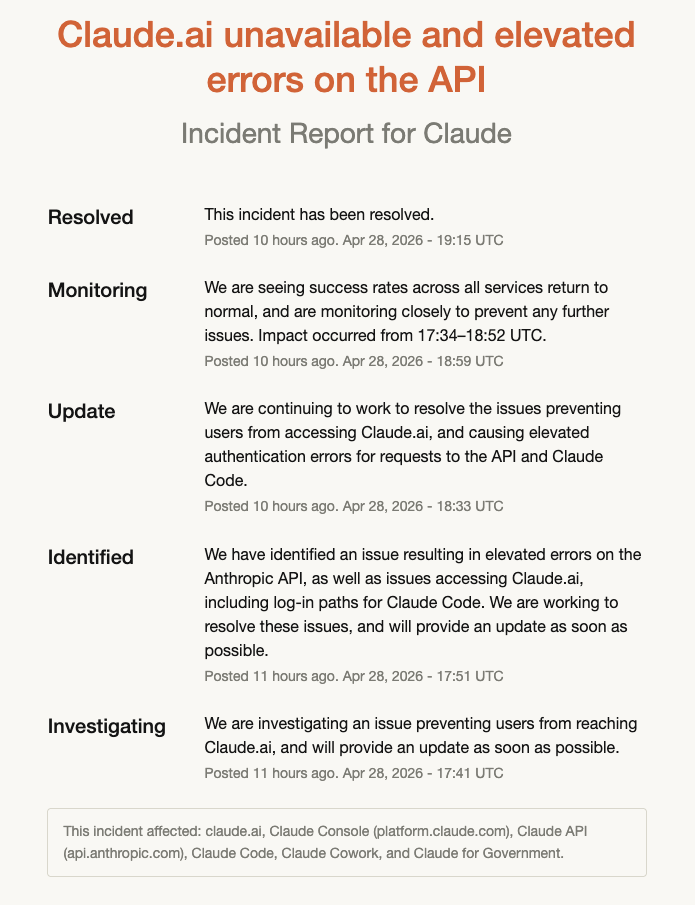
This brought Claude Code down to one nine over the past 60 days, although they’re at two nines if you look over 90 days. I know, I know, I shouldn’t even talk about the nines, but they do make for a great screenshot.
The second event, the one I really want to focus in here, was GitHub’s CTO Vlad Fedorov writing the blog post: An update on GitHub availability. It was only six weeks ago that he wrote Addressing GitHub’s recent availability issues, which is clearly a sign that GitHub is concerned about the impact of recent incidents on their brand.
I want talk about GitHub’s post in the context of David Woods’s Messy 9 collection of patterns about complex systems. I’ve mentioned them before, but to re-iterate, they are: congestion, cascades, conflicts, saturation, lag, friction, tempos, surprises, tangles.
Fedorov notes that AI is driving a lot more activity on the site: the counts of pull requests, commits, repos are growing like never before.
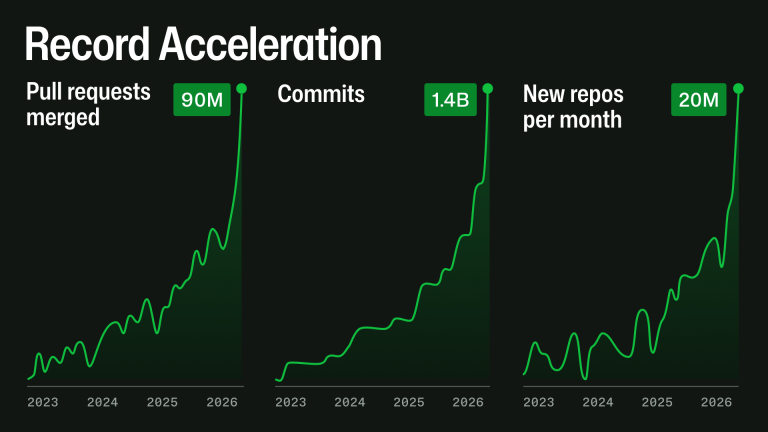
This is a great example of an increase in tempo: the environment that GitHub exists within is changing faster than it has previously. Heck, it’s right there in the title of that graphic: “Record Acceleration”. In particular, the load on GitHub as a system has increased significantly, and GitHub is struggling to keep up with this load. It puts GitHub at risk of saturation.
This exponential growth does not stress one system at a time. A pull request can touch Git storage, mergeability checks, branch protection, GitHub Actions, search, notifications, permissions, webhooks, APIs, background jobs, caches, and databases. At high scale, small inefficiencies compound: queues deepen, cache misses become database load, indexes fall behind, retries amplify traffic, and one slow dependency can affect several product experiences.
GitHub has to make changes to its internal systems in order to handle this load. I don’t work at GitHub, so I don’t know the details, but I have high confidence that they can’t simply horizontally scale their way out of the problem. They will likely have to rearchitect parts of their system in order to handle the increased load. And that will take time, even in the age of AI. And this is where the lags come in. It takes time to actually implement long-term solutions that can handle the load, which increases the probability of short-term outages since the system is running too close to the margin, and those outages delay the long-term solution work because the short-term firefighting steals engineering cycles, and so on. It’s a dangerous place to be, and I don’t envy them.
(As an aside, one other aspect of Fedorov’s post that I found interesting was how the increasing popularity of monorepos is also putting additional stress on GitHub as a system. People are using them in ways that designers had not envisioned!)
I don’t know whether Anthropic will reveal any details about the nature of their most recent outage, but as I’ve written about previously, the author of Claude Code mentioned on Twitter that Anthropic’s availability issues are related to unexpectedly rapid increases in demand. They are victims of their own success.
One of the reasons I don’t expect AI to improve reliability is that I don’t think LLMs are well-suited to mitigate the risk of saturation. As GitHub demonstrates, LLMs are more likely to be on the supply side when it comes to risk of saturation.
The normal work of creating reliability
Here’s a recent comment on LinkedIn from John Allspaw, on a post by Gandhi Mathi Nathan Kumar about availability.
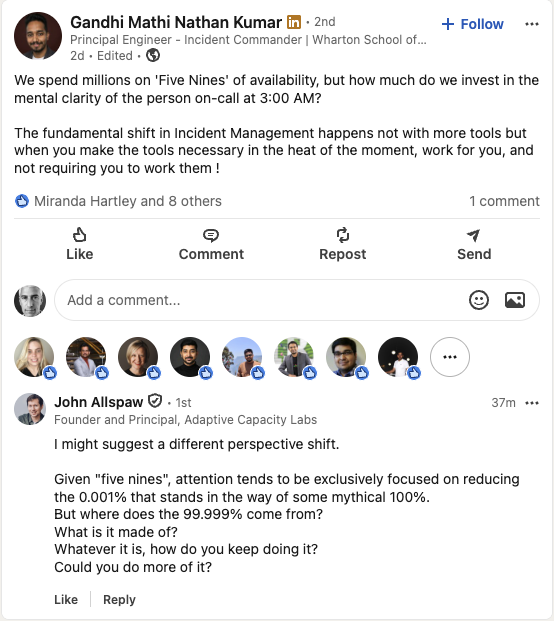
Allspaw’s comment is a succinct description of a safety model proposed by the Danish resilience engineering researcher Erik Hollnagel: Safety-II. Hollnagel has described Safety-II in his book Safety-I and Safety-II: The Past and Future of Safety Management, as well as in white papers aimed at aviation and medical audiences. The book and white papers are all quite approachable, and I recommend checking them out.
Hollnagel’s observation is simultaneously trite and surprising: most of the time our systems are succeeding; incidents are the exception, not the norm. After all, this is why we measure availability in nines. The traditional approach to safety, what Hollnagel calls Safety-I, is to try to reduce the bad stuff, the work that leads to incidents. Hollnagel asks us to think about things differently: what if, instead, we focused on cultivating the good stuff: the everyday work that is consistently preventing accidents? There’s a lot more good stuff happening than bad stuff! Or, as my former colleague Ryan Kitchens put it, instead of asking why do things go wrong, it’s more productive to ask how do things go right?
In Hollnagel’s Safety-II model, the normal work that people in your organization do everyday is actively creating safety. Or, as the American organizational psychologist Karl Weick put it in his 1987 paper Organizational culture as a source of high reliability, reliability is a dynamic non-event. That is, the work is explicitly positive, and by the nature of this work, people are constantly doing work that is preventing incidents from happening. However, this work isn’t able to prevent all incidents, which is why they still happen. But taking Safety-II seriously means trying to understand how it is that normal work prevented previous incidents, rather than just trying to understand how it failed to prevent the last one. In Hollnagel’s words, the purpose of an investigation is to understand how things usually go right as a basis for explaining how things occasionally go wrong.
