I’m not a fan of talking about action items during incident reviews.
My whole shtick is that I believe updating people's mental models will have a more significant positive impact on the system than discussing action items, but boy is that a tough sell.
— @norootcause@hachyderm.io on mastodon (@norootcause) September 26, 2024
First, let’s talk about what an incident review is. It’s a meeting that takes place not too long after an incident has occurred, to discuss the incident. In many organizations, these meetings are open to any employee interested in attending, which means that these can have potentially large and varied audiences.
I was going to write “the goal of an incident review is…” in the paragraph above, but the whole purpose of this post is to articulate how my goals differ from other people’s goals.
My claims
Nobody fully understands how the system works. Once a company reaches a certain size, the software needs to get broken up across different teams. Ideally, the division is such that the teams are able to work relatively independent of each other. These are well-defined abstractions that lead to low coupling that we all prize in large-scale systems. As a consequence, there’s no single person who actually fully understands how the whole system works. It’s just too large and complex. And this actually understates the problem, given the complexity of the platforms we build on top of. Even if I’m the sole developer of a Java application, there’s a good chance that I don’t understand the details of the garbage collection behavior of the JVM I’m using.
The gaps in our understanding of how the system works contributes to incidents. Because we don’t have a full understanding of how the system works, we can’t ever fully reason about the impact of every single change that we make. I’d go so far as to say that, in every single incident, there’s something important that somebody didn’t know. That means that gaps in our understanding are dangerous in addition to being omnipresent.
The way that work is done profoundly affects incidents, both positively and negatively, butthat work is mostly invisible. Software systems are socio-technical systems, and the work that the people in your organization do every day is part of how the system works. This day-to-day work enables, trigger, exacerbate, prevent, lessen, and remediate incidents. And sometimes the exact same work in one context will prevent an incident and in another context will enable an incident! However, we generally don’t see what the real work is like. I’m lucky if my teammates have any sense of what my day-to-day work looks like, including how I use the internal tools to accomplish this work. The likelihood that people on other teams know how I do this work is close to zero. Even the teams that maintain the internal tooling have few opportunities to see this work directly.
Incident reviews are an opportunity for many people to gain insight into how the system works. An incident review is an opportunity to examine an aspect of the socio-technical system in detail. It’s really the only meeting of its kind where you can potentially have such a varied cross-section of the company getting into the nitty-gritty details of how things work. Incident reviews give us a flashlight that we get to shine on a dark corner of the system.
The best way to get a better understanding of how the system behaves is to look at how the system actually behaved. This phrasing should sound obvious, but it’s the most provocative of these claims. Every minute you spend discussing action items is a minute you are not spending learning more about how the system behaved. I feel similarly about discussing counterfactuals (if there had been an alert…). These discussions take the focus away from how the system actually behaved, and enter a speculative world about how the system might behave under a different set of circumstances.
We don’t know what other people don’t know We all have incomplete, out-of-date models of how the system works, that includes our models of other people’s models! That means that, in general, we don’t know what other people don’t know about the system. We don’t know in advance what people are going to learn that they didn’t know before!
There are tight constraints on incident review meetings. There is a fixed amount of time in an incident review meeting, which means that every minute spend on topic X means one less minute to spend discussing topic Y. Once that meeting is over, the opportunity of bringing in this group of people together to update their mental models is now gone.
Action item discussions are likely to be of interest to a smaller fraction of the audience. This is a very subjective observation, but my theory is that people tend to find that incident reviews don’t have a lot of value precisely because they focus too much of the time on discussing action items, and the details of the proposed action items are of potential interest to only a very small subset of the audience.
Teams are already highly incentivized to implement action items that prevent recurrence. Often I’ll go to an incident review, and there will be mention of multiple action items that have already been completed. As an observer, I’ve never learned anything from hearing about these.
A learning meeting will never happen later, but action items discussion will. There’s no harm in having an action item discussion in a future meeting. In fact, teams are likely to have to do this when they do their planning work for the next quarter. However, once the incident review meeting is over, the opportunity for having a learning-style meeting is gone, because the org’s attention is gone and off to the next thing.
More learning up-front will improve the quality of action items. The more you learn about the system, the better your proposed action items are likely to be. But the reverse isn’t true.
Why not do both learning and action items during an incident review?
Hopefully the claims above address the question of why not do both activities. There’s a finite amount of time in an incident review meeting, which means there’s a fundamental tradeoff between time spent learning and time spent discussing action items, and I believe that devoting the entire time to learning will maximize the return-on-investment of the meeting. I also believe that additional action item discussions are much more likely to be able to happen after the incident review meeting, but that learning discussions won’t.
Why I think people emphasize action items
Here’s my mental model as to why I think people are so keen on emphasizing action items as the outcome of a meeting.
Learning is fuzzy, actions are concrete. An incident review meeting is an expensive meeting for an organization. Action items are a legible outcome of a meeting, they are an indicator to the organization that the meeting had value. The value of learning, of updated mental models, is invisible.
Incidents make orgs uncomfortable and action items reassure them. Incidents are evidence that we are not fully in control of our system, and action items make us feel like this uncomfortable uncertainty has been addressed.
Back in August, Murat Derimbas published a blog post about the paper by Herlihy and Wing that first introduced the concept of linearizability. When we move from sequential programs to concurrent ones, we need to extend our concept of what “correct” means to account for the fact that operations from different threads can overlap in time. Linearizability is the strongest consistency model for single-object systems, which means that it’s the one that aligns closest to our intuitions. Other models are weaker and, hence, will permit anomalies that violate human intuition about how systems should behave.
Beyond introducing linearizability, one of the things that Herlihy and Wing do in this paper is provide an implementation of a linearizable queue whose correctness cannot be demonstrated using an approach known as refinement mapping. At the time the paper was published, it was believed that it was always possible to use refinement mapping to prove that one specification implemented another, and this paper motivated Leslie Lamport and Martín Abadi to propose the concept of prophecyvariables.
I have long been fascinated by the concept of prophecy variables, but when I learned about them, I still couldn’t figure out how to use them to prove that the queue implementation in the Herlihy and Wing paper is linearizable. (I even asked Leslie Lamport about it at the 2021 TLA+ conference).
Recently, Lamport published a book called The Science of Concurrent Programs that describes in detail how to use prophecy variables to do the refinement mapping for the queue in the Herlihy and Wing paper. Because the best way to learn something is to explain it, I wanted to write a blog post about this.
In this post, I’m going to assume that readers have no prior knowledge about TLA+ or linearizability. What I want to do here is provide the reader with some intuition about the important concepts, enough to interest people to read further. There’s a lot of conceptual ground to cover: to understand prophecy variables and why they’re needed for the queue implementation in the Herlihy and Wing paper requires an understanding of refinement mapping. Understanding refinement mapping requires understanding the state-machine model that TLA+ uses for modeling programs and systems. We’ll also need to cover what linearizability actually is.
We’ll going to start all of the way at the beginning: describing what it is that a program should do.
What does it mean for a program to be correct?
Think of an abstract data type (ADT) such as a stack, queue, or map. Each ADT defines a set of operations. For a stack, it’s push and pop , for a queue, it’s enqueue and dequeue, and for a map, it’s get, set, and delete.
Let’s focus on the queue, which will be a running example throughout this blog post, and is the ADT that is the primary example in the linearizability paper. Informally, we can say that dequeue returns the oldest enqueued value that has not been dequeued yet. It’s sometimes called a “FIFO” because it exhibits first-in-first-out behavior. But how do we describe this formally?
Think about how we would test that a given queue implementation behaves the way we expect. One approach is write a test that consists of a history of enqueue and dequeue operations, and check if our queue returns the expected values.
Here’s an example of an execution history, where enq is the enqueue operation and deq is the dequeue operation. Here I assume that enq does not return a value.
If we have a queue implementation, we can make these calls against our implementation and check that, at each step in the history, the operation returns the expected value, something like this:
Of course, a single execution history is not sufficient to determine the correctness of our queue implementation. But we can describe the set of every possible valid execution history for a queue. The size of this set is infinite, so we can’t explicitly specify each history like we did above. But we can come up with a mathematical description of the set of every possible valid execution history, even though it’s an infinite set.
Specifying valid execution histories: the transition-axiom method
In order to specify how our system should behave, we need a way of describing all of its valid execution histories. We are particularly interested in a specification approach that works for concurrent and distributed systems, since those systems have historically proven to be notoriously difficult for humans to reason about.
In the 1980s, Leslie Lamport introduced a specification approach that he called the transition-axiom method. He later designed TLA+ as a language to support specifying systems using the transition-axiom method.
