Imagine you’re walking around a university campus. It’s a couple of weeks after the spring semester has ended, and so there aren’t many people about. You enter a building and walk into one of the rooms. It appears to be some kind of undergraduate lab, most likely either physics or engineering.
In the lab, you come across a table. On the table, someone has balanced a rectangular block on its smallest end.

You nudge the top of the block. As expected, it falls over with a muted plonk. You look around to see if you might have gotten in trouble, but nobody’s around.
You come across another table. This table has some sort of track on it. The table also has a block on it that’s almost identical to the one on the other table, except that the block has a pin in it that connects it to some sort of box that is mounted on the track.

Not being able to resist, you nudge the top of this block, and it starts to fall. Then, the little box on the track whirs to life, moving along the track in the same direction that you nudged the block in. Because of the motion of the box, the block stays upright.
The ancient philosopher Aristotle believed that there were four distinct types of causes that explained why things happened. One of these is what Aristotle called the efficient cause: “Y behaved the way it did because X acted on Y“. For example, the red billiard ball moved because it was struck by the white ball. This is the most common way we think about causality today, and it’s sometimes referred to as linear causality.
Efficient cause does a good job of explaining the behavior of the first rectangular block in the anecdote: it fell over because we nudged it with our finger. But it doesn’t do a good job of explaining the observed behavior of the second rectangular block: we nudged it, and it started to fall, but it righted itself, and ended up balanced again.
Another type of cause Aristotle talked about was what he called the final cause. This is a teleological view of cause, which explains the behavior of objects in terms of their purpose or goal.