Focusing on the scenarios where things go right is a radical reframing of the problem, so much so that it is a genuinely strange idea, something that violates our intuitions about how systems break. We operate under a baseline, unspoken assumption that reliability is a passive thing, that the default behavior of a system is to stay up, and that somebody needs to actively do something wrong in order to cause the system to break. In other words, we view the day-to-day work people in the system do as a potential threat to reliability. And then, when an incident happens, we try to identify the bad work that broke the system.
If we were to take Safety-II seriously, we’d have to focus on how people adapt their work. It means seeing that people change how they do their work based on the pressures that they are currently facing and the constraints that they are under. More importantly, it means that we have to acknowledge that these adaptations are usually successful. If you only look at these adaptation within the context of an incident, and try to improve reliability by preventing these adaptations, it’s like believing you can figure out how to win the lottery by examining the behaviors of lottery winners. Sure, you can identify patterns among the behavior of lottery winners. But there are even more folks who lose the lottery who exhibit those behaviors, you’re just not looking at those. Note, though, how much this goes against the way people think about how incidents happen.
Safety-II is also challenging to adopt because organizations are simply not used to studying the normal work that goes on in an organization in order to answer the question, “what work is going particularly well, and how can we do more of it?” The closest we probably get is shadowing that happens when new employees join. We do have developer experience surveys, but those focus specifically on problems with existing tooling. I don’t know of any reliability organization at any tech company out there that takes a Safety-II approach and spends time understanding what’s happening when it looks like there’s nothing happening. Perhaps they’re out there, but if they are, they aren’t writing about this work. The one exception to this is the resilience in software folks, but even with us, we’re generally focused on shifting the emphasis of post-incident examination of work, rather than examining work outside of the context of incidents.
Now, attention is a limited resource in an organization, and incidents win the attention of an organization because they are troubling by their nature. Because attention is limited, if all the indicators are currently green, that’s taken as a sign that we can safely spend our attention budget elsewhere. In the tech industry, we also don’t have great models for how to study normal work within an organization, because nobody seems to be doing it. Or, if they are, they aren’t writing about it. In his Safety-II book, Hollnagel recommends doing interviews and field observations. In tech, field observations are trickier because the majority of our work is effectively invisible; we do our work alone at a computer. We can observe interactions over channels like Slack and Zoom, but that’s only part of the story. I suspect that interviews are our best potential source of information here. And then we need to take what we’ve learned from the interviews and use those insights to improve reliability by amplifying what’s already working well. That’s not something we have experience with.
It’s no surprise, then, that Safety-II hasn’t caught on our field. It cuts against our intuitions about the nature of complex systems failure, and we don’t have good public examples to work from about this. We resilience in software folks are trying to push the industry in this direction with trying to get people to think differently about what we can get out of incident analysis, and that’s probably our best bet right now. But we have a long way to go.
Thoughts on the Bluesky public incident write-up
Back on April 4, the social media site Bluesky suffered a pretty big outage. I was delighted to discover that one of their engineers, Jim Calabro, published a public writeup about it: April 2026 Outage Post-Mortem.
Calabro’s post goes into a lot of technical details about the failure mode. I’m using this post as a learning exercise for myself. I find that if I have to explain something, then I’ll understand it better. After reading his post and writing this one, I learned things about ephemeral ports, goroutine groups, the TCP state machine, the interaction between blocking system calls and the creation of threads in the Go runtime, and the range of loopback addresses on Linux.
Interpreting the error message
The first thing that struck me is Calabro’s write-up was his discussion of a particular error message he saw in the logs:
dial tcp 127.32.0.1:0->127.0.0.1:11211: bind: address already in use
Now, if I was the one who saw the error message “bind: address already in use”, I would have assumed that a process was trying to listen on a port that another process was already listening on. This sort of thing is server-side behavior, where a server listens on a port (e.g., web servers listen on port 80 and port 443). In the connect attempt associated with the log, the server is listening on port 11211 (the standard port used by memcached). As it says on the Linux bind man page:
EADDRINUSE
The given address is already in use.
But that wasn’t the problem in this case! It wasn’t an issue with a server trying and failing to listen on port 11211. Instead, the problem is that the client, which is trying to make a connection to the memcached service, is failing to associate a socket with a port. The system call that’s failing is not listen but (as indicated in the error message) bind. That bind man page actually has two different entries for the address already in use error. Here’s the second one:
EADDRINUSE
(Internet domain sockets) The port number was specified as
zero in the socket address structure, but, upon attempting
to bind to an ephemeral port, it was determined that all
port numbers in the ephemeral port range are currently in
use. See the discussion of
/proc/sys/net/ipv4/ ip_local_port_range ip(7).
I assume that go’s net.Dial function ultimately calls this private dial function, which will call bind if the caller explicitly specifies the local address. In the log message above, the local address was 127.32.0.1:0.
This code was failing because there were no available ephemeral ports left!
I bring this up because Calabro simply mentions as an aside how he (correctly!) interpreted the error message. He just shows the error, and then writes (emphasis mine):
The timing of these log spikes lined up with drops in user-facing traffic, which makes sense. Our data plane heavily uses memcached to keep load off our main Scylla database, and if we’re exhausting ports, that’s a huge problem.
That’s expertise in action!
Saturation, part 1: ephemeral ports
The failure mode that Bluesky encountered is a classic example of saturation, where the system runs out of a critical resource. Calabro’s write-up covers two different time periods, a paging alert on Saturday April 4, and then the Bluesky outage that happened two days later, on Monday April 6. There were different flavors of saturation on the different days, here we’ll talk about the first one.
On Saturday, the limited resource in question was the number of available ephemeral ports. From a programming perspective, when we make calls to servers, we don’t think about the fact that our side of a TCP connection gets assigned a port, because this TCP detail is effectively abstracted away from the developer.
I’m running on macOS, but if I launch an Ubuntu Docker container, I can see that the ephemeral port range goes from 32768 to 60999, for a count of 28,232 available ephemeral ports:
$ sysctl net.ipv4.ip_local_port_rangenet.ipv4.ip_local_port_range = 32768 60999
The irony here is that the connections that exhausted the ephemeral ports were to a process that’s running on the same host: memcached listening on 127.0.0.1:11211.
Calabro goes into considerable detail about how the service they refer to as the data plane ran out of ephemeral ports. I’ll describe my understanding based on his write-up. But, as always, I recommend you read the original.
The data plane service talks to a database that is fronted by memcached. This incident only involved interactions between data plane and memcached, so I don’t show the database in the diagram below.
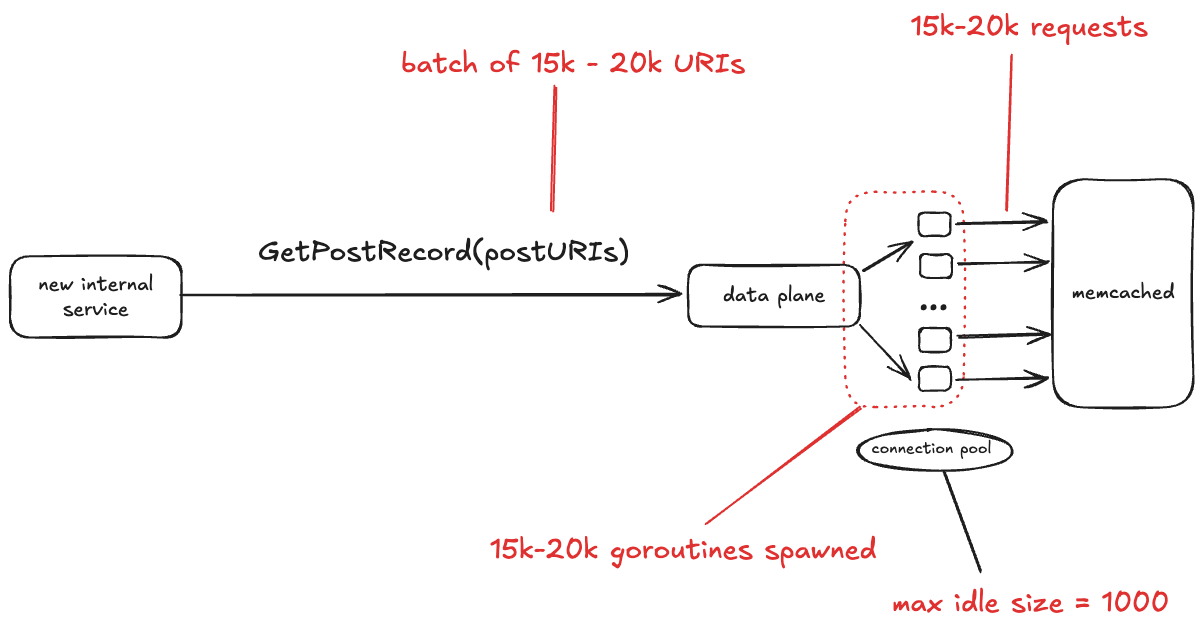
Bluesky recently brought up a new internal service. One of the things this service does is make the GetPostRecord RPC call against the data plane service. The problem isn’t with the rate of traffic. In fact, the volume of traffic that this internal service sends to data plane is low, less than 3 RPS.