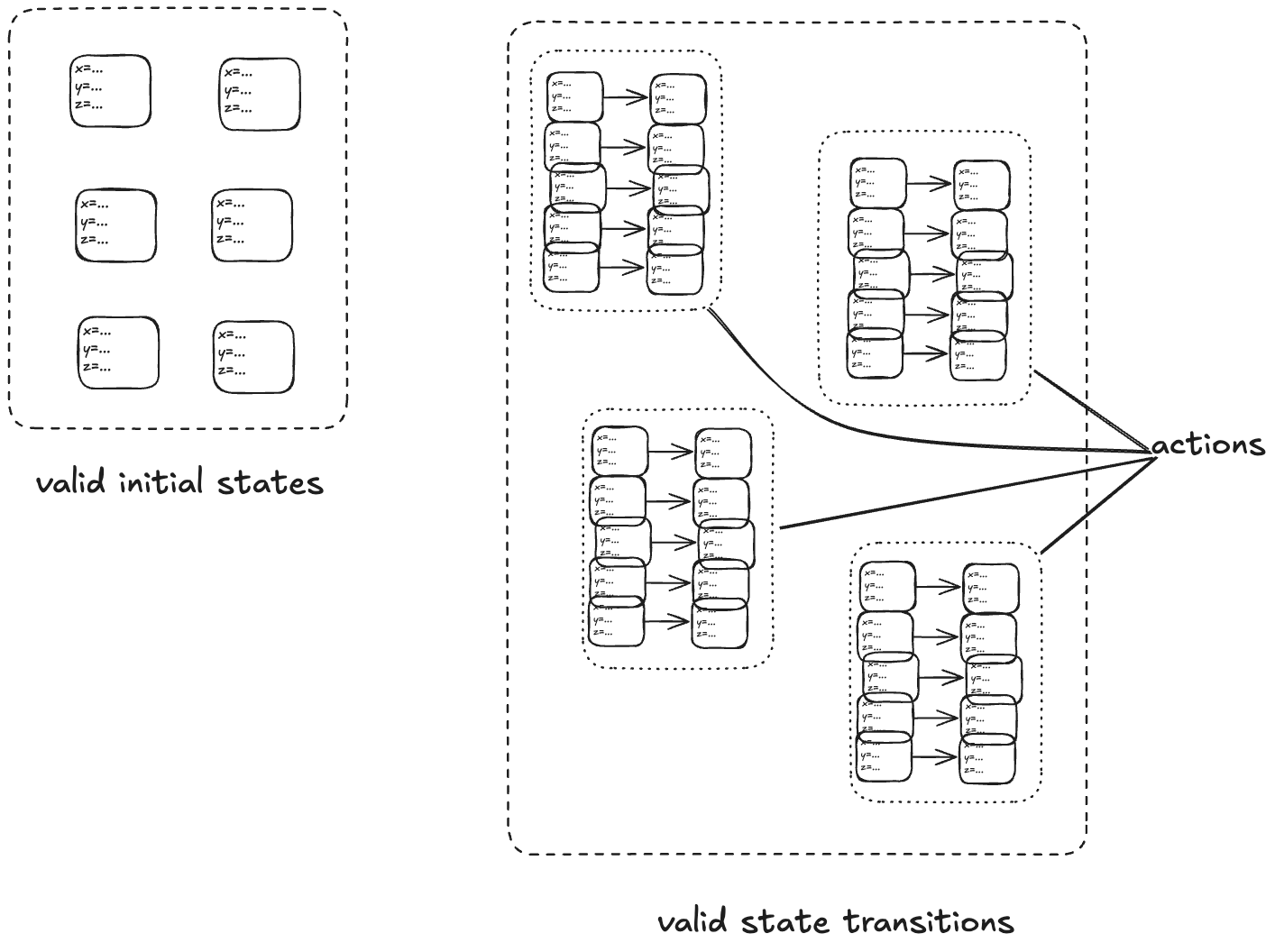
The transition-axiom method uses a state-machine model to describe a system. You describe a system by describing:
The set of valid initial states
The set of valid state transitions
(Aside: I’m not covering the more advanced topic of livenessin this post).
A set of related state transitions is referred to as an action. We use actions in TLA+ to model the events we care about (e.g., calling a function, sending a message).
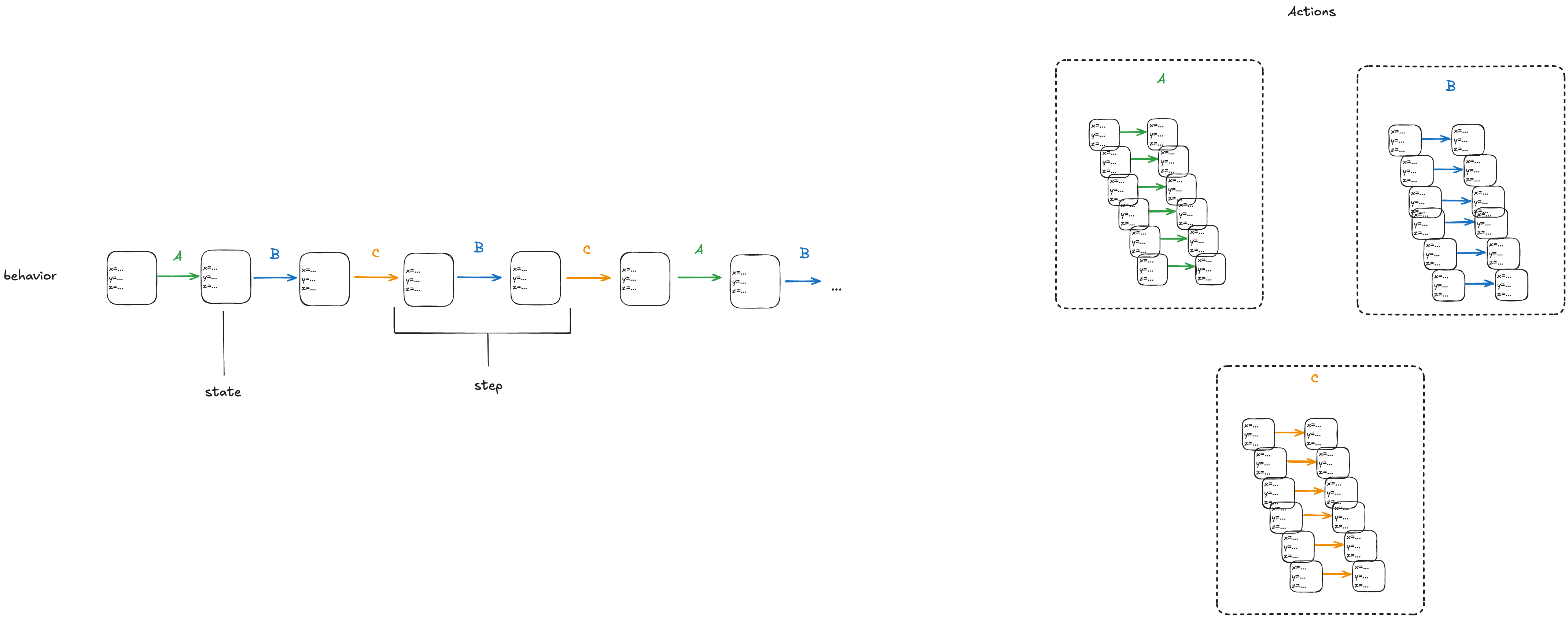
With a state-machine description, we can generate all sequences that start at one of the initial states and transition according to the allowed transitions. A sequence of states is called a behavior. A pair of successive states is called a step.
Each step in a behavior must be a member of one of the actions. In the diagram above, we would call the first step an A-step because it is a step that is a member of the A action.
