We cut middle managers across the organization because AI allows us to have more direct reports per manager while still measuring and mentoring our teams effectively.
– Matthew Prince, How I Choose Which Cloudflare Employees to Replace With AI
My PhD research involved studying programmer productivity for a very specific domain: high-performance computing, more commonly known as supercomputers. It turns out that supercomputers are difficult to program, and so the U.S. government was interested in assessing the productivity impact of different software engineering technologies (in my case, parallel programming languages), which is how the research got funded.
Since supercomputers are built by connecting together many processors in parallel, you might think that cloud computing providers like AWS obviate the need for supercomputers. Why should a lab buy a very expensive supercomputer when it can just rent compute time from Amazon and get access to the same kind of resources? But what makes a supercomputer isn’t just the processors, it’s also the network interconnect. And that’s because supercomputers are used for problems that require a lot of coordination among processors. For example, consider the problem of simulating the Earth’s climate. The earth is modeled by carving it up into a grid. The grid is divided up among the processors, which each simulate some local part of the grid. But these processors need to exchange data at the grid boundaries, and that involves coordination.
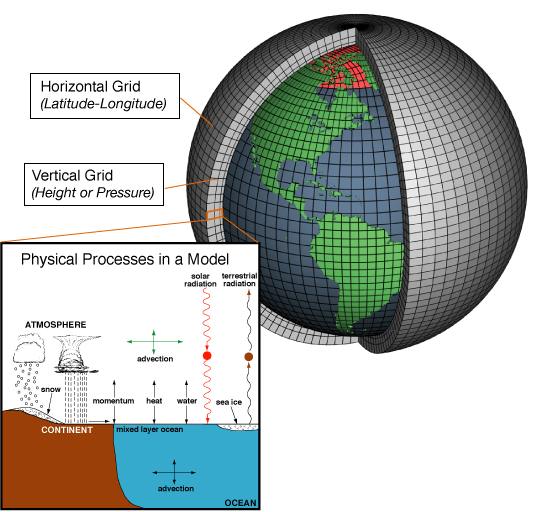
This type of coordination is expensive, because communicating over a network is much slower than communicating with local memory.
In general, as you scale up the number of workers, the coordination overhead increases. This is one of the reasons why we use thread pools rather than allowing an unbounded number of threads. If you keep spawning new threads, eventually the overhead that the operating system has to pay to maintain these threads exceeds the performance gains you get, and the extra threads actually hurt performance.
It’s well known that coordination costs increase with the number of agents involved in the system. This is why we spend more time in meetings in larger organizations, and why these organizations feel like they move so much slower than startups. Larger organizations have to pay the coordination cost of being larger.
With the rise of coding agents, our jobs as engineers is shifting from coding to managing these coding agents. We’re also not restricted to running a single agent, we can run multiple agents in parallel. By doing so, we can get more work done, since we’re not blocked waiting for one coding agent to complete its task. But now we’re not just managing a single agent, we’re coordinating the work of multiple agents. And, of course, we want to keep those agents busy doing useful work!
What this means is that we can expect that engineers will spend more of their time in the future doing coordination work among the agents that they manage. This is on top of the normal coordination work they do with other humans.
I opened this post with a quote from the CEO of Cloudflare, Matthew Prince, about reducing the number of managers in the company, and increasing the span of control of existing managers. They aren’t alone; Meta has also eliminating managers in their recent layoffs. Managers have always had to do coordination work, and as their span increases, they’ll have to do even more of that work. If they are expected to manage coding agents as well as humans, well, that’s yet more coordination work that will be poured on top of their existing load.
All of this new coordination effort represent a significant change in the day-to-day work of software engineering. And, take it from someone who does incident management: coordination is hard! I think this adjustment will be bumpier than people realize.

{kind=link}