No, the problem here is the size of the GetPostRecord payload. It sends a batch of URIs in each call, and sometimes those batches are very large, on the order of 15-20 thousand URIs.
The data plane looks up each URI in memcache first before hitting the database. The data plane is written in Go, and for each request, it starts a new goroutine, and each of those goroutines creates a new TCP connection to memcache. All of those goroutines concurrently making those TCP connections depleted the set of available ephemeral ports.
One thing I learned from this write-up is that Go has a notion of goroutine groups, you can explicitly set a limit of the number of goroutines that are active within a given group. Tragically, this was the one data plane endpoint that was missing an explicit limit.
The connection pool
In the write-up, Calabro notes that the memcached client uses a connection pool, with a maximum idle size of 1000 connections. I was initially confused by this, because I’m used to connection pools where the pool defines the maximum number of simultaneous active connections, and if no unused connections are available, then the client blocks waiting for a connection to be available.
I looked into this, and assuming that this app is using the gomemcache library, that’s not how its connection pool works. Instead, the gomemcache code first looks to see if there’s an available connection. If not, it creates a new connection. So, the connection pool here doesn’t bound connections, but rather is an optimization to reuse an existing connection if one is available.
Instead, what you specify with gomemcache is the maximum number of idle connections, which is the maximum number of connections that the pool will hold onto after use. As mentioned above, Bluesky had this configured as 1,000. This means that if there are 15,000 new connections requested concurrently, at best 1,000 connections will be reused from the pool, requiring 14,000 new connections to be established.
Bitten by time lags – TIME_WAIT
Time lags are underrated factor in incidents, and time lag plays a role here. In this case, the time lag is due to a state in the lifetime of a TCP socket called TIME_WAIT. This state renders a port unusable for a fixed period of time after a connection associated with the port has been closed.
Personally, I first encountered TIME_WAIT back when I was working on a web app on my laptop. Sometimes I’d kill the process and restart it, and the restart would fail with the error that the port it was trying to listen on was already in use. It turns out that the operating system does not immediately release the ports associated with a socket after it’s closed. Instead, the connection transitions to the TIME_WAIT state.
Here’s an explanation for why TIME_WAIT exists, based largely on the excellent article: TIME_WAIT and its design implications for protocols and scalable client server systems from ServerFramework.com.
The dropped ACK problem: sending an error when nothing is wrong
Closing a TCP requires each send side to send a FIN, and each side to ACK the received FIN. As each side sends or receives one of these packets, it transitions through the TCP state machine. Here’s what the exchange looks like. I’ve annotated the TCP states on the server side and the client side.
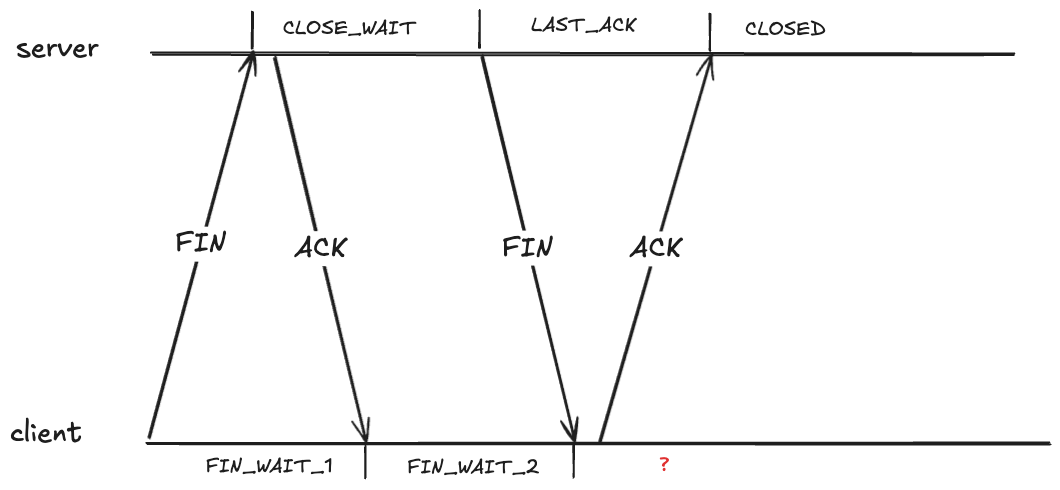
It looks like the client should also be in the CLOSED state after it receives the FIN. However, that creates a problem if the ACK it sends never makes it, because the server will eventually retry sending the FIN.
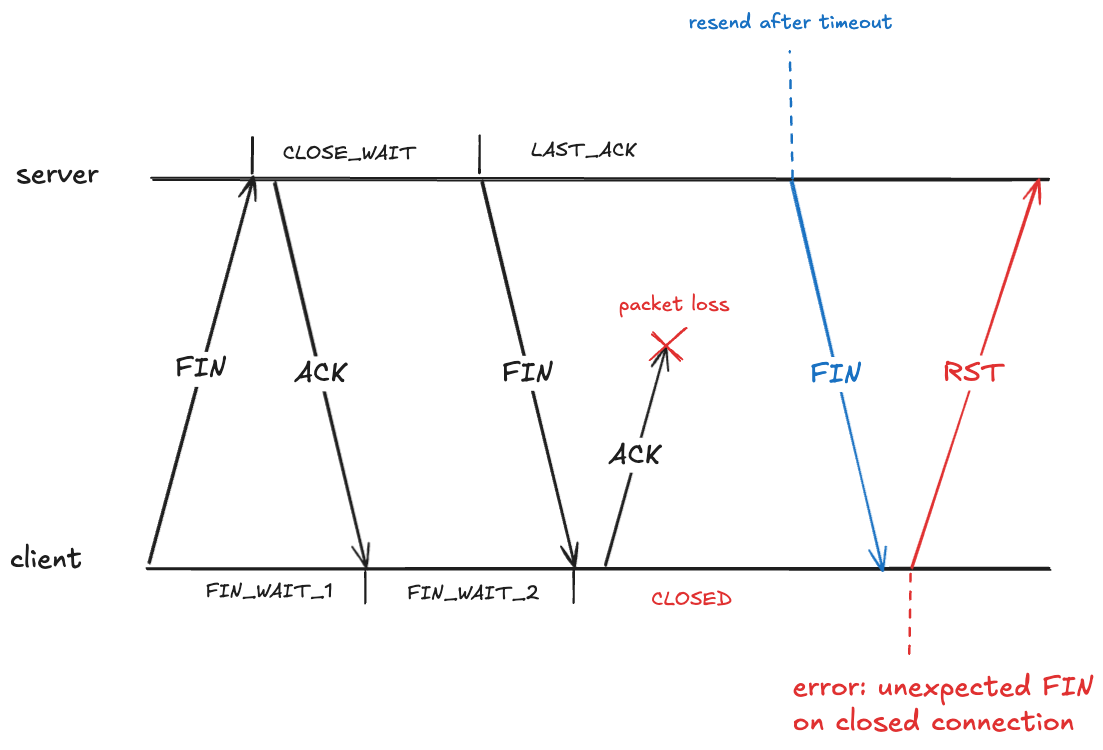
Here the client has received a packet associated with a TCP connection that has transitioned to the CLOSED state. The client will treat this as an error, and will send an RST packet (if you’ve ever seen the message: connection reset by peer, you’ve been on the receiving end of an RST packet).
To prevent this, after sending an ACK in the FIN_WAIT_2, the client transitions into the TIME_WAIT state. From RFC-9293:
When a connection is closed actively, it MUST linger in the TIME-WAIT state for a time 2xMSL (Maximum Segment Lifetime)
The RFC doesn’t define what the maximum segment lifetime is. On Linux, the kernel waits in the TIME_WAIT state for about 60 seconds.
