The software contract
We software engineers love the metaphor of the contract when describing software behavior: If I give you X, you promise to give me Y in return. One example of a contract is the signature of a function in a statically typed language. Here’s a function signature in the Kotlin programming language:
fun exportArtifact(exportable: Exportable): DeliveryArtifact
This signature promises that if you call the exportArtifact function with an argument of type Exportable, the return value will be an object of type DeliveryArtifact.
Function signatures are a special case for software contracts, in that they can be enforced mechanically: the compiler guarantees that the contract will hold for any program that compiles successfully. In general, though, the software contracts that we care about can’t be mechanically checked. For example, we might talk about a contract that a particular service provides, but we don’t have tools that can guarantee that our service conforms to the contract. That’s why we have to test it.
Contracts are a type of specification: they tell us that if certain preconditions are met, the system described by the contract guarantees that certain postconditions will be met in return. The idea of reasoning about the behavior of a program using preconditions and postconditions was popularized by C.A.R. Hoare in his legendary paper An Axiomatic Basis for Computer Programming, and is known today as Hoare logic. The language of contract in the software engineering sense was popularized by Bertrand Meyer (specifically, design by contract) in his language Eiffel and his book Object-Oriented Software Construction.
We software engineers like contracts they they help us reason about the behavior of a system. Instead of requiring us to understand the complete details of a system that we interact with, all we need to do is understand the contract.
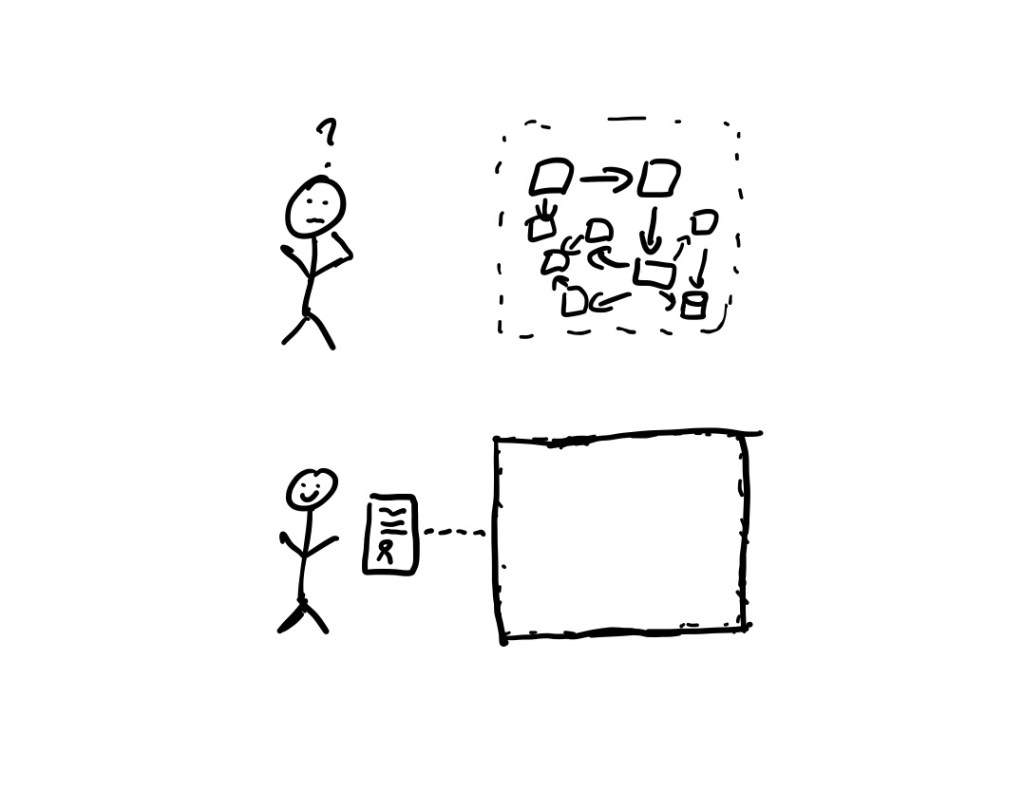
Contracts, therefore, are a form of abstraction. In addition, contracts are composable, we can feed the outputs of system X into system Y if the postconditions of Y are consistent with the preconditions of X. Because we can compose contracts, we can use them to help us build systems out of parts that are described by contracts. Contracts are a tool that enable us humans to work together to build software systems that are too complex for any individual human to understand.
When contracts aren’t useful
Alas, contracts aren’t much use for reasoning about system behavior when either of the following two conditions happen:
- A system’s implementation doesn’t fully conform to its contract.
- The precondition of a system’s contract is violated by a client.
Whether a problem falls into the first or second condition is a judgment call. Either way, your system is now in a bad state.