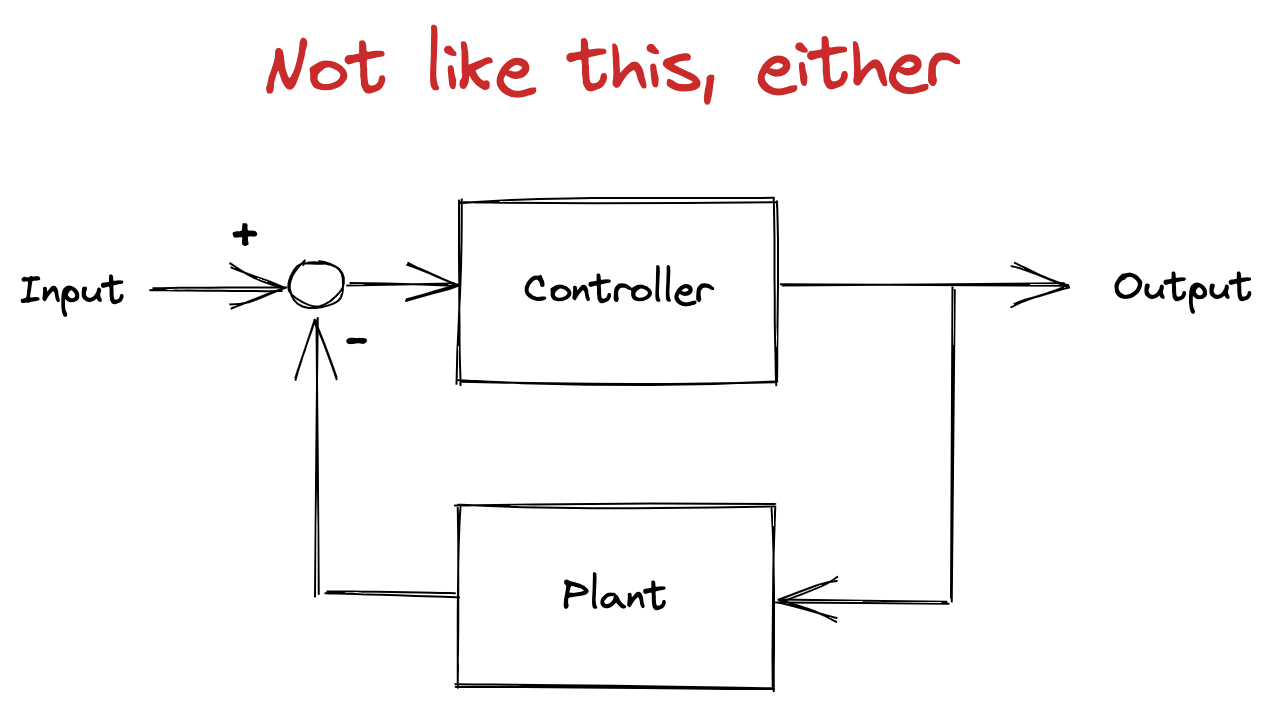
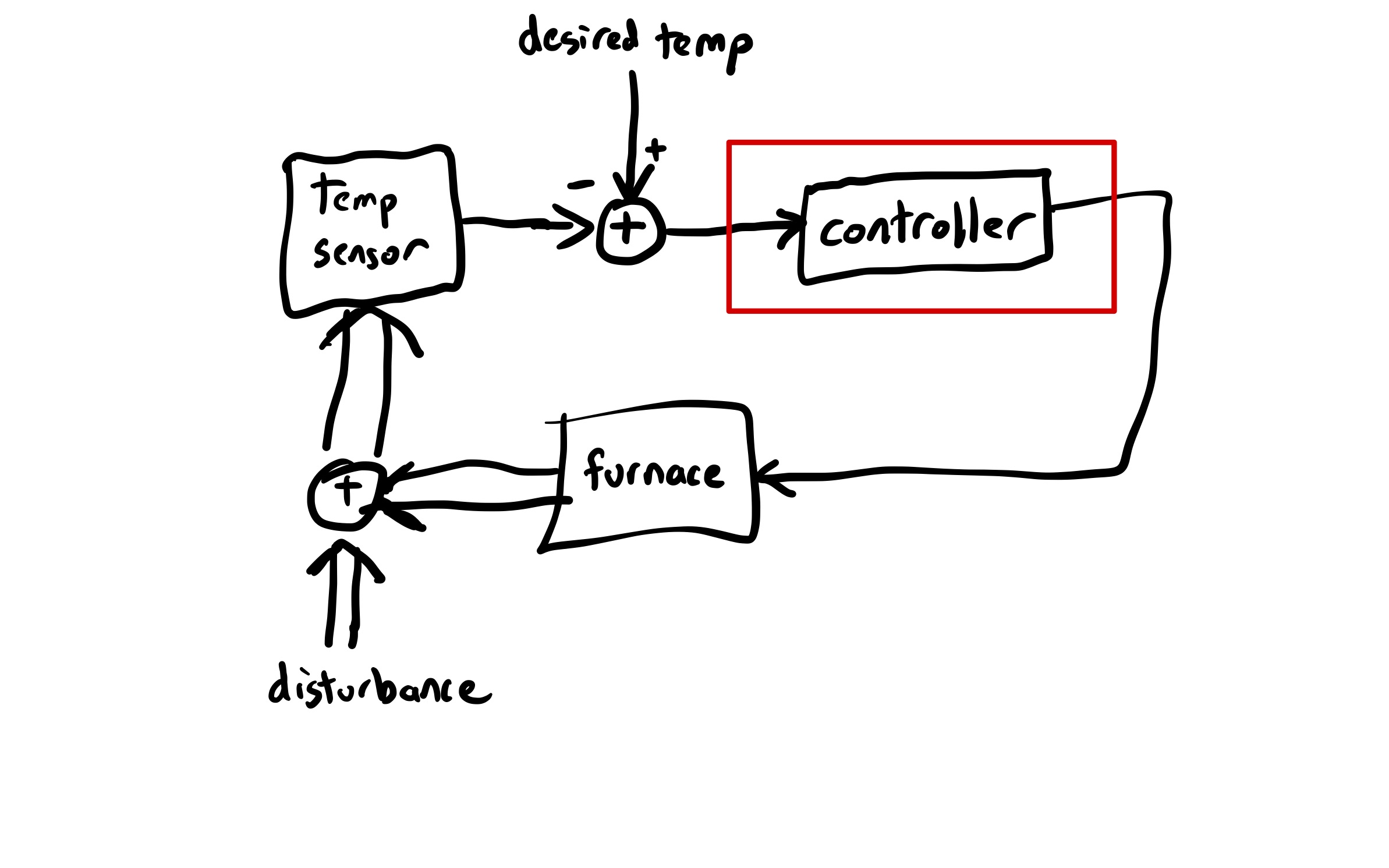
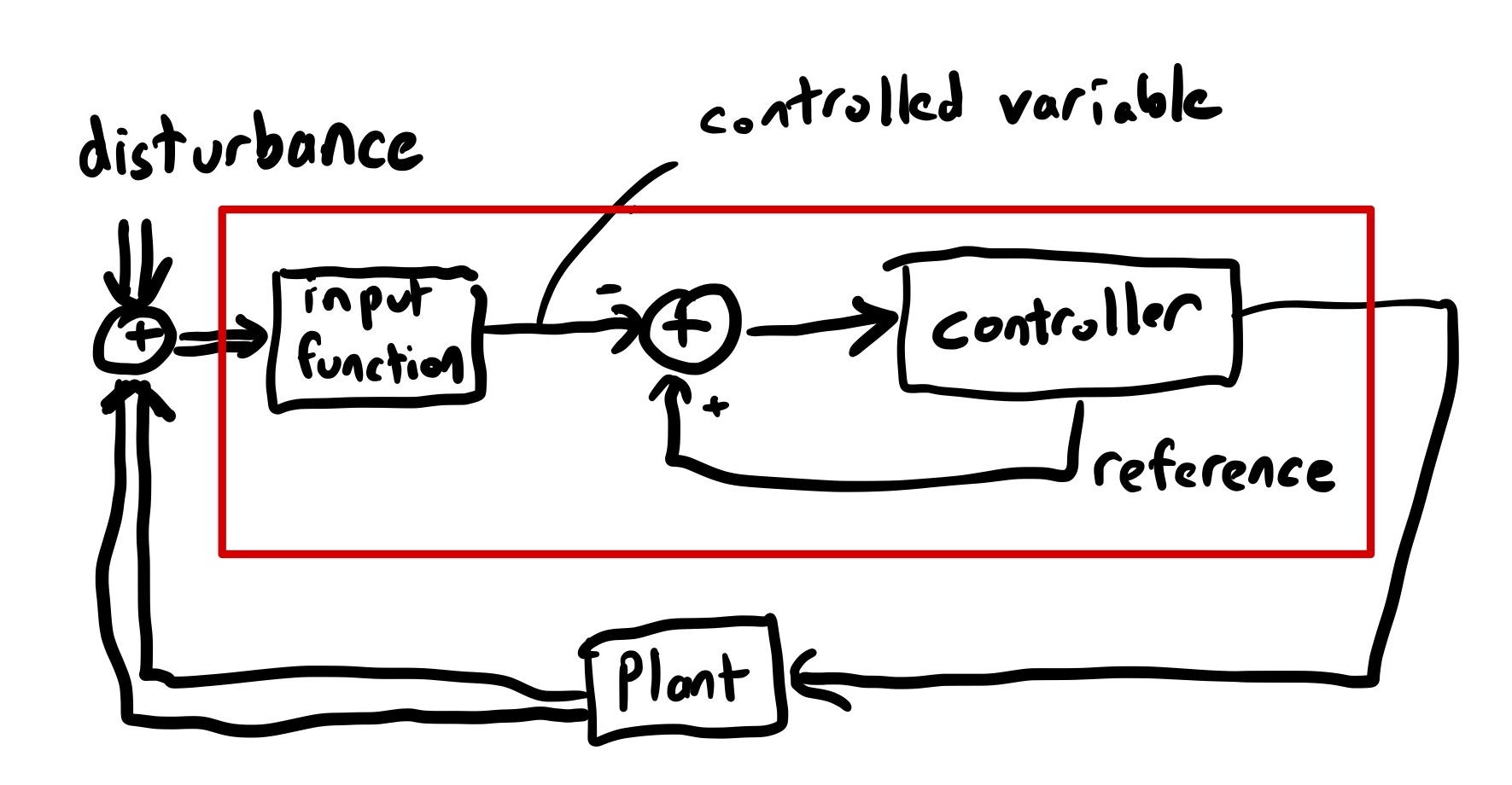
Final cause sounds like an archaic, unscientific view of the world. And, yet, reasoning with final cause enables us to explain the behavior of the second block more effectively than efficient cause does. That’s because the second block is being controlled by a negative-feedback system that was designed to keep the block balanced. The system will act to compensate for disturbances that could lead to the block falling over (like somebody walking over and nudging it). Because the output, a sensor that reads the angle of the block, is fed back into the input of the control system, the relationship between external disturbance and system behavior isn’t linear. This is sometimes referred to as circular causality, because of the circular nature of feedback loops.