#define TCP_TIMEWAIT_LEN (60*HZ) /* how long to wait to destroy TIME-WAIT * state, about 60 seconds */
This means that the state of the TCP connection will be in the TIME_WAIT state for about a minute before transitioning to CLOSED:
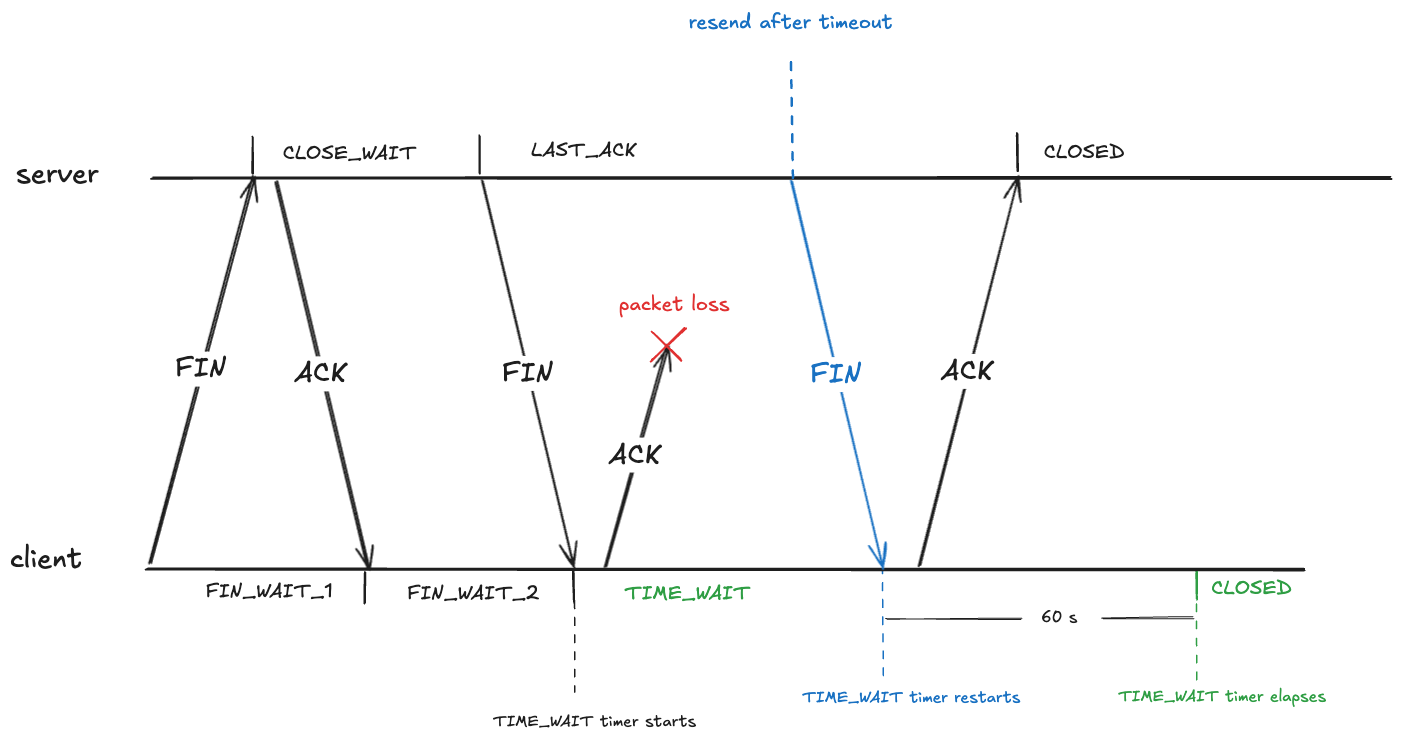
The out of order problem: packet associated with wrong connection
TIME_WAIT also deals with a problem related to packets being received out of order.
Note that a TCP connection’s identity is determined by the four-tuple: (source IP, source port, destination IP, destination port). Here’s an example of such a four-tuple: (127.32.0.1, 32768, 127.0.0.1, 11211).
Because TCP packets can arrive out of order, there might still be packets in-flight associated with that connection. If a new TCP connection with the same four-tuple is opened, the receiver will incorrectly associate the packet with the new connection, even though it was part of the old one, as depicted below (here I’m simplifying the connect and close to a single packet rather than using three packets).
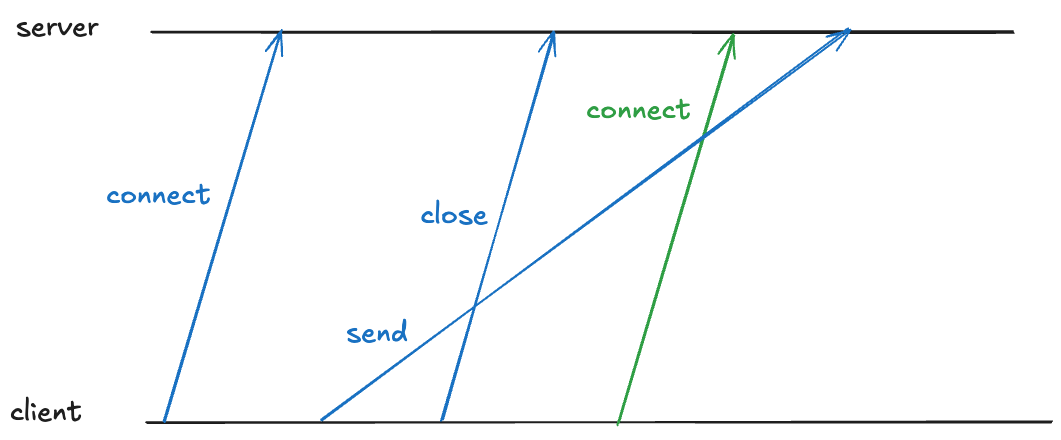
TIME_WAIT also prevents this by having the client enter TIME_WAIT that is long enough to guarantee that the sent packet is received before the new connection can be opened on the same port.
Eating up the ephemeral port space
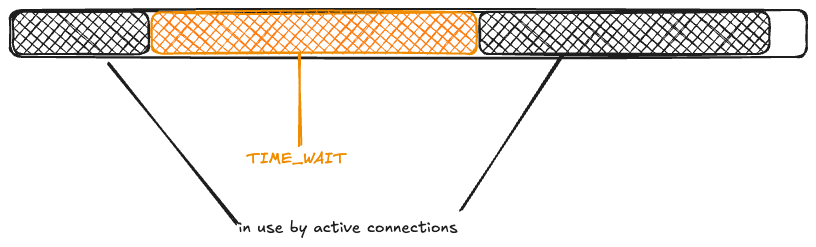
Because you have to wait about a minute before you can reuse an ephemeral port, TIME_WAIT reduces the amount of available ephemeral ports.
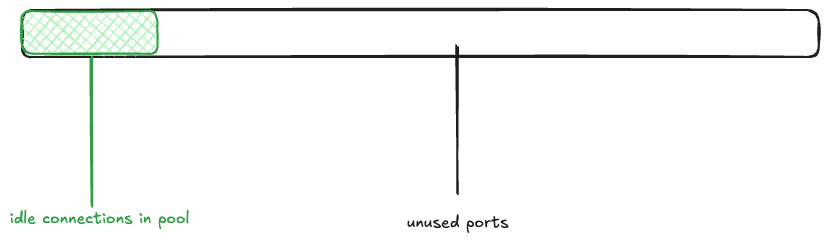
Returning to the Bluesky scenario, imagine that the memcached connection pool is fully populated (there are 1000 idle connections ready to be used), and the rest of the ephemeral ports are free. I’ll depict the space of 28,232 ephemeral ports as a rectangle, with the green rectangle indicating the connection pool.
Next, a wave of 15K connections are created. This takes all 1000 of the idle connections, and has to make 14K new connections.