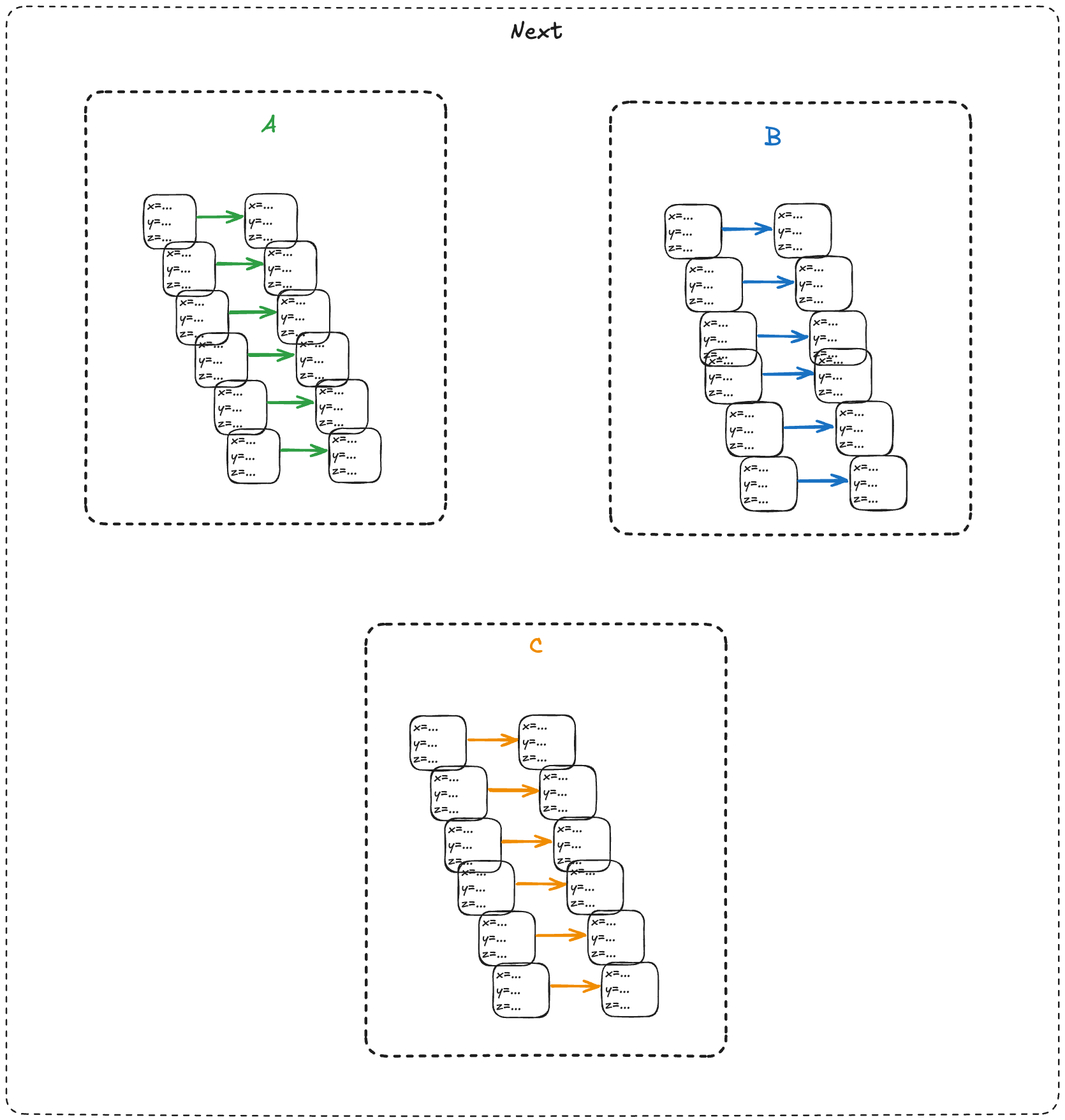
We refer to the set that includes all of the actions as the next-state action, which is typically called Next in TLA+ specifications.
In the example above, we would say that A, B, C are sub-actions of the Next action.
We call the entire state-machine description a specification: it defines the set of all allowed behaviors.
To make things concrete, let’s start with a simple example: a counter.
You think distributed systems is about trying to accomplish complex tasks, and then you read the literature and it's like "consider the problem of incrementing a counter", and it turns out that distributed systems is about how the simplest tasks become mind-bogglingly complex. https://t.co/4O2jfgfGQV
— @norootcause@hachyderm.io on mastodon (@norootcause) May 21, 2020
Modeling a counter with TLA+
Consider a counter abstract data type, that has only two operations:
inc – increment the counter
get – return the current value of the counter
reset – return the value of the counter to zero
Here’s an example execution history.
inc()
inc()
get() → 2
get() → 2
reset()
get() → 0
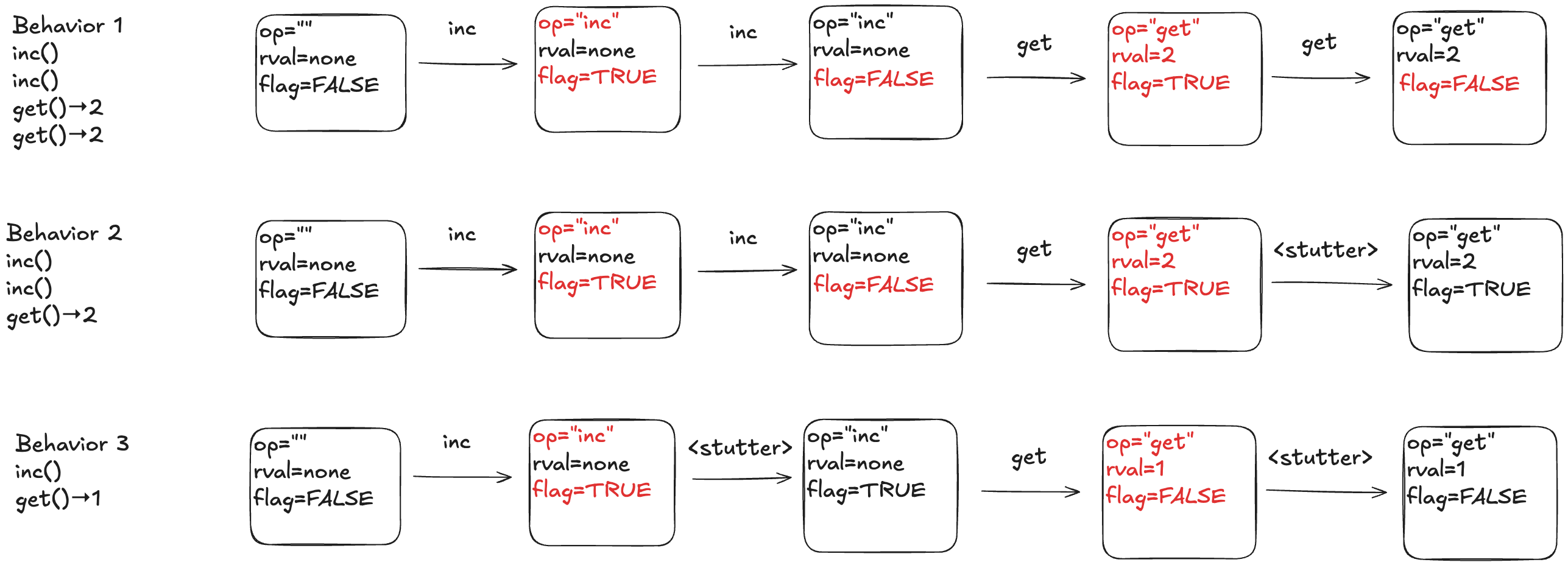
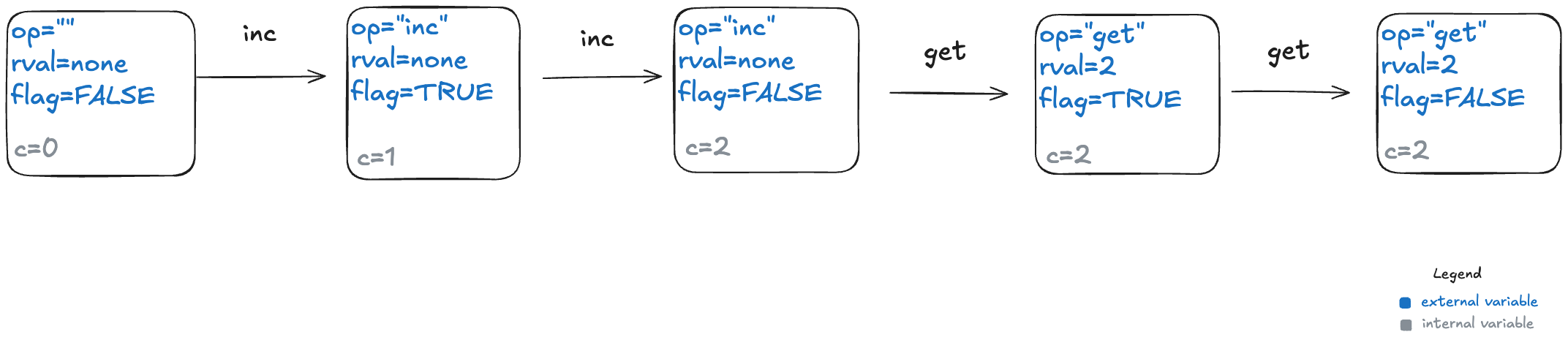
To model this counter in TLA+, we need to model the different operation types (inc, get, reset). We also need to model the return value for the get operation. I’ll model the operation with a state variable named op, and the return value with a state variable named rval.
But there’s one more thing we need to add to our model. In a state-machine model, we model an operation using one or more state transitions (steps) where at least one variable in the state changes. This is because all TLA+ models must allow what are called stuttering steps, where you have a state transition where none of the variables change.
This means we need to distinguish between two consecutive inc operations versus an inc operation followed by a stuttering step where nothing happens.
To do that, I’ll add a third variable to my model, which I’ll unimaginatively call flag. It’s a boolean variable, which I will toggle every time an operation happens. To sum up, my three state variables are:
op – the operation (“inc”, “get”, “reset”), which I’ll initialize to “” (empty string) in the first state
rval – the return value for a get operation. It will be a special value called none for all of the other operations
flag – a boolean that toggles on every (non-stuttering) state transition.
