The Canadian Radio-television and Telecommunications Commission (CRTC) has posted an executive summary of a report on a major telecom outage that happened in 2022 to Rogers Communications, which is one of the major Canadian telecom companies.
The full report doesn’t seem to be available yet, and I’m not sure if it ever will be publicly released (edit: the full report was released on November 2024). I recommend you read the executive summary, but here are some quick impressions of mine.
Note that I’m not a network engineer (I’ve only managed a single rack of servers in my time), so I don’t have any domain expertise here.
Migration!
When you hear “large-scale outage”, a good bet is that involved a migration. The language of the report describes it as an upgrade, but I suspect this qualifies as a migration.
In the weeks leading to the day of the outage on 8 July 2022, Rogers was executing on a seven-phase process to upgrade its IP core network. The outage occurred during the sixth phase of this upgrade process.
I don’t know anything about what’s involved a telecom upgrading its IP core network, but I do have a lot of general opinions about migrations, and I’m willing to bet they apply here as well.
I think of migrations as high-impact, bespoke changes that the system was not originally designed to accommodate.
They’re high-impact because things can go quite badly if something goes wrong. If you’ve worked at a larger company, you’ve probably experienced migrations that seem to take forever, and this is one of the reasons why: there’s a lot of downside risk in doing migration work (and often not much immediate upside benefit for the people who have to do the work, but that’s a story for another day).
Migrations are bespoke in the sense that each migration is a one-off. This makes migrations even more dangerous because:
- The organization doesn’t have any operational muscles around doing any particular migration, because each one is new.
- Because each migration is unique, it’s not worth the effort to build tooling to support doing the migration. And even if you build tools, those tools will always be new, which means they haven’t been hardened through production use.
There’s a reason why you hear about continuous integration and continuous delivery but not continuous migration, even though every org past a certain age will have multiple migrations in flight.
Finally, migrations are changes that the system was not originally designed to accommodate. In my entire career, during the design of a new system, I have never heard anyone ask, “How are we going to migrate off of this new system at the end of its life?” We just don’t design for migrating off of things. I don’t even know if it’s possible to do so.
Saturation!
Rogers staff removed the Access Control List policy filter from the configuration of the distribution routers. This consequently resulted in a flood of IP routing information into the core network routers, which triggered the outage. The flood of IP routing data from the distribution routers into the core routers exceeded their capacity to process the information. The core routers crashed within minutes from the time the policy filter was removed from the distribution routers configuration. When the core network routers crashed, user traffic could no longer be routed to the appropriate destination. Consequently, services such as mobile, home phone, Internet, business wireline connectivity, and 9-1-1 calling ceased functioning.
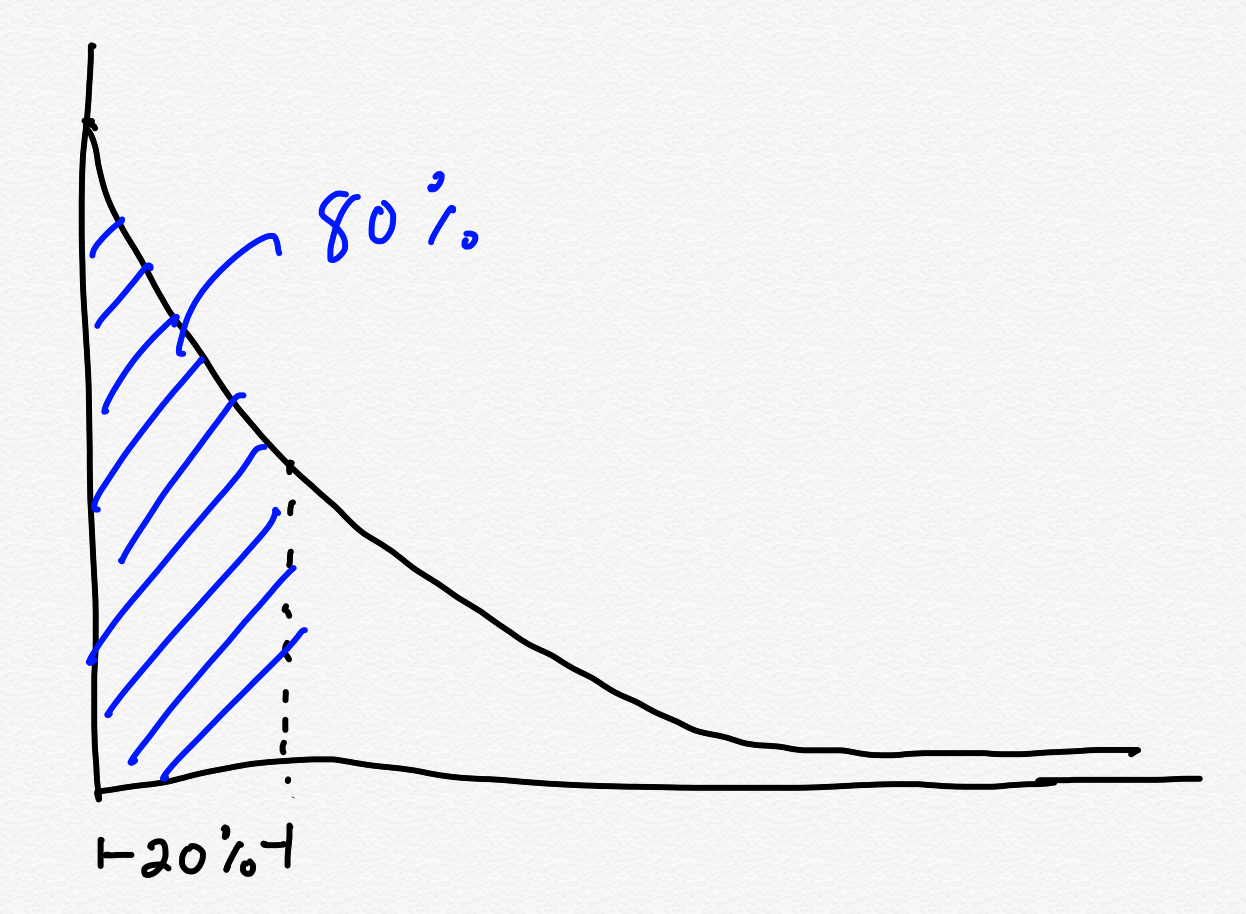
Saturation is a term from resilience engineering which refers to a system receiving being pushed to the limit of the amount of load that it can handle. It’s remarkable how many outages in distributed systems are related to some part of the system being overloaded, or hitting a rate limit, or exceeding some other limit. (For example, see Slack’s Jan 2021 outage). This incident is another textbook example of a brittle system, which falls over when it becomes saturated.