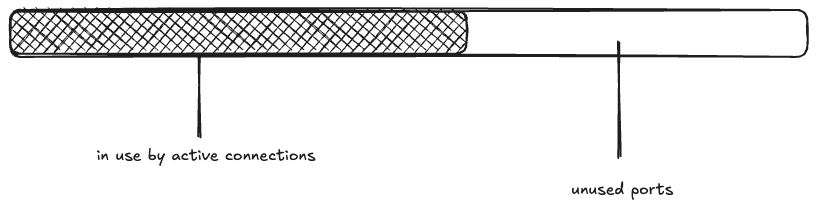
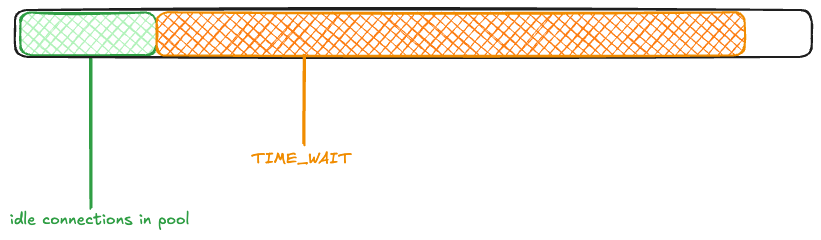
The maximum idle connections is set to 1000, so 1000 of the active connections get returned to the pool. The rest of the connections are closed, and eventually enter the TIME_WAIT state:
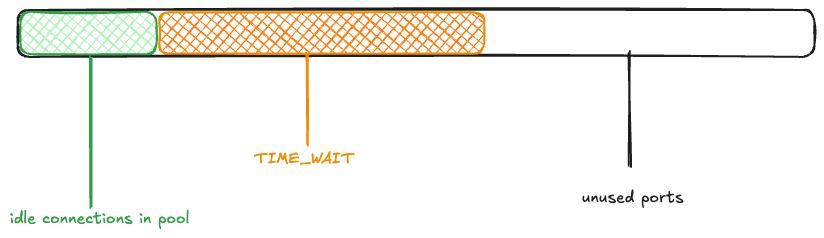
Now, another wave of connection requests comes in. Because the ephemeral ports are in use by TCP connections in the TIME_WAIT state, they’re unavailable:
Once again, 1000 connections get returned to the pool, and the rest enter TIME_WAIT.
You can see how the ephemeral ports could be consumed if large numbers of connection requests came in one after another before the TIME_WAIT timer elapsed.
Saturation, part 2: memory
While Bluesky observed the problem with ephemeral port exhaustion on Saturday, it wasn’t until the Monday that they suffered from an outage.
From the write-up, it’s not clear to me what exactly changed on Monday. Perhaps it was just an organic increase in traffic that exacerbated the problem? Whatever it was, the ephemeral port exhaustion contributed to a cascading failure.

According to the write-up, the failure cascade went something like this:
- The ephemeral port exhaustion led to error messages when attempting to call memcached.
- Every memcached error resulted in a log line being written synchronously to disk.
- A large number of goroutines blocked in synchronous system calls led to the Go runtime spawning many OS-level threads (I learned that OS-level threads are called M in Go parlance).
- This large number of OS-level threads put memory pressure on the app.
- As a result, the data plane experienced stop-the-world GC pauses as well as OOM kills.
Note that because TIME_WAIT is an OS-level state, a data plane process that was OOM killed and restarted would still face limits on the ephemeral port space!
The workaround: leveraging multiple loopbacks
I was impressed by their improvised solution to deal with the problem. I’ve been talking about how an ephemeral port can be consumed, but it’s not actually the port itself. When calling the bind function, you provide not just a port, but the local IP address you want to bind to. It’s the (IP, port) pair that is limited, not the port.
So, if you want to create a TCP connection to a local process (like, say, memcache), and the pair (127.0.0.1,32768) is already in use, if there are other IP addresses that are loopback addresses, you can use those too!
On Linux, by default, all 127.*.*.* IP addresses are loopback address!
# ip route show table local
local 127.0.0.0/8 dev lo proto kernel scope host src 127.0.0.1
...(Note that this is different from macOS, which only routes 127.0.0.1 via loopback by default).
This means that you potentially have access to a much larger space of ephemeral ports!
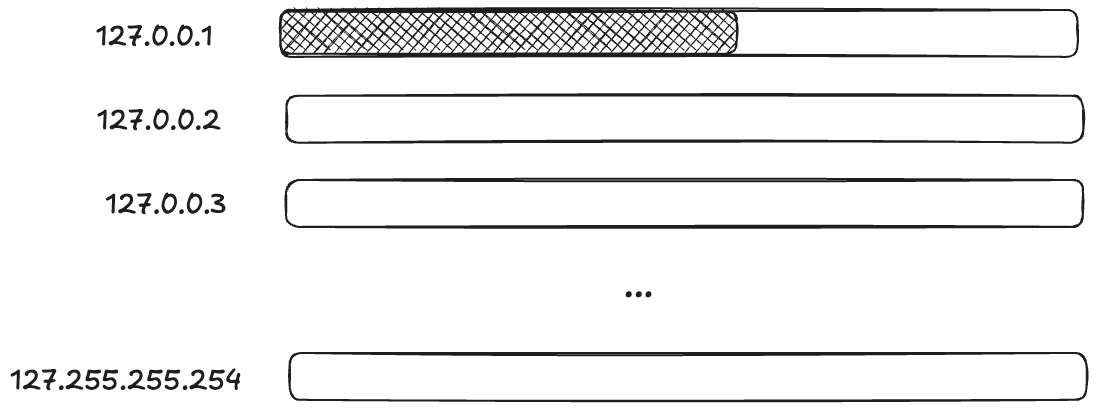
Applying terminology from resilience engineering, ephemeral ports are a resource, and you have to do work to mobilize these additional resources.
For Bluesky, the work of marshaling resources came in the form of modifying the code that made the TCP connections. They modified it to randomly select a loopback IP address. Here’s the code from the blog post:
// Use a custom dialer that picks a random loopback IP for each connection.// This avoids ephemeral port exhaustion on a single IP when a container// restarts (TIME_WAIT sockets from the old process block the fixed IP).memcachedClient.DialContext = func(ctx context.Context, network, address string) (net.Conn, error) { ip := net.IPv4(127, byte(1+rand.IntN(254)), byte(rand.IntN(256)), byte(1+rand.IntN(254))) d := net.Dialer{LocalAddr: &net.TCPAddr{IP: ip}} return d.DialContext(ctx, network, address)}
Calabro’s describes the above change as:
The band-aid fix was insane but did the job.
I wouldn’t describe this is insane, though. This is exactly the kind of improvisational work that you frequently have to do in order to get a system back to healthy during the incident.
Diagnostic challenges
Calabro briefly discusses how difficult it was to diagnose the issue, emphasis mine:
It was all buried in there, but it was hard to know where to look when so much was falling over all at once. You need to have the mental discipline and high granularity in your metrics to be able to cut through the noise to find the real root cause. It’s hard work!
I wish there had been more in this writeup about the process the engineers went through to actually figure out what was going on during the incident, because descriptions of diagnostic work is one of my favorite parts of incident write-ups. We all can stand to do better at improving our diagnostic skills, and one way I try to improve is to read about how someone diagnosed an issue during an incident.
As Calabro mentions, during an incident, there are frequently many things that are failing, and it can be extremely hard to tease out the signals that will help you understand how the system first got into this state.
One particular challenge is noticing an error signal that happens to be unrelated to the ongoing incident, as happened during this incident (emphasis mine):
EDIT: Also, the status page said this was an issue with a 3rd party provider. It was clearly not, apologies for that miscommunication! At the time I posted that status page update, I was looking at some traceroutes that indicated some pretty substantial packet loss from a cloud provider to our data center, but those were not the root cause of the issue.
The messy 9
I want to end this post by bringing up the Messy 9, a set of patterns proposed by the resilience engineering researcher David Woods. These are:
- congestion
- cascades
- conflicts
- saturation
- lag
- friction
- tempos
- surprises
- tangles
I’ve explicitly discussed cascades, saturation, and lag in this post. I suspect that, if we had more detail about this incident, we’d identify even more of these patterns here. Keep on the look-out for these the next time you read an incident write-up or attend an incident review meeting!
References from my SREcon talk on stories
This past week at SREcon 2026 Americas, I gave a plenary talk titled The Power of Stories. I referenced several books and papers in that talk, which are linked below.
Books
From Novice to Expert: Excellence and Power in Clinical Nursing Practice by Patricia Benner. Benner used narrative vignettes in her research to illustrate the different skills of expert nurses.
Visual Explanations: Images and Quantities, Evidence and Narrative by Edward Tufte. This book contains Tufte’s criticism of slides used by NASA engineers to support the Challenger launch decision.
The Challenger Launch Decision: Risky Technology, Culture, and Deviance at NASA by Diane Vaughan. This book describes Vaughan’s findings from studying NASA’s engineering culture in the wake of Challenger disaster.
Storycraft: The Complete Guide to Writing Narrative Nonfiction by Jack Hart. Advice on writing journalism pieces in a narrative style.
Storyworthy by Matthew Dicks. Advice on how to improve your storytelling.