Below is a depiction of an execution history and how this would be modeled as a behavior at TLA+. The text in red indicated which variable changed in the transition. As mentioned above, every transition associated with an operation must have at least one variable that changes value.
Here’s a visual depiction of an execution history. Note how each event in the history is modeled as a step (pair of states) where at least one variable changes.
To illustrate why we need the extra variables, consider the following three behaviors.
In behavior 1, there are no stuttering steps. In behavior 2, the last step is a stuttering step, so there is only one “get” invocation. In behavior 3, there are two stuttering steps.
The internal variables
Our model of a counter so far has defined the external variables, which are the only variables that we really care about as the consumer of a specification. If you gave me a set of all of the valid behaviors for a queue, where behaviors were described using only these external behaviors, that’s all I need to understand how a queue behaves.
However, the external variables aren’t sufficient for the producer of a specification to actually generate the set of valid behaviors. This is because we need to keep track of some additional state information: how many increments there have been since the last reset. This type of variable is known as an internal state variable. I’m going to call this particular internal state variable c.
Here’s behavior 1, with different color codings for the external and internal variables.
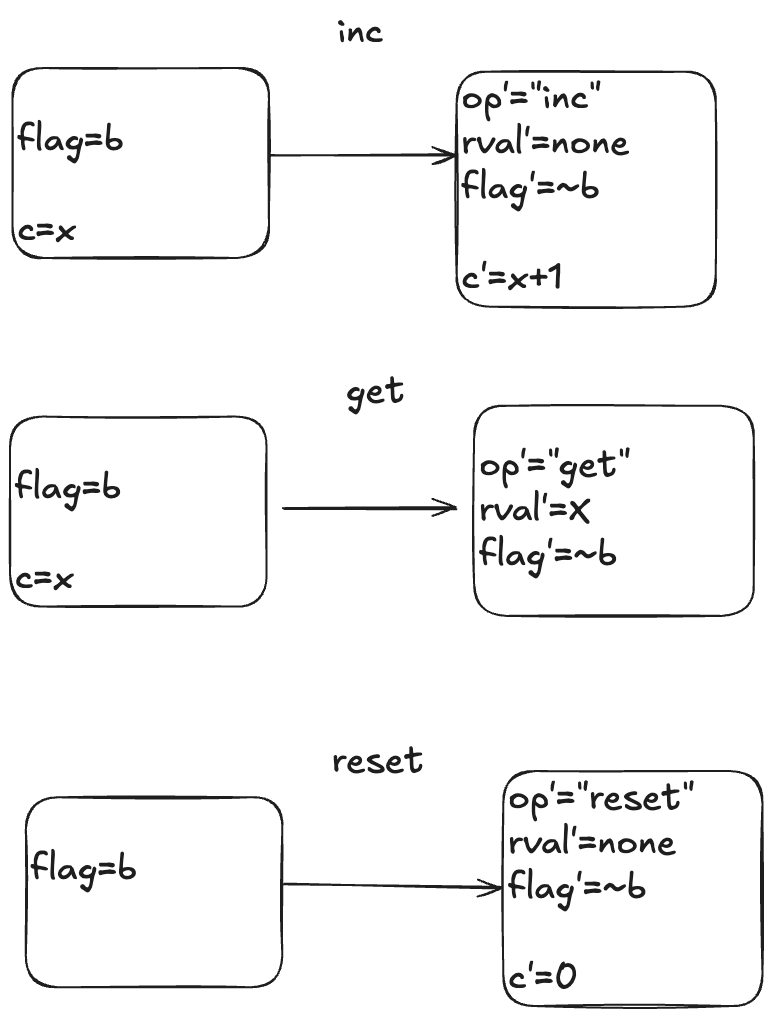
The actions
Here is a visual depiction of the permitted state transitions. Recall the set of permitted state transitions is called an action. For our counter, there are three actions, which corresponds to the three different operations we model: inc, get, and reset.
Each transition is depicted as two boxes with variables in it. The left-hand box shows the values of the variables before the state transition, and the right-hand box shows the values of the variables after the state transition. By convention we add a prime (‘) to the variables to refer to their values after the state transition.
While the diagram depicts three actions, each action describes a set of allowed state transitions. As an example, here are two different state transitions that are both members of the inc set of permitted transitions.
[flag=TRUE, c=5] → [flag=FALSE, c=6]
[flag=TRUE, c=8]→ [flag=FALSE, c=9]
In TLA+ terminology, we call these two steps inc steps. Remember: in TLA+, all of the action is in the actions. We use actions (sets of permitted state transitions) to model the events that we care about.
Modeling a queue with TLA+
We’ll move on to our second example, which will form the basis for the rest of this post: a queue. A queue supports two operations, which I’ll call enq (for enqueue) and deq (for dequeue).
Modeling execution histories as behaviors
Recall our example of a valid execution history for a queue:
enq("A")
enq("B")
deq() → "A"
enq("C")
deq() → "B"
We now have to model argument passing, since the enq operation takes an argument.
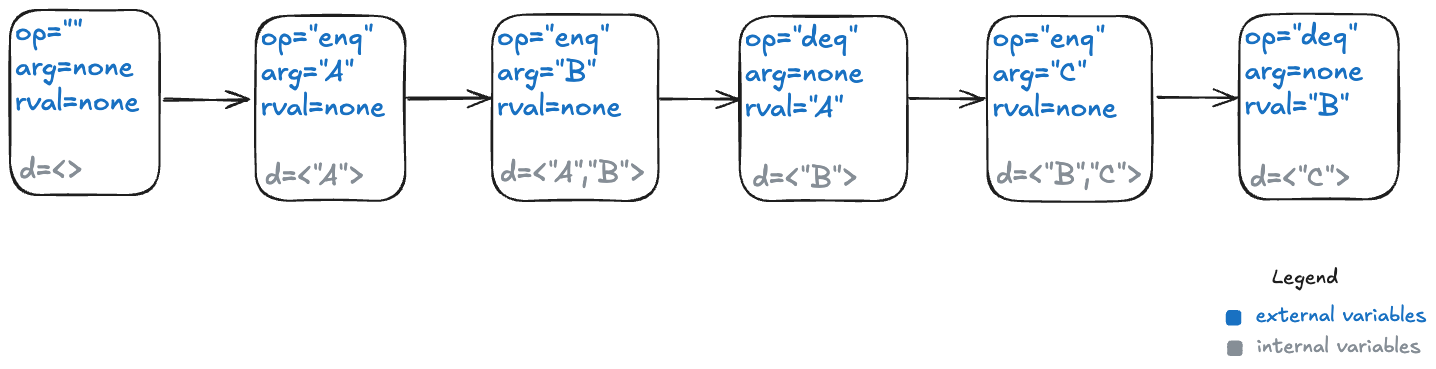
Here’s one way to model this execution history as a TLA+ behavior.
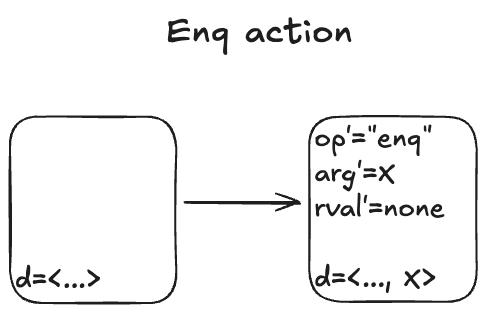
My model uses three state variables:
op – identifies which operation is being invoked (enq or deq)
arg – the argument being passed in the case of the enq operation
rval – the return value in the case of the deq operatoin
TLA+ requires that we specify a value for every variable in every state, which means we need to specify a value for arg even for the deq operation, which doesn’t have an argument, and a value for rval for the enq operation, which doesn’t return a value. I defined a special value called none for this case.
In the first state, when the queue is empty, I chose to set op to the empty string (“”) and arg and rval to none.
The internal variables
For a queue, we need to keep track all of the values that have previously been enqueued, as well as the order in which they were enqueued.
TLA+ has a type called a sequence which I’ll use to encode this information: a sequence is like a list in Python.
I’ll add a new variable which I’ll unimaginatively call d, for data. Here’s what that behavior looks like with the internal variable.
Modeling dequeues
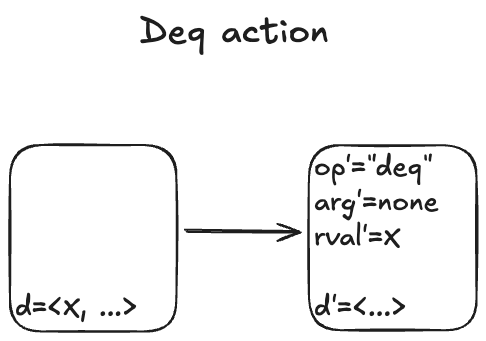
Recall that our queue supports two operations: enqueue and dequeue. We’ll start with the dequeue operation. I modeled it with an action called Deq.