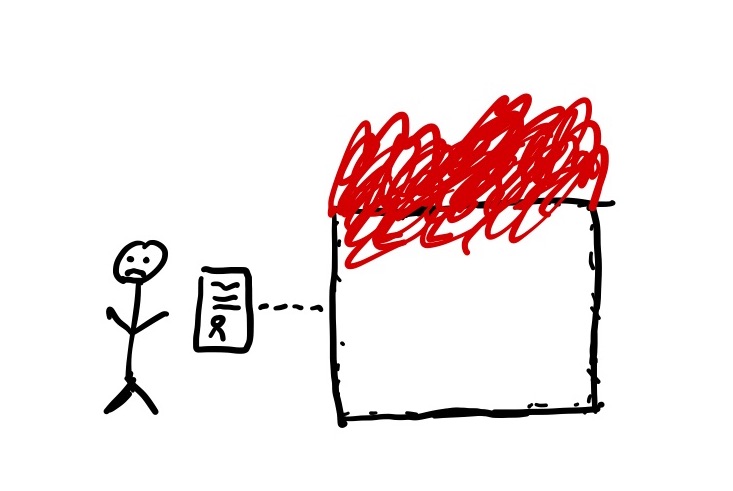
A system that has gotten into a bad state is violating its contract, pretty much by definition. This means we must now deal with the implementation details of the system in order to get it back into a good state. Since no one person understands the entire system, we often need the help of multiple people to get the system back into a good state.
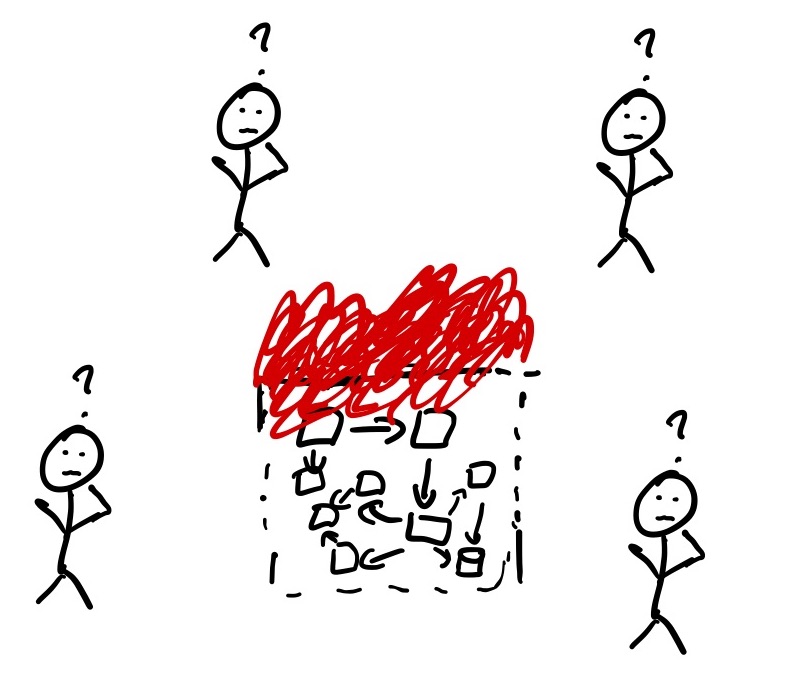
Since contracts can’t help us here, we deal with the complexity by leveraging the fact that different engineers have expertise in different parts of the system. By working together, we are pooling the expertise of the engineers. To pull this off, the engineers need to coordinate effectively. Enter the Basic Compact.
The Basic Compact and requirements of coordination
Gary Klein, Paul Feltovich and David Woods defined the Basic Compact in their paper Common Ground and Coordination in Joint Activity:
We propose that joint activity requires a “Basic Compact” that constitutes a level of commitment for all parties to support the process of coordination. The Basic Compact is an agreement (usually tacit) to participate in the joint activity and to carry out the required coordination responsibilities.
One example of a joint activity is… when engineers assemble to resolve an incident! In doing so, they enter a Basic Compact: to work together to get the system back into a stable state. Working together on a task requires coordination, and the paper authors list three primary requirements to coordinate effectively on a joint activity: interpredictablity, common ground, and directability.
The Basic Compact is also a commitment to ensure a reasonable level of interpredictability. Moreover, the Basic Compact requires that if one party intends to drop out of the joint activity, he or she must inform the other parties.
Intepredictability is about being able to reason about the behavior of other people, and behaving in such a way that your behavior is reasonable to others. As with the world of software contracts, being able to reason about behavior is critical. Unlike software contracts, here we reasoning about agents rather than artifacts, and those agents are also reasoning about us.
The Basic Compact includes an expectation that the parties will repair faulty knowledge, beliefs and assumptions when these are detected.