Papers
When Do Stories Work? Evidence and Illustration in the Social Sciences by Andrew Gelman and Thomas Basbøll. Gelman and Basbøll lay out a set of criteria for what makes a good story from a social science perspective.
Two Years Before the Mast: Learning How to Learn about Patient Safety by Richard Cook. Some observations about learning from safety accidents.
An Investigation of the Therac-25 Accidents by Nancy Leveson and Clark Turner. A detailed account of the Therac-25 radiation therapy overdose accidents, including software implementation details and operator interface details.
A Tale of Two Stories: Contrasting Views of Patient Safety by Richard Cook, David Woods, and Charlotte Miller. Report on a workshop about second stories in patient safety.
Report of the Presidential Comission on the Space Shuttle Challenger Accident, Volume 2: Appendix F – Personal Observations on Reliability of Shuttle by Richard Feynman. Feynman’s observations on the difference in risk estimates between NASA engineers and leadership.
Quick thoughts on GitHub CTO’s post on availability
GitHub’s been taking it on the chin on the availability front lately. Yesterday, their CTO, Vlad Fedorov, wrote a post on their blog about their recent incidents: Addressing GitHub’s recent availability issues. This post shares some additional details about three recent incidents. I’ll list them in order that they are mentioned in the post:
- Feb. 9, 2026 – involved an overloaded database cluster
- Feb. 2, 2026 – involved security policies unintentionally blocking access to VM metadata
- Mar. 5, 2026 – involved writes failing on a Redis cluster
First observation: I really appreciate it when a company addresses availability concerns by providing more public details about recent incidents. I always think more of companies that are willing to provide these sorts of details, and I hope GitHub provides even more details about their outages in the future.
Saturation, again and again and again
The first incident is a classic example of saturation. In this case, it was an important database cluster that got overloaded. Because databases are much harder to scale up than stateless services, your best bet when dealing with overload is to figure out how to reduce the load so the database can go healthy again. On the other hand, reducing load means denying requests: a “healthy” database that is taking zero traffic has 0% availability! So it’s a balancing act, and the responders are constrained by the infrastructure that currently exists for selectively limiting traffic. Once the overload happens, you can only twist the knobs that you already have available.
Fedorov notes they’re now prioritizing implementing mechanisms to protect against these sorts of scenarios where load increases unexpectedly.
Protecting downstream components during spikes to prevent cascading failures while prioritizing critical traffic loads.
Taking it to the limit, and then over it
Fedorov also provided details on how they ended up seeing so much more traffic than usual. They released a new model (I think it’s an AI model) on a Saturday, when traffic is lower. And then, on Monday, multiple different factors contributed to an increase in traffic that pushed them over the limit. The blog post mentions these four contributors:
- new model release
- they had reduced a user settings cache TTL from 12 hours to 2 hours, increasing write load
- they hit their regular peak load on Monday
- many of their users updated to the new version of their client apps, and this update activity increased read load
They had reduced the TTL so that people would get the new model more quickly, but reducing the TTL means that more cache evictions, which meant more database load.
This compounding effect of multiple factors is pernicious, because it can be hard to reason about why your system hit a tipping point. From the write-up:
While the TTL change was quickly identified as a culprit, it took much longer to understand why the read load kept increasing, which prolonged the incident.
Understanding the role of multiple, independent contributing factors is hard enough in a post-incident analysis, identifying this in the heat of an incident can be damn near impossible.
The thing about tipping points is that you don’t notice until you tip
This failure mode was a case where the danger was growing over time, but there were no visible symptoms until they hit the limit.
The architecture was originally selected for simplicity at a time when there were very few models and very few governance controls and policies related to those models. But over time, something that was a few bytes per user grew into kilobytes. We didn’t catch how dangerous that was because the load was visible only during new model or policy rollouts and was masked by the TTL.
The resilience engineering folks would call this an example of a brittle collapse, where a system falls over when it hits the limit. We do our best to monitor for trouble and anticipate trouble ahead, but we’re always going to hit scenarios like this where signals of a problem are being masked, until the perfect storm hits. At that point, we just have to be good at responding. And, hopefully, good at learning as well.
Failovers are a different mode of operation
Their February 2nd incident involved a failover where they had some sort of infrastructure issue in one(?) region. GitHub has mechanisms for automatically shifting traffic to healthy regions, and that mechanism worked here, but there was another issue that they hit:
However, in this case, there was a cascading set of events triggered by a telemetry gap that caused existing security policies to be applied to key internal storage accounts affecting all regions. This blocked access to VM metadata on VM creates and halted hosted runner lifecycle operations.
It was the combination of the traffic failover and a telemetry gap that ultimately led to the outage. (Did the automatic traffic shift end up making things worse? I can’t tell from the write-up). The traffic redirection didn’t create the incident, but it enabled it to happen. Whenever our system runs in an alternate mode, there’s an increased risk that we’ll hit some weird edge case that we haven’t seen before because it doesn’t regularly run in that mode. Automated reliability mechanisms often put our systems in these alternate modes. This means that they can enable novel failure modes.
In fact, the March 5th incident followed a similar pattern, this time it was a Redis cluster primary failover enabled the incident.
The failover performed as expected, but a latent configuration issue meant the failover left the cluster in a state with no writable primary.
Reliability vs security, the eternal struggle
The Feb 2nd incident also illustrates the fundamental tradeoff between reliability and security. Reliability’s job is to ensure service access to the users who are supposed to have it. Security’s job is to deny service access to the users that aren’t supposed to have it. These two forces are are in tension, as we see in this incident where a security mechanism denied access.
It’s not just about automation, it’s about more options for responders
In the Feb 9th incident, Fedorov notes how the responders lacked certain functionality that would have helped them mitigate (emphasis mine)
Further, due to the interaction between different services after the database cluster became overwhelmed, we needed to block the extra load further up the stack, and we didn’t have sufficiently granular switches to identify which traffic we needed to block at that level.
He also notes how they had to manually recover from the March 5th incident:
With writes failing and failover not available as a mitigation, we had to correct the state manually to mitigate.
I hope they don’t pull all of their eggs in the “automation” basket in their remediations. For the first incident in particular, automated load shedding is tricky to get right, it’s hard to reason about, and you won’t have experience with the behavior of this new automation until either you have the incident, or until the automation actually creates an incident (e.g., opens a circuit breaker when it shouldn’t). Making it easier for the responders to manually control load shedding during an incident is important as well.
More generally, reliability work isn’t just about putting in automated mechanisms to handle known failure modes. It’s also about setting up the incident responders for success by providing them with as many resources as possible before the next incident happens. In this context, resources means the ability to manually control different aspects of the infrastructure, whether that’s selective traffic blocking, manually updating database state, or many of the other potential remediations that a responder might have to do. The more flexibility they have, the more room to maneuver (to use David Woods’s phrase), the easier it will be for them to improvise a solution, and the faster the next surprising incident will be mitigated.
Grow fast and overload things
The general vibes I see online is that the AI companies have not been doing particularly well in the reliability department. Both OpenAI and Anthropic publish reliability statistics on their status pages. Now, I’m not a fan of using the nines as a meaningful indicator of reliability, but since I don’t have access to any other signals about reliability for these two companies, they’ll have to do for the purposes of this blog post.