Here are some examples of state transitions that are permitted by the Deq action. We call these Deq steps.
I’m not going to write much TLA+ code in this post, but to give you a feel for it, here is how you would write the Deq action in TLA+ syntax:
The syntax of the first line might be a bit confusing if you’re not familiar with TLA+:
# is TLA+ for ≠
<<>> is TLA+ for the empty sequence.
Modeling dequeues
Here’s what the Enq action looks like:
There’s non-determinism in this action: the value of arg’ can be any valid value that we are allowed to put onto the queue.
I’ll spend just a little time in this section to give you a sense of how you would use TLA+ to represent the simple queue model.
To describe the queue in TLA+, we define a set called Values that contains all of the valid values that could be enqueued, as well as a special constant named none that means “not a value”.
The complete description of our queue, its specification that describes all permitted behaviors, looks like this:
For completeness, here’s what the TLA+ specification looks like: (source in Queue.tla).
Init corresponds to our set of initial states, and Next corresponds to the next-state action, where the two sub-actions are Enq and Deq.
The last line, Spec, is the full specification. You can read this as: The initial state is chosen from the Init set of states, and every step is a Next step (every allowed state transition is a member of the set of state transitions defined by the Next action).
Modeling concurrency
In our queue model above, an enqueue or dequeue operation happens in one step (state transition). That’s fine for modeling sequential programs, but it’s not sufficient for modeling concurrent programs. In concurrent programs, the operations from two different threads can overlap in time.
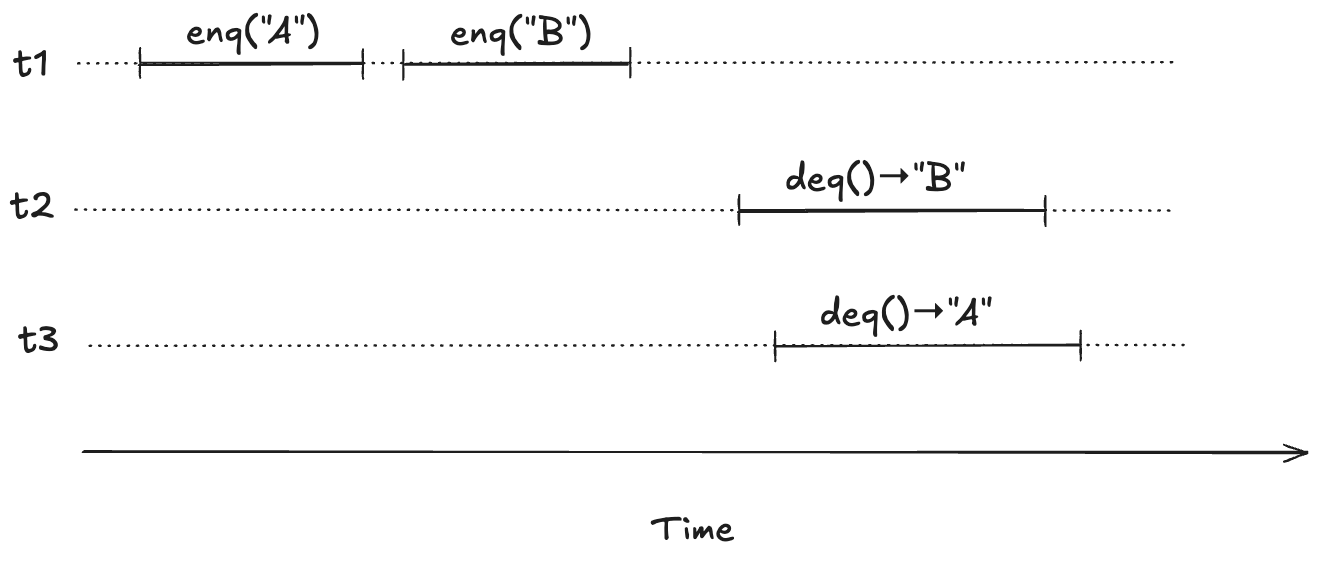
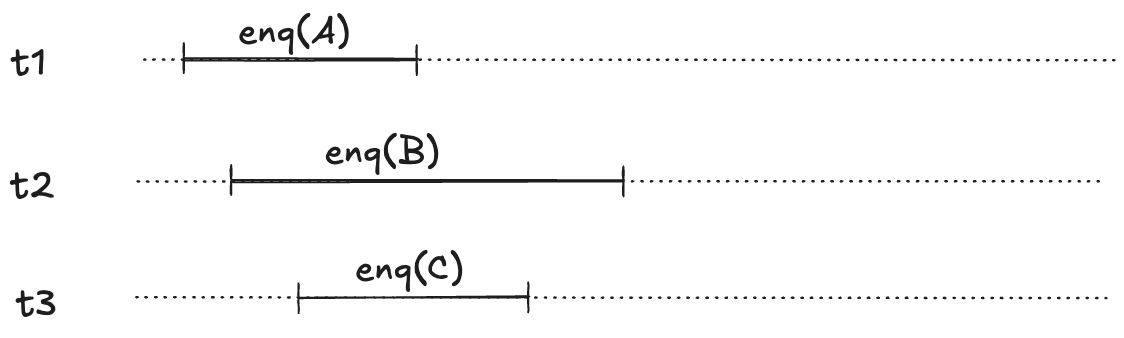
To illustrate, imagine a scenario where there are three threads, t1, t2, t3. First, t1 enqueues “A”, and “B”. Then, t2 and t3 both call dequeue, and those queries overlap in time.
We want to model concurrent executions using a state-machine model. The diagram above, shows the start and end time for each operation. But to model this behavior, we don’t actually care about the exact start and end times: rather, we only care about the relative order of the start and events.
We can model execution histories like the one above using state machines. We were previously modeling an operation in a single state transition (step). Now we will need to use two steps to model an operation: one to indicate when the operation starts and the other to indicate when the operate ends.
Because each thread acts independently, we need to model variables that are local to threads. And, in fact, all externally visible variables are scoped to threads, because each operation always happens in the context of a particular thread. We do this by changing the variables to be functions where the domain is a thread id. For example, where we previously had op=”enq” where op was always a string, now op is a function that takes a thread id as an argument. Now we would have op[t1]=”enq” where t1 is a thread id. (Functions in TLA+ use square brackets instead of round ones. you can think of these function variables as acting like dictionaries)
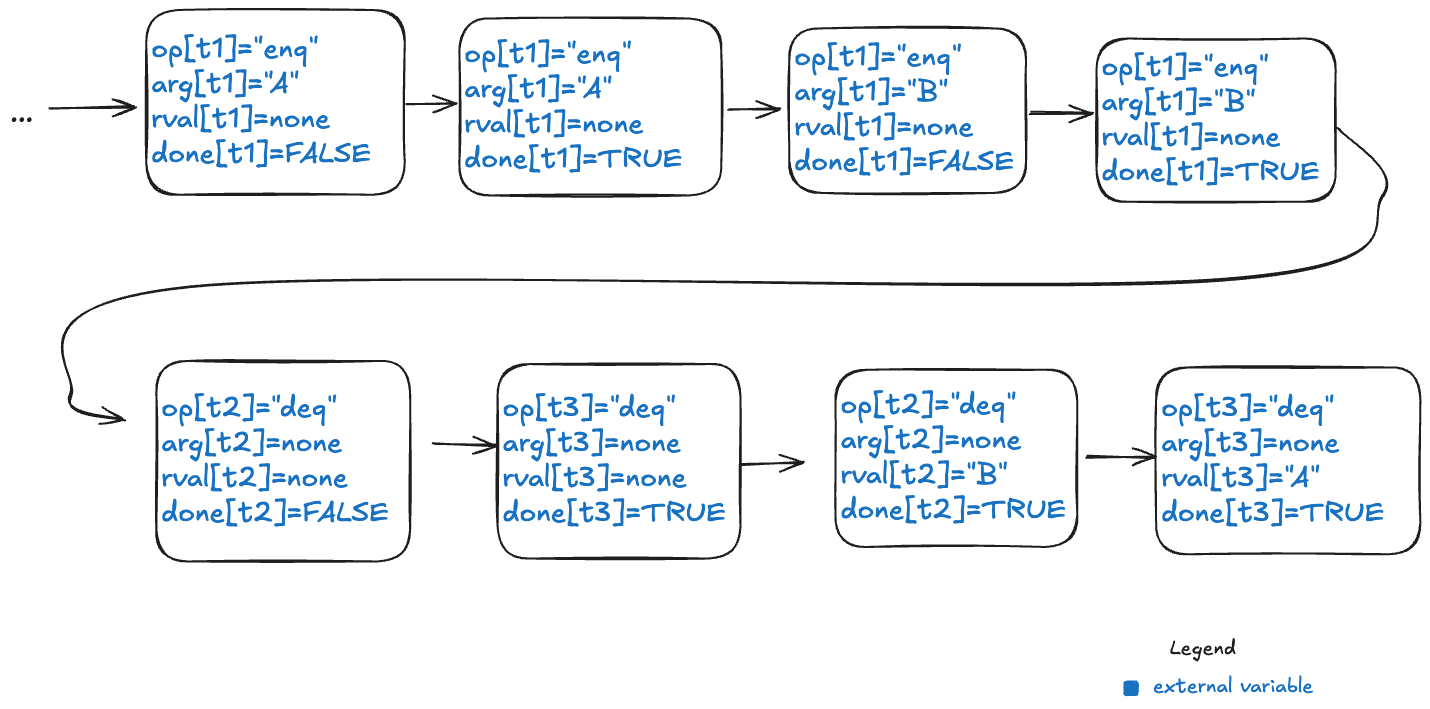
Here’s an example of a behavior that models the above execution history, showing only the external variables. Note that this behavior only shows the values that change in a state.
