Now, here, you see, it takes all the running you can do, to keep in the same place. – Lewis Carroll, Through the Looking-Glass, and What Alice Found There
LLM coding may be revolutionizing software development productivity, but it doesn’t seem to be generating the same sorts of gains in software reliability yet. Two events that caught my eye today, although only one is directly related to LLMs.
The first event was that Anthropic suffered from another incident today, which lasted about an hour and a half.
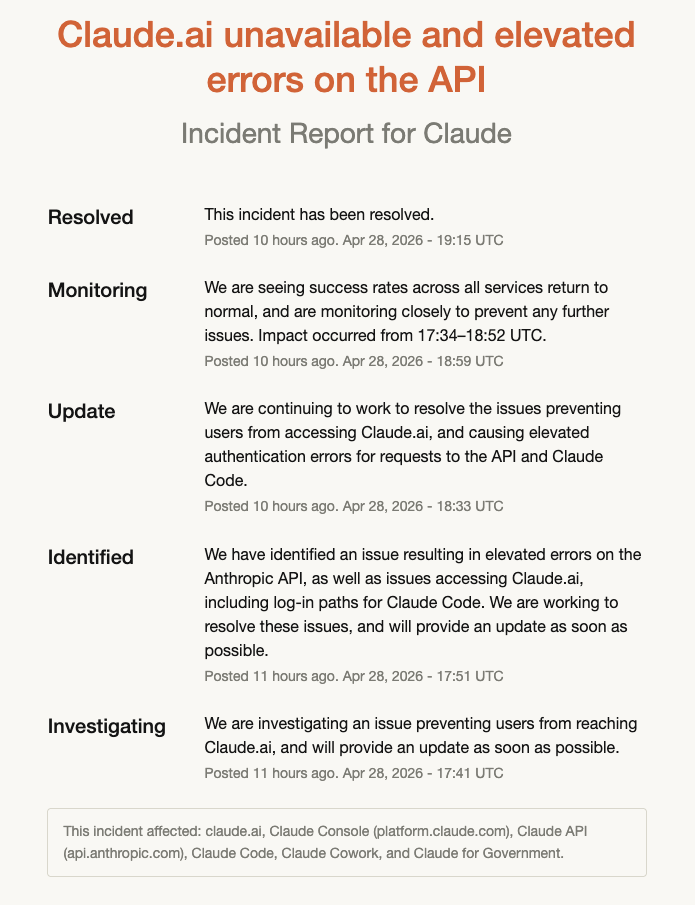
This brought Claude Code down to one nine over the past 60 days, although they’re at two nines if you look over 90 days. I know, I know, I shouldn’t even talk about the nines, but they do make for a great screenshot.
The second event, the one I really want to focus in here, was GitHub’s CTO Vlad Fedorov writing the blog post: An update on GitHub availability. It was only six weeks ago that he wrote Addressing GitHub’s recent availability issues, which is clearly a sign that GitHub is concerned about the impact of recent incidents on their brand.
I want talk about GitHub’s post in the context of David Woods’s Messy 9 collection of patterns about complex systems. I’ve mentioned them before, but to re-iterate, they are: congestion, cascades, conflicts, saturation, lag, friction, tempos, surprises, tangles.
Fedorov notes that AI is driving a lot more activity on the site: the counts of pull requests, commits, repos are growing like never before.
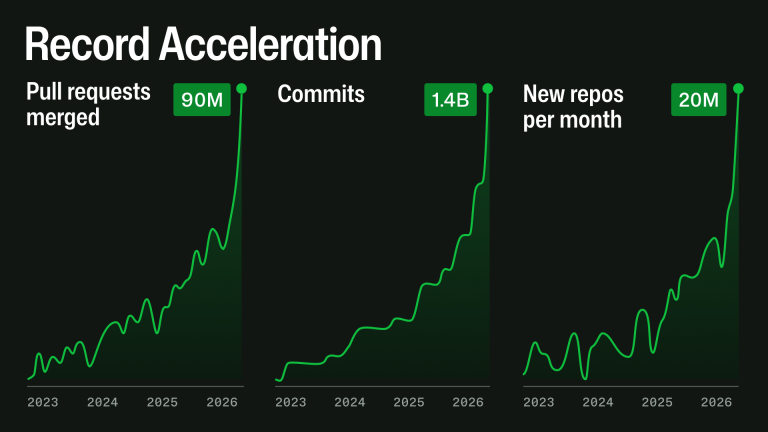
This is a great example of an increase in tempo: the environment that GitHub exists within is changing faster than it has previously. Heck, it’s right there in the title of that graphic: “Record Acceleration”. In particular, the load on GitHub as a system has increased significantly, and GitHub is struggling to keep up with this load. It puts GitHub at risk of saturation.
This exponential growth does not stress one system at a time. A pull request can touch Git storage, mergeability checks, branch protection, GitHub Actions, search, notifications, permissions, webhooks, APIs, background jobs, caches, and databases. At high scale, small inefficiencies compound: queues deepen, cache misses become database load, indexes fall behind, retries amplify traffic, and one slow dependency can affect several product experiences.
GitHub has to make changes to its internal systems in order to handle this load. I don’t work at GitHub, so I don’t know the details, but I have high confidence that they can’t simply horizontally scale their way out of the problem. They will likely have to rearchitect parts of their system in order to handle the increased load. And that will take time, even in the age of AI. And this is where the lags come in. It takes time to actually implement long-term solutions that can handle the load, which increases the probability of short-term outages since the system is running too close to the margin, and those outages delay the long-term solution work because the short-term firefighting steals engineering cycles, and so on. It’s a dangerous place to be, and I don’t envy them.
(As an aside, one other aspect of Fedorov’s post that I found interesting was how the increasing popularity of monorepos is also putting additional stress on GitHub as a system. People are using them in ways that designers had not envisioned!)
I don’t know whether Anthropic will reveal any details about the nature of their most recent outage, but as I’ve written about previously, the author of Claude Code mentioned on Twitter that Anthropic’s availability issues are related to unexpectedly rapid increases in demand. They are victims of their own success.
One of the reasons I don’t expect AI to improve reliability is that I don’t think LLMs are well-suited to mitigate the risk of saturation. As GitHub demonstrates, LLMs are more likely to be on the supply side when it comes to risk of saturation.