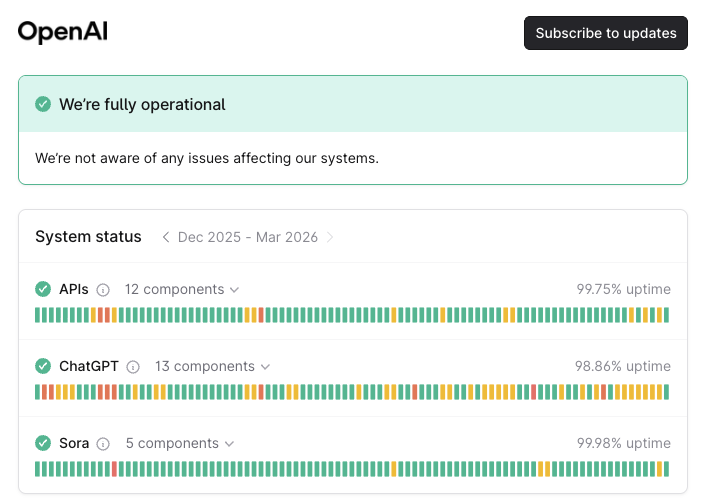
Here’s a screenshot of OpenAI’s status page:
Here’s a screenshot of Anthropic’s status page:
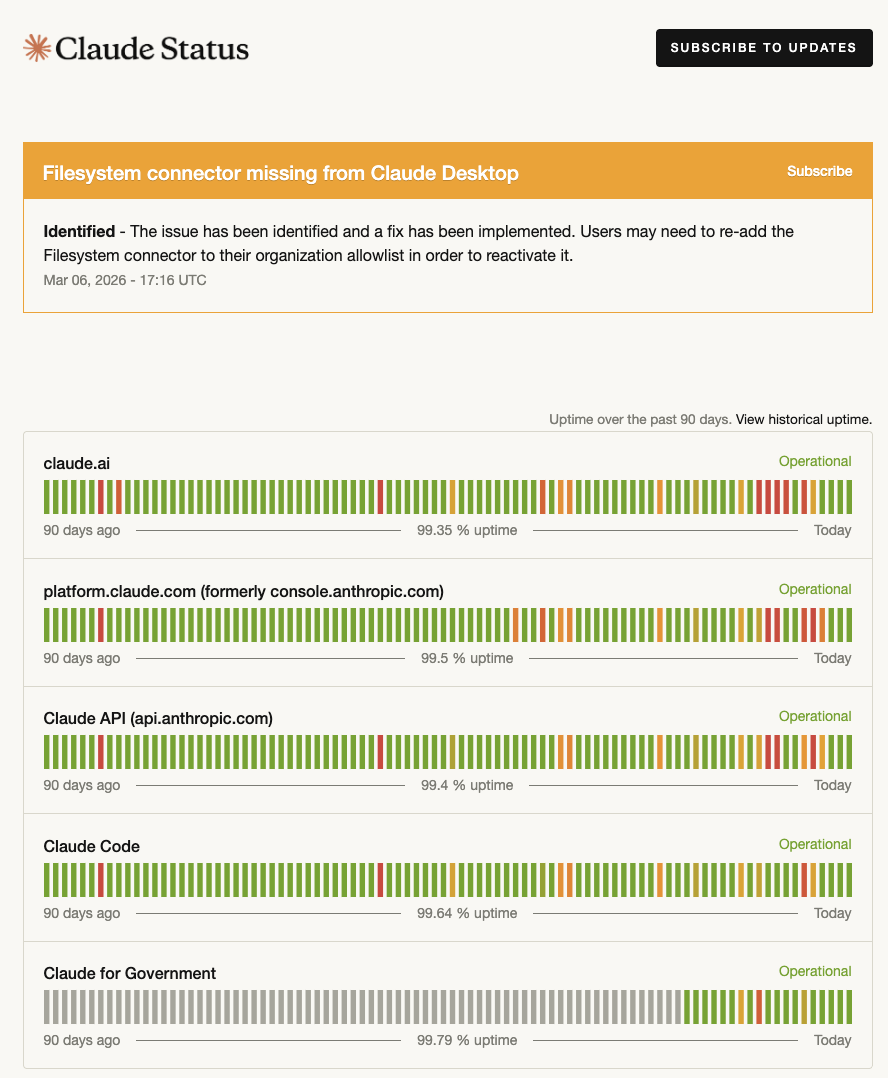
And these numbers… well, they’re not great. With the exception of Sora, none of the services at either company makes it to 99.9% of reliability (three nines). Surprisingly, ChatGPT at 98.86% of uptime does not even make it to two nines.
I’ve seen speculation that the reason that reliability isn’t great is that this is a high development velocity phenomenon. Here’s Boris Cherny (the guy at Anthropic who wrote Claude Code) pushing back on that hypothesis.
A few days later, during a ChatGPT incident, I saw this post from Nik Pash at OpenAI:
This isn’t move fast and break things, but rather grow fast and overload things. These companies are in the business of providing LLMs, which are a new capability. Users are leveraging LLMs in new and innovative ways. The resilience engineering researcher David Woods refers to this phenomenon as a florescence to describe this kind of rapid and widespread uptake.
As a consequence of this florescence, the load on the providers increases unexpectedly and dramatically: they weren’t able to predict the load and have struggled to keep up with it when it happens. These LLM providers are running directly into the problem of saturation (plug: check out my recent post on saturation for the Resilience in Software Foundation).
Now, I expect that these companies will get better at recovering from these unexpected increases in load as they gain experience with the problem. Because of capacity constraints with those pricey GPUs, they can’t always scale their way out of these problem, but they can redistribute resources, and they can get better at load shedding and other sorts of graceful degradation to limit the damage of overload. And I bet that’s where they’re both investing in reliability today. At least, I hope so. Because this problem isn’t going to go away. If anything, I suspect their loads will become even more unpredictable as people continue to innovate with LLMs. Because AIs don’t seem to do any better at predicting the future than humans.
Saturation
I wrote a blog post on saturation for the Resilience in Software foundation. Check it out!
Quick takes on Feb 20 Cloudflare outage
Cloudflare just posted a public write-up of an incident that they experienced on Feb. 20, 2026. While it was large enough for them to write it up like this, it looks like the impact is smaller than the previous Cloudflare incidents I’ve written about here. Given that Cloudflare continues to produce the most detailed public incident write-ups in the industry, I still find them insightful. After all, the insight you get from an incident write-up is not related to the size of the impact! Here are some quick observations from this one.
System intended to improve reliability contributed to incident
The specific piece of configuration that broke was a modification attempting to automate the customer action of removing prefixes from Cloudflare’s BYOIP service, a regular customer request that is done manually today. Removing this manual process was part of our Code Orange: Fail Small work to push all changes toward safe, automated, health-mediated deployment.
Cloudflare has been doing work to improve reliability. In this case, they were working to automate a potentially dangerous manual operation to reduce the risk of making changes. Unfortunately, they got bitten by a previously undiscovered bug in the automation.
How do you pass the flag?
When I first read this write-up, I thought the issue was that they had done a query which was supposed to have a scope, but it was missing a scope, and so returned everything. But that’s not actually what happened.
(I’ve seen the accidentally unscoped query failure mode multiple times in my career, but that’s not actually what happened here)
Instead, what happened here was that the client meant to set the pending_delete flag when making a query against an API.
Based on my reading, the server expected something like this:
GET /v1/prefixes?pending_delete=trueInstead, the client did this:
GET /v1/prefixes?pending_delete
The server code looked like:
if v := req.URL.Query().Get("pending_delete"); v != "" { // server saw v=="", so this block wasn't executed ... return;}// this was executed isntead!
It sounds like there was a misunderstanding about how to pass the flag, based on this language in the write-up:
One of the issues in this incident is that the pending_delete flag was interpreted as a string, making it difficult for both client and server to rationalize the value of the flag.
This is a vicious logic bug, because what happened was that instead of returning the entries to be deleted, the server returned all of them.
Cleanup, but still in use
Since the list of related objects of BYOIP prefixes can be large, this was implemented as part of a regularly running sub-task that checks for BYOIP prefixes that should be removed, and then removes them. Unfortunately, this regular cleanup sub-task queried the API with a bug.
This particular failure involved an automated cleanup task, to replace the manual work that a Cloudflare operator previously had to perform to do the dangerous step of removing published IP prefixes. In this case, due to a logic error, active prefixes were deleted.
Here, there was a business requirement to do the cleanup, it was to fulfill a request of a customer to remove prefix. More generally, cleanup itself is always an inherently dangerous process. It’s one of the reasons that code bases can end up such crufty places over time: we might be pretty sure that a particular bit of code, config, or data, is no longer in use. But are we 100% sure? Sure enough to take the risk of deleting it? The incentives generally push people towards a Chesterton’s Fence-y approach of “eh, safer to just leave it there”. The problem is that not cleaning up is also risky.
Reliability work in-flight
As a part of Code Orange: Fail Small, we are building a system where operational state snapshots can be safely rolled out through health-mediated deployments. In the event something does roll out that causes unexpected behavior, it can be very quickly rolled back to a known-good state. However, that system is not in Production today.
Recovery took longer than they would have liked here: full resolution of all of the IP prefixes took about six hours. Cloudflare already had work in progress to remediate problems like this more quickly! But it wasn’t ready yet. Argh!
Alas, this is unavoidable. Even when we are explicitly aware of risks, and we are working actively to address those risks, the work always takes time, and there’s nothing we can do but accept the fact that the risk will be present until our solution is ready.
People adapt to bring the system back to healthy
Affected BYOIP prefixes were not all impacted in the same way, necessitating more intensive data recovery steps… a global configuration update had to be initiated to reapply the service bindings for [a subset of customers that also had service bindings removed] to every single machine on Cloudflare’s edge.
The failure modes were different for different customers. In some cases, customers were able to take action themselves to remediate the issue through the Cloudflare dashboard. There were also more complex cases where Cloudflare engineers had to take action to restore service.