Note the following changes from the previous behaviors.
There is a boolean flag, done, which indicates when the operation is complete.
The variables are all scoped to a specific thread.
But what about the internal variable d?
Linearizability as correctness condition for concurrency
We know what it means for a sequential queue to be correct. But what do we want to consider correct when operations can overlap? We need to decide what it means for an execution history of a queue to be correct in the face of overlapping operations. This is where linearizability comes in. From the abstract of the Herlihy and Wing paper:
Linearizability provides the illusion that each operation applied by concurrent processes takes effect instantaneously at some point between its invocation and its response, implying that the meaning of a concurrent object’s operations can be given by pre- and post-conditions.
For our queue example, we say our queue is linearizable if, for every history where there are overlapping operations, we can identify a point in time between the start and end of the operation where the operation instantaneously “takes effect”, giving us a sequential execution history that is a correct execution history for a serial queue. This is a called a linearization. If every execution history for our queue has a linearization, then we say that our queue is linearizable.
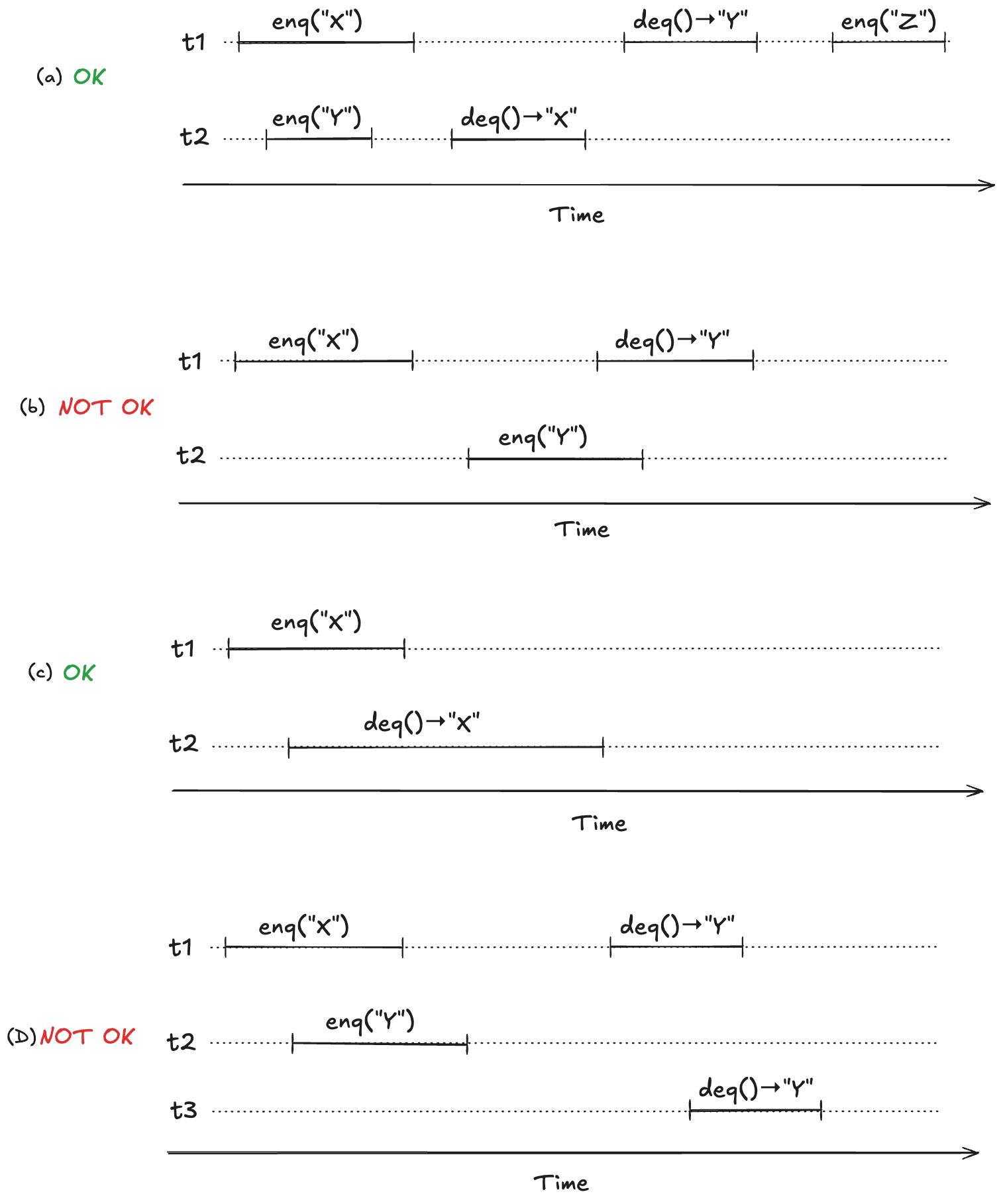
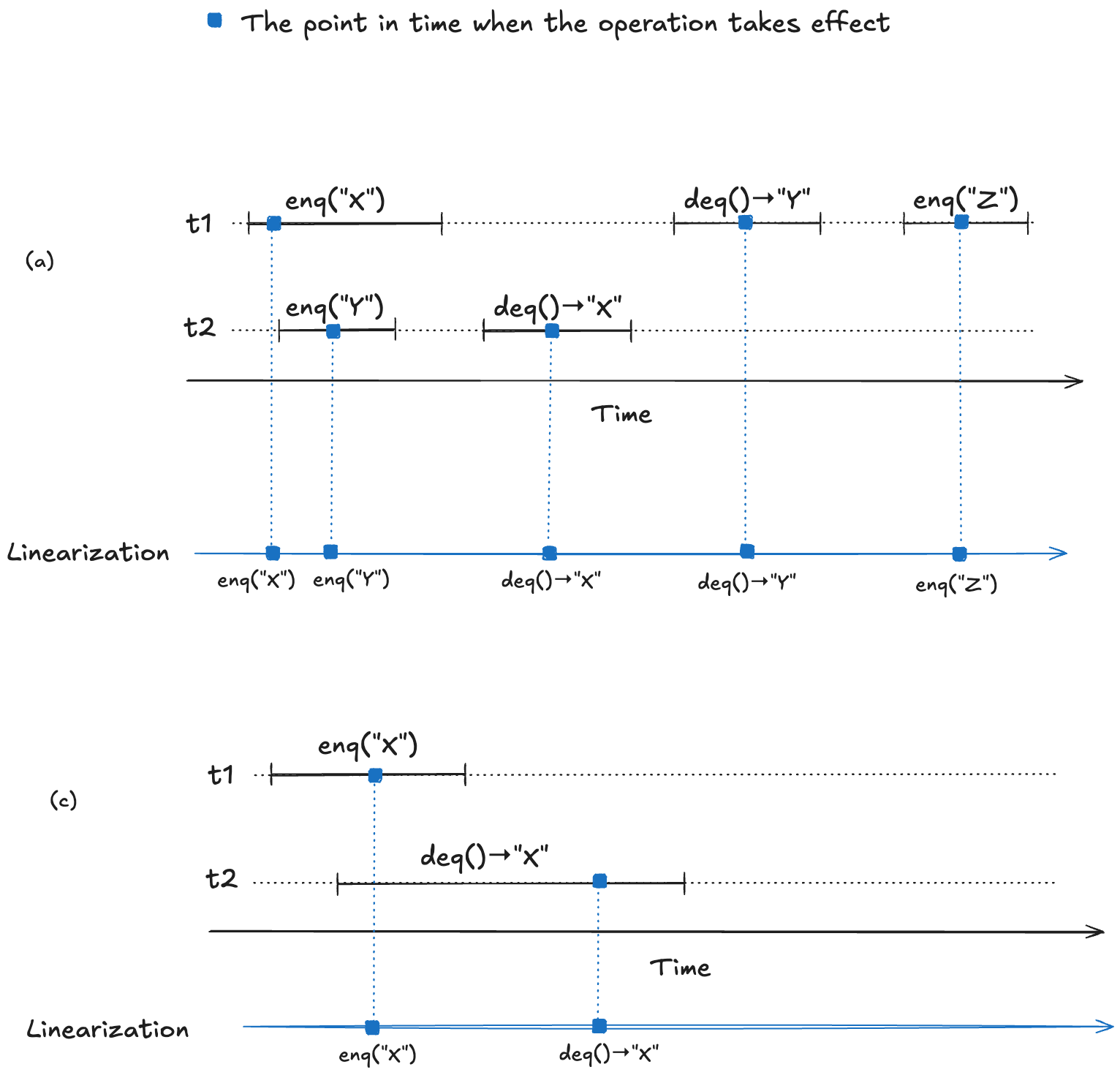
To make this concrete, consider the following four observed execution histories of a queue, labeled (a), (b), (c), (d), adapted from Fig. 1 of the Herlihy and Wing linearizable paper. Two of these histories are linearizable (they are labeled “OK”), and two are not (labeled “NOT OK”).