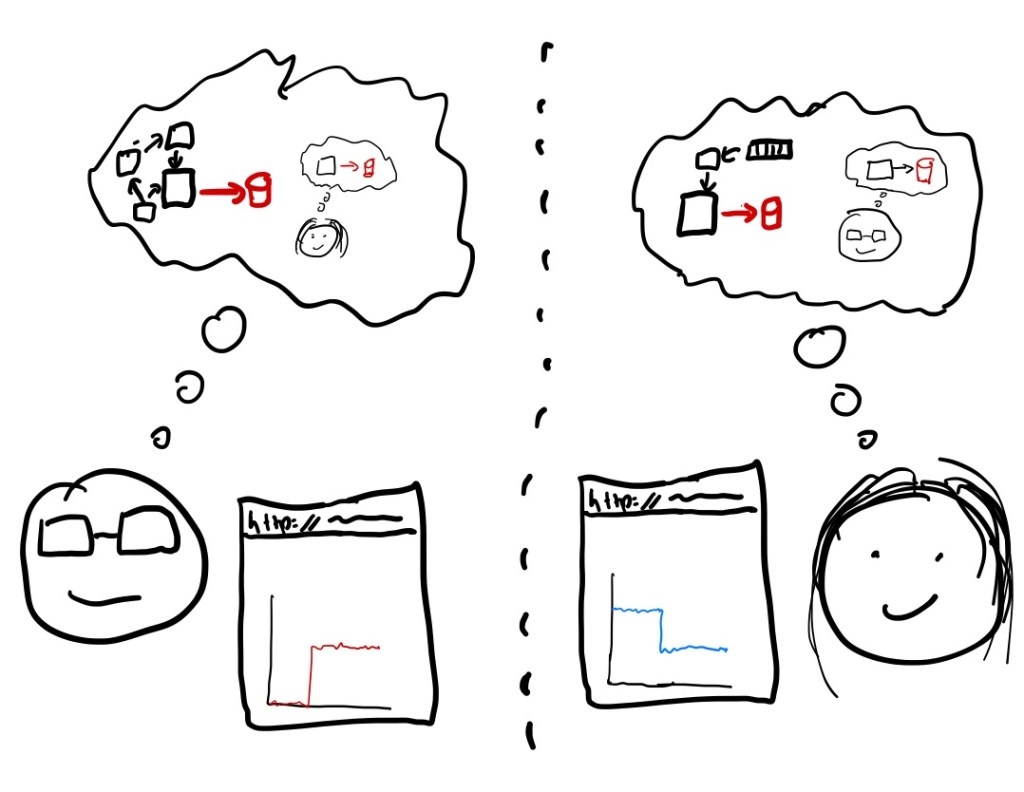
During an incident, the responders need to maintain a shared understanding about information such as the known state of the system and what mitigations people are about to attempt. The authors use the term common ground to describe this shared understanding. Anyone who has been in in an on call rotation will find the following description familiar:
All parties have to be reasonably confident that they and the others will carry out their responsibilities in the Basic Compact. In addition to repairing common ground, these responsibilities include such elements as acknowledging the receipt of signals, transmitting some construal of the meaning of the signal back to the sender, and indicating preparation for consequent acts.
Maintaining common ground during an incident takes active effort on behalf of the participants, especially when we’re physically distributed and the situation is dynamic: where the system is not only in a bad state, but it’s in a bad state that’s changing over time. Misunderstandings can creep in, which the authors describe as a common ground breakdown that requires repair to make progress.
A common ground breakdown can mean the difference between a resolution time of minutes and hours. I recall an incident I was involved with, where an engineer made a relevant comment in Slack early on during the incident, and I missed its significance in the moment. In retrospect, I don’t know if the engineer who sent the message realized that I hadn’t properly processed its implications at the time.
Directability refers to deliberate attempts to modify the actions of the other partners as conditions and priorities change.
Imagine a software system has gone unhealthy in one geographical region, and engineer X begins to execute a failover to remediate. Engineer Y notices customer impact in the new region, and types into Slack, “We’re now seeing a problem in the region we’re failing into! Abort the failover!” This is an example of directability, which describes the ability of one agent to affect the behavior of another agent through signaling.
Making contracts and compacts first class
Both contracts and compacts are tools to help deal with complexity. People use contracts to help reason about the behavior of software artifacts. People use the Basic Compact to help reason about each other’s behavior when working together to resolve an incident.
I’d like to see both contracts and compacts get better treatment as first-class concerns. For contracts, there still isn’t a mainstream language with first-class support for preconditions and postconditions, although some non-Eiffel languages do support them (Clojure and D, for example). There’s also Pact, which bills itself as a contract testing tool, that sounds interesting but I haven’t had a chance to play with.
For coordination (compacts), I’d like to see explicit recognition of the difficulty of coordination and the significant role it plays during incidents. One of the positive outcomes of the growing popularity of resilience engineering and the learning from incidents in Software movement is the recognition that coordination is a critical activity that we should spend more time learning about.
Further reading and watching
Common Ground and Coordination in Joint Activity is worth reading in its entirety. I only scratched the surface of the paper in this post. John Allspaw gave a great Papers We Love talk on this paper.
Laura Maguire has done some recent PhD work on managing the hidden costs of coordination. She also gave a talk at QCon on the subject.
Ten challenges for making automation a “team player” in joint human-agent activity is a paper that explores the implications of building software agents that are capable of coordinating effectively with humans.
An Axiomatic Basis for Computer Programming is worth reading to get a sense of the history of preconditions and postconditions. Check out Jean Yang’s Papers We Love talk on it.
.
