Laura Nolan of Slack recently published an excellent write-up of their Jan. 4, 2021 outage on Slack’s engineering blog.
One of the things that struck me about this writeup is the contributing factors that aren’t part of this outage. There’s nothing about a bug that somehow made its way into a production, or an accidentally incorrect configuration change, or how some corrupt data ended up in the database. On the other hand, it’s an outage story with multiple examples of saturation.
Saturation is a phrase often used by the safety science researcher David Woods: it refers to a system that is reaching the limit of what it can handle. If you’ve done software operations work, I bet you’ve encountered resource exhaustion, which is an example of saturation.
Saturation plays a big role in Woods’s model of the adaptive universe. In particular, in socio-technical systems, people will adapt in order to reduce the risk of saturation. In this post, I’m going to walk Laura’s write-up, highlighting all of the examples of saturation and how the system adopted to it. I’m going purely from the text of the original write-up, which means I’ll likely get some things wrong here.
Slack runs their infrastructure on AWS. In the beginning, they (like, I presume, all small companies) started with a single AWS account. And, initially, this worked out well.

However, as Slack grew, it encountered it problems. Here’s a quote from Slack’s blog post Building the Next Evolution of Cloud Networks at Slack by Archie Gunasekara:
As our customer base grew and the tool evolved, we developed more services and built more infrastructure as needed. However, everything we built still lived in one big AWS account. This is when our troubles started. Having all our infrastructure in a single AWS account led to AWS rate-limiting issues, cost-separation issues, and general confusion for our internal engineering service teams.

The above quote makes reference to three different categories of saturation. The first is a traditional sort of limit we software folks think of: they were running into AWS rate limits associated with an individual AWS account.
The other two limits are cognitive: the system made it harder for humans to deal with separating out costs and, it led to confusion for internal teams. I still see these as a form of saturation: as a system gets more difficult for humans to deal with, it effectively increases the cost of using the system, and it makes errors more likely.
And so, the Slack Cloud Engineering team adapted to meet this saturation risk by adopting AWS child accounts. From the linked blog post again:
Now the service teams could request their own AWS accounts and could even peer their VPCs with each other when services needed to talk to other services that lived in a different AWS account.

With continued growth, they eventually reached saturation again. Once again, this was the “it’s getting too hard” sort of saturation:
Having hundreds of AWS accounts became a nightmare to manage when it came to CIDR ranges and IP spaces, because the mis-management of CIDR ranges meant that we couldn’t peer VPCs with overlapping CIDR ranges. This led to a lot of administrative overhead.
To deal with this risk of saturation, the cloud engineering team adapted again. They reached for new capabilities: AWS shared VPCs and AWS Transit Gateway Inter-Region Peering. By leveraging these technologies, they were able to design a network architecture that addressed their problems:
This solved our earlier issue of constantly hitting AWS rate limits due to having all our resources in one AWS account. This approach seemed really attractive to our Cloud Engineering team, as we could manage the IP space, build VPCs, and share them with our child account owners. Then, without having to worry about managing any of the overhead of setting up VPCs, route tables, or network access lists, teams were able to utilize these VPCs and build their resources on top of them.
Fast forward several months later. From Laura Nolan’s post:
On January 4th, one of our Transit Gateways became overloaded. The TGWs are managed by AWS and are intended to scale transparently to us. However, Slack’s annual traffic pattern is a little unusual: Traffic is lower over the holidays, as everyone disconnects from work (good job on the work-life balance, Slack users!). On the first Monday back, client caches are cold and clients pull down more data than usual on their first connection to Slack. We go from our quietest time of the whole year to one of our biggest days quite literally overnight. Our own serving systems scale quickly to meet these kinds of peaks in demand (and have always done so successfully after the holidays in previous years). However, our TGWs did not scale fast enough.