For (a) and (c), we can identify points in time during the operation where it appears as if the operation has instantaneously taken effect.
We now have a strict ordering of operations because there is no overlap, so we can write it as a sequential execution history. When the resulting sequential execution history is valid, it is called a linearization:
To repeat from the last section, a data structure is linearizable if, for every operation that executes on the data structure, we can identify a point in time between the start and the end of the operation where the operation takes effect.
We can model a linearizable queue by modeling each operation (enqueue/dequeue) as three actions:
Start (invocation) of operation
When the operation takes effect
End (return) of operation
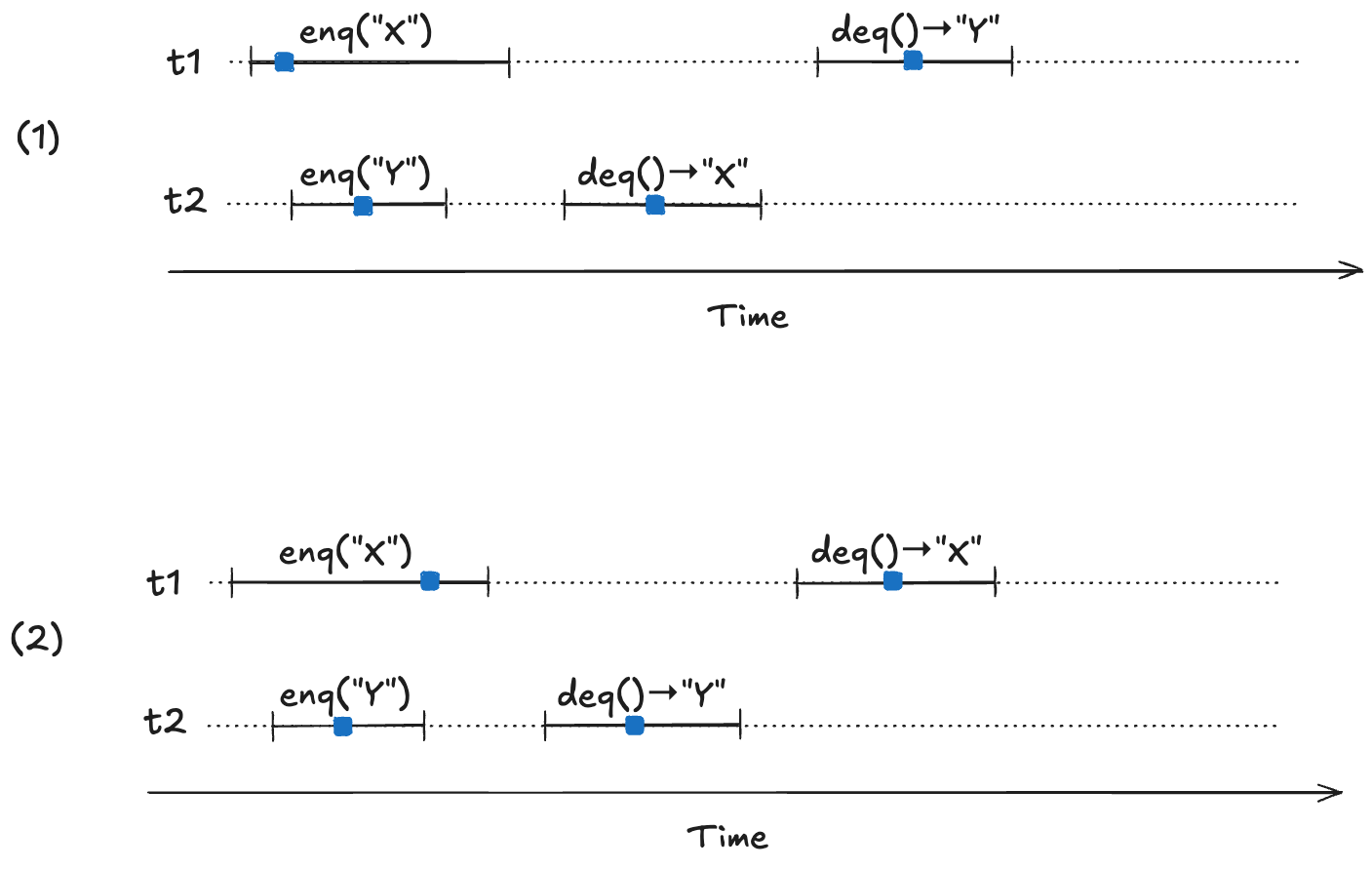
Our model needs to permit all possible linearizations. For example, consider the following two linearizable histories. Note how the start/end timings of the operations are identical in both cases, but the return values are different.
In (1) the first deq operation returns “X”, and in (2) the first deq operation “returns Y”. Yet they are both valid histories. The difference between the two is the order in which the enq operations take effect. In (1), enq(“X”) takes effect before enq(“Y”), and in (2), enq(“Y”) takes effect before enq(“X”). Here are the two linearizations:
Our TLA+ model of a linearizable queue will need to be able to model the relative order of when these operations take effect. This is where the internal variables come into play in our model: “taking effect” will mean updating internal variables of our model.
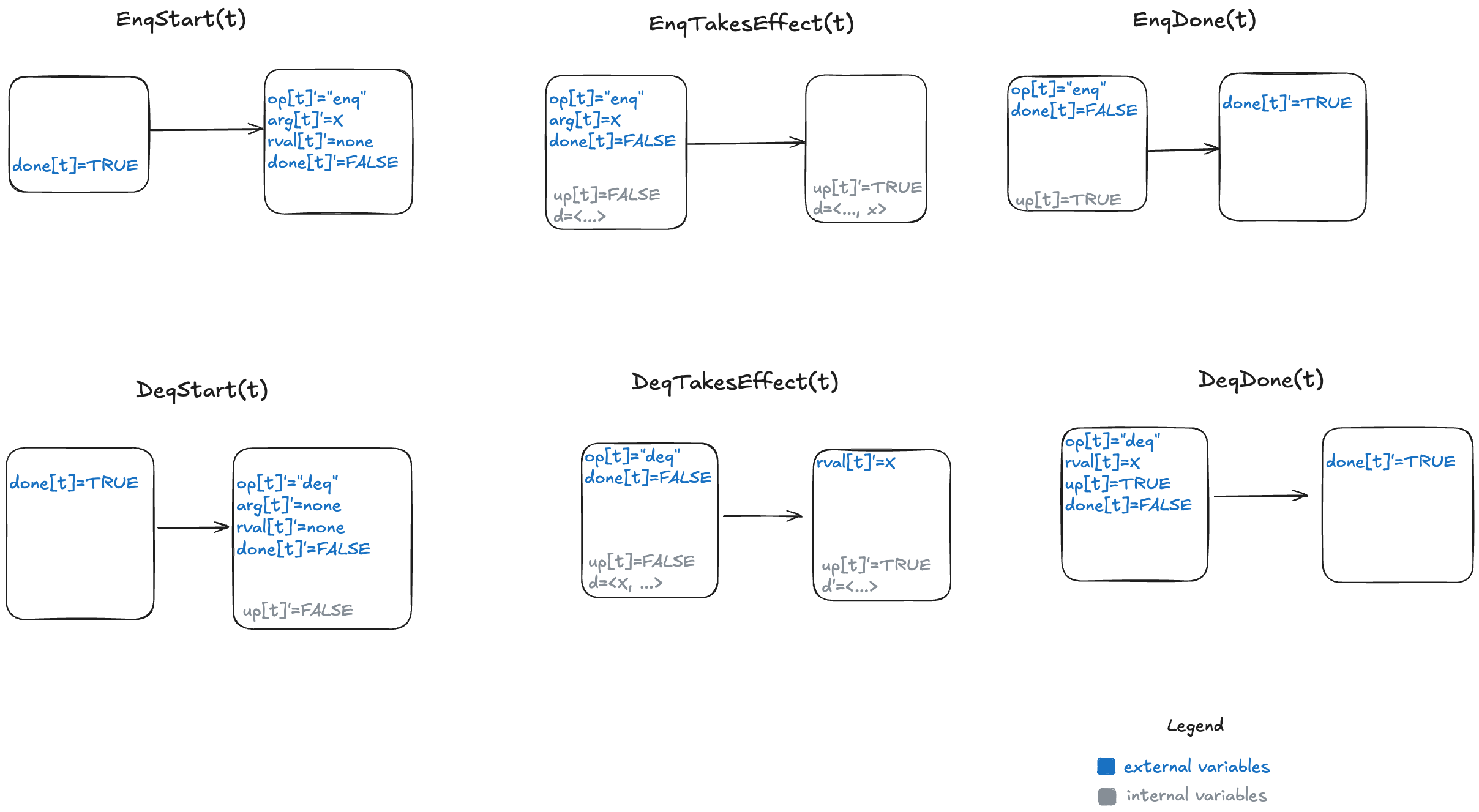
We need an additional variable to indicate whether the internal state has been updated or not for the current operation. I will call this variable up (for “updated”). It starts off as false when the operation starts, and is set to true when the internal state variable (d) has been updated.