The write-up focuses primarily on the details of the failure mode. It sounds like the engineers had to do some significant work in the moment (intensive data recovery steps) to recover the tougher cases. This is where resilience really comes into play. The write-up hints at the nature of this work (reapply service bindings… to every single machine on Cloudflare’s edge). Was there pre-existing tooling to do this? Or did they have to improvise a solution? This is the most interesting part to me, and I’d love to know more about this work.
Poor Deming never stood a chance
This post is an elaboration of a shorter post I wrote about five years ago.
The two management giants of the mid-twentieth century were Peter Drucker and W. Edwards Deming. Ironically, while Drucker hails from Austria-Hungary (like me, Drucker emigrated to the U.S. as an adult) and Deming was born in the U.S., it was Drucker that proved to be more influential in America. Deming’s influence was much greater in Japan than it ever was the U.S. If you’ve ever been at an organization that uses OKRs, then you have worked in the shadow of Drucker’s legacy. While you can tell a story about how Deming influenced Toyota, and Toyota inspired the lean movement, I would still describe management in the U.S. as Deming in exile. Deming explicitly stated that management by objectives isn’t leadership, and I think you’d be hard-pressed to find managers in American companies who would agree with that sentiment.

Here I want to talk about why I think it is that Drucker’s ideas were stickier than Deming’s in the U.S. It all comes down to the nature of organizations and people.

An organization is a big, hairy, complex mess, and the bigger the organization is, the hairier and more complex it gets. Managers, on the other hand, have a very finite amount of bandwidth. There are only so many hours in a day, and this number does not increase with the complexity of an organization. And, let’s face it, they’re spending something close to 100% of that bandwidth attending meetings.
How is a manger to make sense of this mess?
OKRs as a mess-reduction mechanism
In the Druckerian approach of OKRs, you set a small number of objectives, and then you identify quantifiable key results for each objective that provide a signal about whether progress towards the objective is being made, and then you monitor the key results. Key results reduce the bandwidth required to make sense of what’s happening in the system. Instead of the blooming, buzzing confusion of the entire system, monitoring key results means you can filter out all of that unnecessary detail to focus specifically on the aspects that are relevant to the bandwidth-limited manager. It’s no coincidence that when John Doerr wrote a book on his experience with OKRs at Intel and how he brought them to Google, he titled his book Measure What Matters.

The beauty of a set of key results is that they take the messiness of the system as input and create a neat summary in spreadsheet or slide format as output.
Deming’s critique
Deming’s approach to the problem of management was radically different from Drucker’s. In his book Out of the Crisis, Deming puts his criticism of the Drucker-ish approach in stark terms. He uses the term deadly disease to describe managing through numerical targets.
Eliminate management by objective. Eliminate management by numbers, numerical goals. Substitute leadership.
Deming’s perspective can be summed up with the old saying: if you don’t change the system, the system doesn’t change. He argued that if you wanted improvements, you had to make systemic changes. Furthermore, you had to understand the system if you wanted to come up with a system improvement that would actually work.

Classical control versus statistical control
Deming was not opposed to the idea of goals: indeed, he was a passionate believer that management should strive to improve quality and productivity, and both of those are goals. He was also not opposed to metrics: he was an advocate of applying Walter Shewhart’s statistical techniques for management. It’s the use of metrics that’s radically different in the two approaches.
The Drucker-ian approach is akin to a classical control system, like a thermostat. Specifying the key results are like setting the desired temperature (say, 68°F), and then the thermostat generates output in order to bring the current temperature of the room in line with the setpoint.
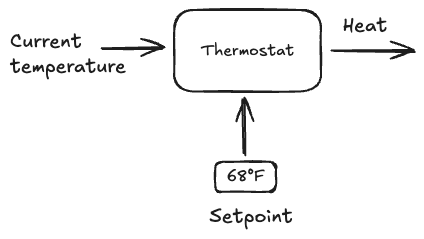
The idea here is that you give the organization a setpoint, and it will implement the control system that will work to achieve the setpoint.
Deming wrote in explicit terms about control, but he meant it in a different sense: we wrote about statistical process control, and statistical process control is about the variability of the output. I’ve written about statistical process control before, but here I’ll touch on the concepts again, with an example. Let’s imagine we are observing the behavior of two brands of thermostats, A and B, each controlling the temperature of a different room. Both thermostats have the same setpoint of 68°F. We observed their behavior by graphing the temperature of the two rooms over time.
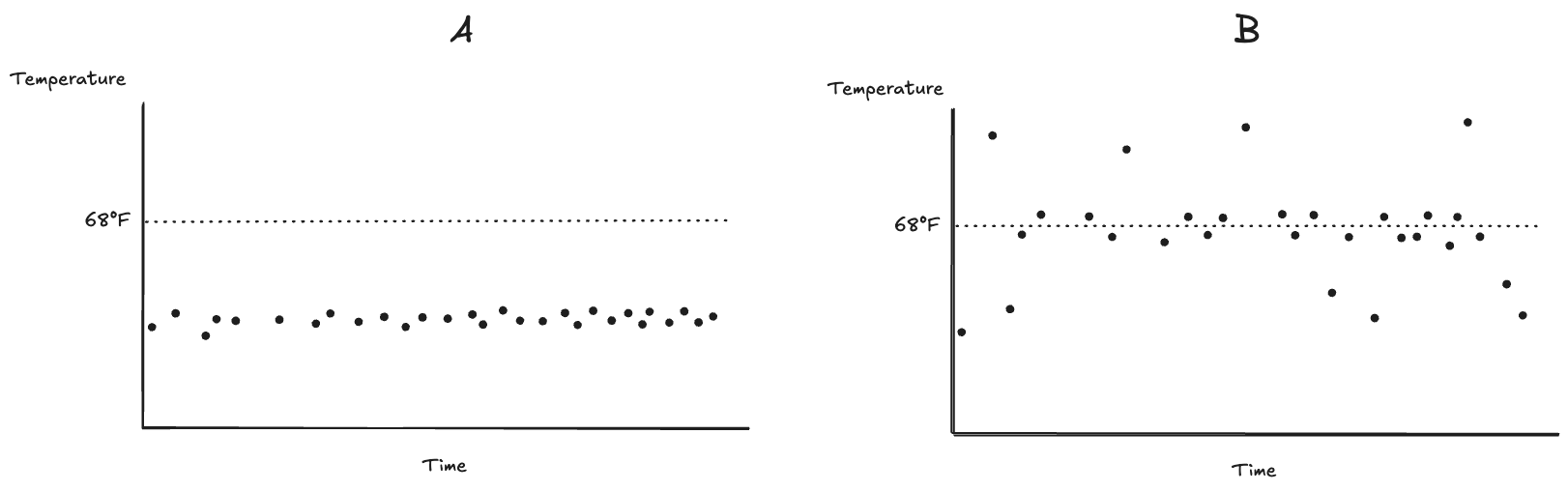
Note how the points for thermostat A all fall within a narrow band, whereas for thermostat B there are many more outliers. We’d say that thermostat A is under statistical process control whether thermostat B is not, even though the average temperature for thermostat B is closer to the setpoint then the average temperature for thermostat A. (In practice, you’d draw a control chart to identify whether the system is under statistical control).
Deming argued that you had to understand whether your system was under statistical control in order to determine what intervention to do in order to make an improvement. For example, if your system was out of control, the next intervention would be to do a qualitative investigation into the outliers. On the other hand, if the system was under statistical control, then you’d have to figure out what systemic change to make to improve things.
Note how you build a classical control system, whereas you observe whether your system is under statistical process control. Statistical process control is about understanding the system.
Drucker makes a manager’s life easier, Deming makes it harder

One of the virtues of OKRs is that they are straightforward for managers to apply. You set direction by specifying objectives, and you enforce accountability by monitoring key results. Applying Deming’s approach, on the other hand, requires a much greater commitment of management bandwidth. Drucker offers a control mechanism with a bounded amount of information, where Deming requires a never-ending research program, with no upper bound on the kind of information that might be relevant. In fact, the information might even be unobservable. Deming approvingly quotes the statistician Lloyd Nelson, who said:
The most important figures needed for management of any organization are unknown and unknowable.
Myself, I’m in the Deming camp, but I can see why Drucker’s ideas won out. In reliability, we talk about “making the right thing easy and the wrong thing hard”, other people call this The Pit of Success. The rationale is that people will tend to do the easy thing over the hard thing. And managers are people too. But sometimes the right thing to do is the harder one, and nothing can be done about that.