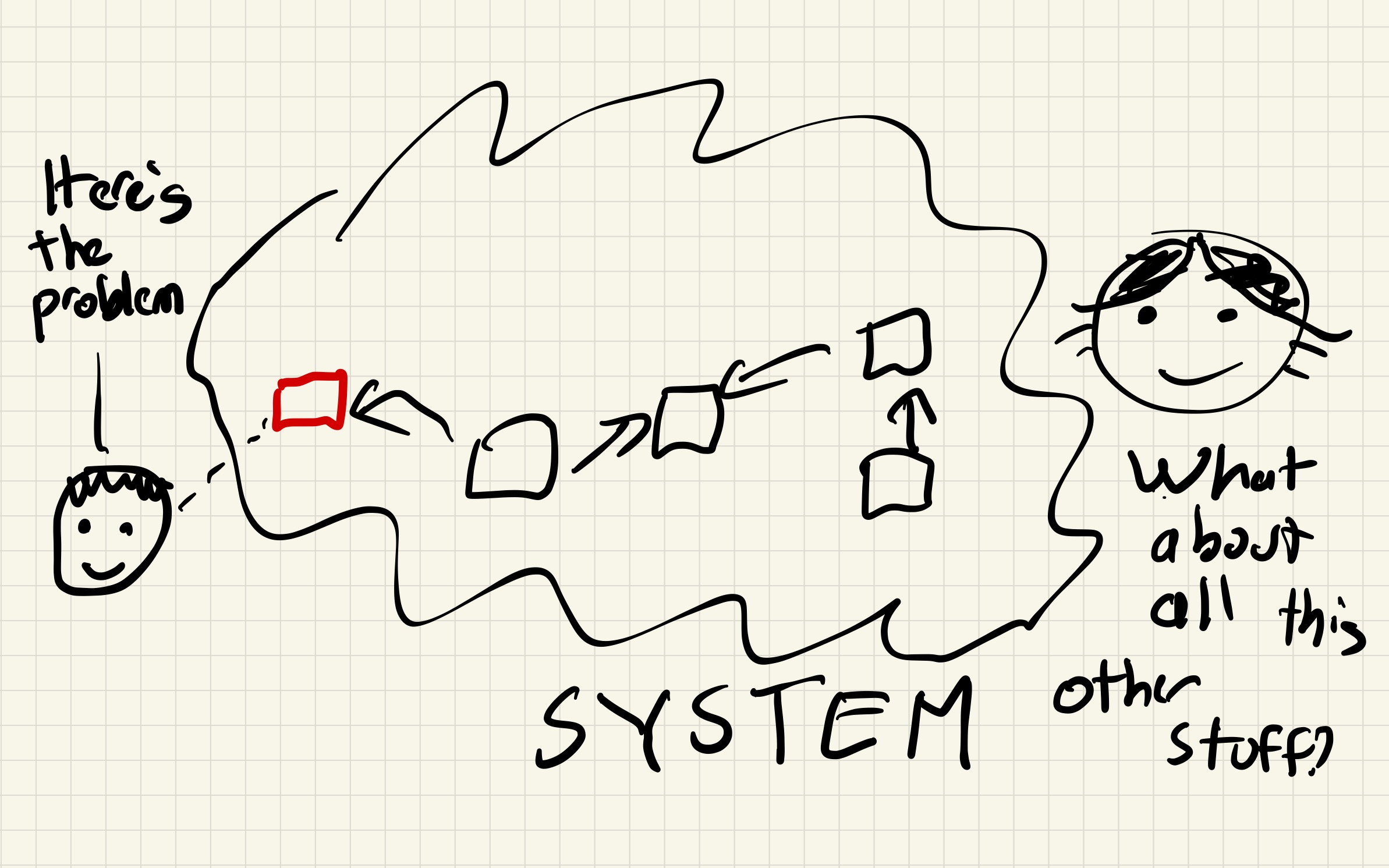
The systems that we deal with contain goals and feedback loops, just like the inverted pendulum control system that keeps the block balanced. If you try to use linear causality to understand a closed-loop system, you will be baffled by the resulting behavior. Only when you understand the goals that the system is trying to achieve, and the feedback loops that it uses to adjust its behavior to reach those goals, will the resulting behavior make sense.