Perception of risk
I mentioned earlier that migrations are risky, and everyone knows migrations are risky. Roger engineers knew that as well:
Rogers had initially assessed the risk of this seven-phased process as “High.”
Ironically, the fact that the migration had gone smoothly up until that point led them to revise their risk assessment downwards.
However, as changes in prior phases were completed successfully, the risk assessment algorithm downgraded the risk level for the sixth phase of the configuration change to “Low” risk, including the change that caused the July 2022 outage.
I wrote about this phenomenon in a previous post, Any change can break us, but we can’t treat every change the same. The engineers gained confidence as they progressed through the migration, and things went well. Which is perfectly natural. In fact, this is one of the strengths of the continuous delivery approach: you build enough confidence that you don’t have to babysit every single deploy anymore.
But the problem is that we can never perfectly assess the risk in the system. And no matter how much confidence we build up, that one change that we believe is safe can end up taking down the whole system.
I should note that the report is pretty blame-y when it comes to this part:
Downgrading the risk assessment to “Low” for changing the Access Control List filter in a routing policy contravenes industry norms, which require high scrutiny for such configuration changes, including laboratory testing before deploying in the production network.
I wish I had more context here. How did it make sense to them at the time? What sorts of constraints or pressures were they under? Hopefully the full report reveals more details.
Cleanup
Rogers staff deleted the policy filter that prevented IP route flooding in an effort to clean up the configuration files of the distribution routers.
Cleanup work has many of the same risks as migration work: it’s high-impact and bespoke. Say “cleanup script” to an SRE and watch the reaction on their face.
But not cleaning up is also a risk! The solution can’t be “never do cleanup” in the same way it can’t be “never do migrations”. Rather, we need to recognize that this work always involve risk trade-offs. There’s no safe path here.
Failure mode makes incident response harder
At the time of the July 2022 outage, Rogers had a management network that relied on the Rogers IP core network. When the IP core network failed during the outage, remote Rogers employees were unable to access the management network. …
Rogers staff relied on the company’s own mobile and Internet services for connectivity to communicate among themselves. When both the wireless and wireline networks failed, Rogers staff, especially critical incident management staff, were not able to communicate effectively during the early hours of the outage.
When an outage affects not just your customers but also your engineers doing incident response, life gets a whole lot harder.
This brings to mind the Facebook outage from 2021:
[A]s our engineers worked to figure out what was happening and why, they faced two large obstacles: first, it was not possible to access our data centers through our normal means because their networks were down, and second, the total loss of DNS broke many of the internal tools we’d normally use to investigate and resolve outages like this.
Component substitution fallacy
The authors point out that the system was not designed to handle this sort of overload:
Absence of router overload protection. The July 2022 outage exposed the absence of overload protection on the core network routers. The network failure could have been prevented had the core network routers been configured with an overload limit that specifies the maximum acceptable number of IP routing data the router can support. However, the Rogers core network routers were not configured with such overload protection mechanisms. Hence, when the policy filter was removed from the distribution router, an excessive amount of routing data flooded the core routers, which led them to crash.
This is a great example of the component substitution fallacy, which fails to acknowledge explicit trade-offs that are made within organizations about which parts of the system to work on. Note that the Rogers engineers will certainly build in router overload protection now, but it means that’s engineering effort that won’t be spent building protections against other failure modes that haven’t happened yet.
Acknowledging trade-offs
To the authors’ credit, they explicitly acknowledge the tradeoffs involved in the overall design of the system.
The Rogers network is a national Tier 1 network and is architecturally designed for reliability; it is typical of what would be expected of such a Tier 1 service provider network. The July 2022 outage was not the result of a design flaw in the Rogers core network architecture. However, with both the wireless and wireline networks sharing a common IP core network, the scope of the outage was extreme in that it resulted in a catastrophic loss of all services. Such a network architecture is common to many service providers and is an example of the trend of converged wireline and wireless telecom networks. It is a design choice by service providers, including Rogers, that seeks to balance cost with performance.
I really hope the CRTC eventually releases the full report, I’m looking forward to reading it.