Here’s a recent comment on LinkedIn from John Allspaw, on a post by Gandhi Mathi Nathan Kumar about availability.
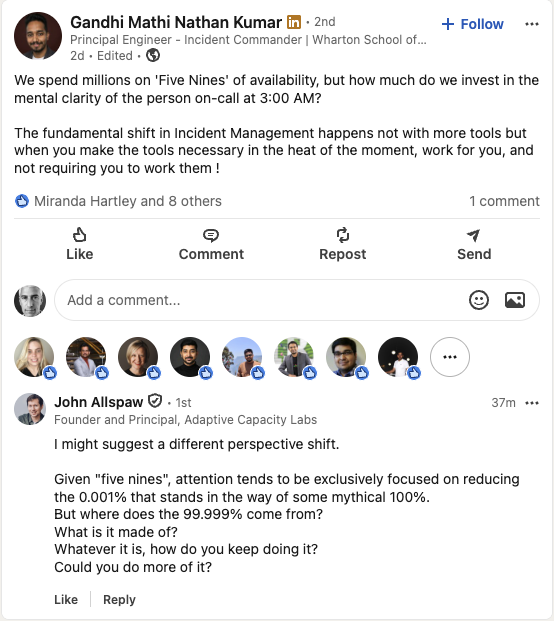
Allspaw’s comment is a succinct description of a safety model proposed by the Danish resilience engineering researcher Erik Hollnagel: Safety-II. Hollnagel has described Safety-II in his book Safety-I and Safety-II: The Past and Future of Safety Management, as well as in white papers aimed at aviation and medical audiences. The book and white papers are all quite approachable, and I recommend checking them out.
Hollnagel’s observation is simultaneously trite and surprising: most of the time our systems are succeeding; incidents are the exception, not the norm. After all, this is why we measure availability in nines. The traditional approach to safety, what Hollnagel calls Safety-I, is to try to reduce the bad stuff, the work that leads to incidents. Hollnagel asks us to think about things differently: what if, instead, we focused on cultivating the good stuff: the everyday work that is consistently preventing accidents? There’s a lot more good stuff happening than bad stuff! Or, as my former colleague Ryan Kitchens put it, instead of asking why do things go wrong, it’s more productive to ask how do things go right?
In Hollnagel’s Safety-II model, the normal work that people in your organization do everyday is actively creating safety. Or, as the American organizational psychologist Karl Weick put it in his 1987 paper Organizational culture as a source of high reliability, reliability is a dynamic non-event. That is, the work is explicitly positive, and by the nature of this work, people are constantly doing work that is preventing incidents from happening. However, this work isn’t able to prevent all incidents, which is why they still happen. But taking Safety-II seriously means trying to understand how it is that normal work prevented previous incidents, rather than just trying to understand how it failed to prevent the last one. In Hollnagel’s words, the purpose of an investigation is to understand how things usually go right as a basis for explaining how things occasionally go wrong.
Focusing on the scenarios where things go right is a radical reframing of the problem, so much so that it is a genuinely strange idea, something that violates our intuitions about how systems break. We operate under a baseline, unspoken assumption that reliability is a passive thing, that the default behavior of a system is to stay up, and that somebody needs to actively do something wrong in order to cause the system to break. In other words, we view the day-to-day work people in the system do as a potential threat to reliability. And then, when an incident happens, we try to identify the bad work that broke the system.
If we were to take Safety-II seriously, we’d have to focus on how people adapt their work. It means seeing that people change how they do their work based on the pressures that they are currently facing and the constraints that they are under. More importantly, it means that we have to acknowledge that these adaptations are usually successful. If you only look at these adaptation within the context of an incident, and try to improve reliability by preventing these adaptations, it’s like believing you can figure out how to win the lottery by examining the behaviors of lottery winners. Sure, you can identify patterns among the behavior of lottery winners. But there are even more folks who lose the lottery who exhibit those behaviors, you’re just not looking at those. Note, though, how much this goes against the way people think about how incidents happen.
Safety-II is also challenging to adopt because organizations are simply not used to studying the normal work that goes on in an organization in order to answer the question, “what work is going particularly well, and how can we do more of it?” The closest we probably get is shadowing that happens when new employees join. We do have developer experience surveys, but those focus specifically on problems with existing tooling. I don’t know of any reliability organization at any tech company out there that takes a Safety-II approach and spends time understanding what’s happening when it looks like there’s nothing happening. Perhaps they’re out there, but if they are, they aren’t writing about this work. The one exception to this is the resilience in software folks, but even with us, we’re generally focused on shifting the emphasis of post-incident examination of work, rather than examining work outside of the context of incidents.
Now, attention is a limited resource in an organization, and incidents win the attention of an organization because they are troubling by their nature. Because attention is limited, if all the indicators are currently green, that’s taken as a sign that we can safely spend our attention budget elsewhere. In the tech industry, we also don’t have great models for how to study normal work within an organization, because nobody seems to be doing it. Or, if they are, they aren’t writing about it. In his Safety-II book, Hollnagel recommends doing interviews and field observations. In tech, field observations are trickier because the majority of our work is effectively invisible; we do our work alone at a computer. We can observe interactions over channels like Slack and Zoom, but that’s only part of the story. I suspect that interviews are our best potential source of information here. And then we need to take what we’ve learned from the interviews and use those insights to improve reliability by amplifying what’s already working well. That’s not something we have experience with.
It’s no surprise, then, that Safety-II hasn’t caught on our field. It cuts against our intuitions about the nature of complex systems failure, and we don’t have good public examples to work from about this. We resilience in software folks are trying to push the industry in this direction with trying to get people to think differently about what we can get out of incident analysis, and that’s probably our best bet right now. But we have a long way to go.

The interview suggestion at the end is the most underrated part. The field observation problem in tech isn’t just that work is invisible. It’s that successful work leaves no artifact at all. A deployment caught before it hit prod, an on-call engineer who noticed something at 2pm and fixed it before it became a 2am page. None of that gets written down.
Postmortems are probably the closest thing we have to a Safety-II artifact, and they’re almost entirely structured around failure. What went wrong, timeline, action items. There’s usually a “what went well” section but nobody fills it out seriously. If Safety-II were a real design constraint, the questions would look different. “What work prevented this from being a SEV0 instead of a SEV2?” “What did the on-call engineer already know that let them close this in 8 minutes?” The investigation should surface the competence, not just the failure mode.
I work on Runframe and this post has me questioning whether our postmortem templates are even asking the right questions. Probably a longer conversation than a comment can hold.