This is as clear an example of saturation as you can get: the incoming load increased faster than the transit gateways were able to cope. What’s really fascinating from this point on is the role that saturation plays in interactions with the rest of the system.
As too many of us know, clients experience a saturated network as an increase in latency. When network latency goes up, the threads in a service spend more of their time sitting there waiting for the bits to come over the network, which means that CPU utilization goes down.
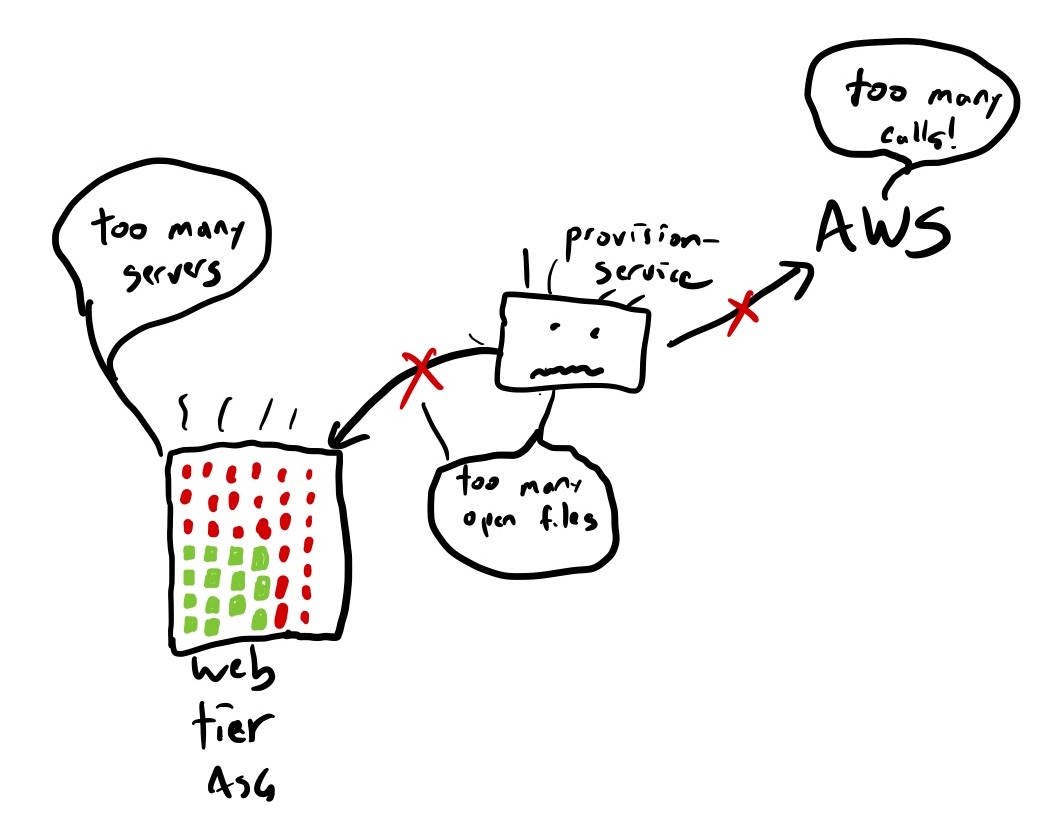
Slack’s web tier autoscales on CPU utilization, so when the network started dropping packets, the instances in the web tier spent more of their time blocked, and CPU went down, which triggered the AWS autoscaler to downscale the web tier.

However, the web tier has a scaling policy that rapidly upscales if thread utilization gets too high. (At Netflix, we use the term hammer rule to describe these type of emergency scale-up rule).

Once the new instances come online, an internal Slack service named provision-service is responsible for setting up these new instances so that they can serve traffic. And here, we see more saturation issues (emphasis mine).
Provision-service needs to talk to other internal Slack systems and to some AWS APIs. It was communicating with those dependencies over the same degraded network, and like most of Slack’s systems at the time, it was seeing longer connection and response times, and therefore was using more system resources than usual. The spike of load from the simultaneous provisioning of so many instances under suboptimal network conditions meant that provision-service hit two separate resource bottlenecks (the most significant one was the Linux open files limit, but we also exceeded an AWS quota limit).
While we were repairing provision-service, we were still under-capacity for our web tier because the scale-up was not working as expected. We had created a large number of instances, but most of them were not fully provisioned and were not serving. The large number of broken instances caused us to hit our pre-configured autoscaling-group size limits, which determine the maximum number of instances in our web tier.
Through a combination of robustness mechanisms (load balancer panic mode, retries, circuit breakers) and the actions of human operators, the system is restored to health.
As operators, we strive to keep our systems far from the point of saturation. As a consequence, we generally don’t have much experience with how the system behaves as it approaches saturation. And that makes these incidents much harder to deal with.
Making things worse, we can’t ever escape the risk of saturation. Often we won’t know that a limit exists until the system breaches it.

2 thoughts on “Slack’s Jan 2021 outage: a tale of saturation”