Here’s a visual representation of the permitted state transitions (actions). As before, the left bubble shows the values that must be true in the first state for the transition to happen, and the second bubble shows which variables change.
Since we now have to deal with multiple threads, we parameterize our action by thread id (t). You can see the TLA+ model here: LinearizableQueue.tla.
We now have a specification for a linearizable queue, which is a description of all valid behaviors. We can use this to verify that a specific queue implementation is linearizable. To demonstrate, let’s shift gears and talk about an example of an implementation.
An example queue implementation
Let’s consider an implementation of a queue that:
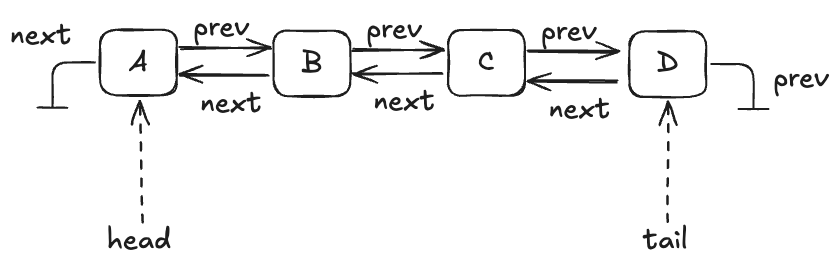
Stores the data in a doubly-linked list
Uses a lock to protect the list
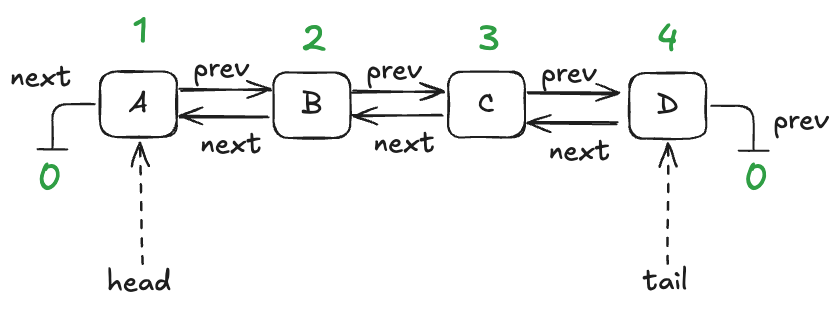
A queue with four entries looks like this:
Here’s an implementation of this queue in Python that I whipped up. I call it an “LLLQueue” for “locked-linked-list queue”. I believe that my LLLQueue is linearizable, and I’d like to verify this.
One way is to use TLA+ to build a specification of my LLLQueue, and then prove that every behavior of my LLLQueue is also a behavior of the LinearizableQueue specification. The way we do this is in TLA+ is by a technique called refinement mappings.
But, first, let’s model the LLLQueue in TLA+.
Modeling the LLLQueue in TLA+ (PlusCal)
In a traditional program, a node would be associated with a pointer or reference. I’m going to use numerical IDs for each node, starting with 1. I’ll use the value of 0 as a sentinel value meaning null.
We’ll model this with three functions:
vals – maps node id to the value stored in the node
prev – maps node id to the previous node id in the list
next – maps node id to the next node id in the list
Here are these functions in table form for the queue shown above:
node id
vals
1
A
2
B
3
C
4
D
The vals function
node id
prev
1
2
2
3
3
4
4
0 (null)
The prev function
node id
next
1
0 (null)
2
1
3
2
4
3
The next function
It’s easier for me to use PlusCal to model an LLLQueue than to do it directly in TLA+. PlusCal is a language for specifying algorithms that can be automatically translated to a TLA+ specification.
It would take too much space to describe the full PlusCal model and how it translates, but I’ll try to give a flavor of it. As a reminder, here’s the implementation of the enqueue method in my Python implementation.
Here’s what my PlusCal model looks like for the enqueue operation:
procedure enqueue(val)
variable new_tail;
begin
E1: acquire(lock);
E2: with n \in AllPossibleNodes \ nodes do
Node(n, val, tail);
new_tail := n;
end with;
E3: if IsEmpty then
head := new_tail;
else
prev[tail] := new_tail;
end if;
tail := new_tail;
E4: release(lock);
E5: return;
end procedure;
Note the labels (E1, E2, E3, E4, E5) here. The translator turns those labels into TLA+ actions (state transitions permitted by the spec). In my model, an enqueue operation is implemented by five actions.
Refinement mappings
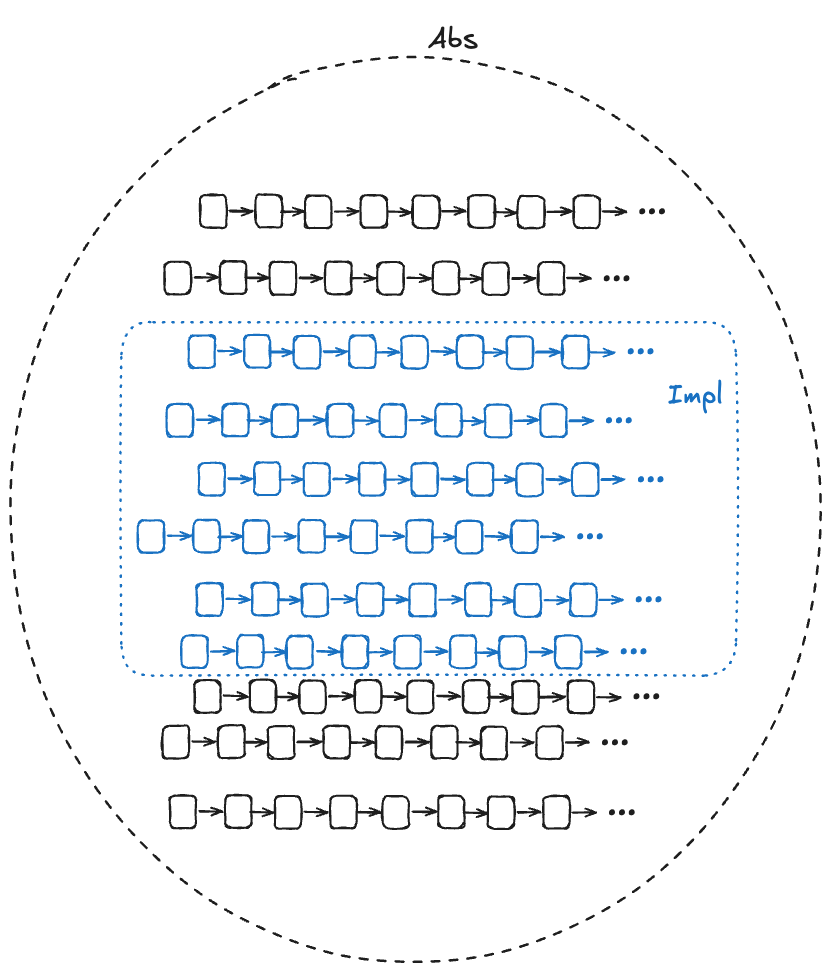
One of the use cases for formal methods is to verify that a (low-level) implementation conforms to a (higher-level) specification. In TLA+, all specs are sets of behaviors, so the way we do this is that we:
create a high-level specification that models the desired behavior of the system
create a lower-level specification that captures some implementation details of interest
show that every behavior of the low-level specification is among the set of behaviors of the higher-level specification, considering only the externally visible variables
In the diagram below, Abs (for abstract) represents the set of valid (externally visible) behaviors of a high-level specification, and Impl (for implementation) represents the set of valid (externally visible) behaviors for a low-level specification. For Impl to implement Abs, the Impl behaviors must be a subset of the Abs behaviors.
We want to be able to prove that Impl implements Abs. In other words, we want to be able to prove that every externally visible behavior in Impl is also an externally visible behavior in Abs.
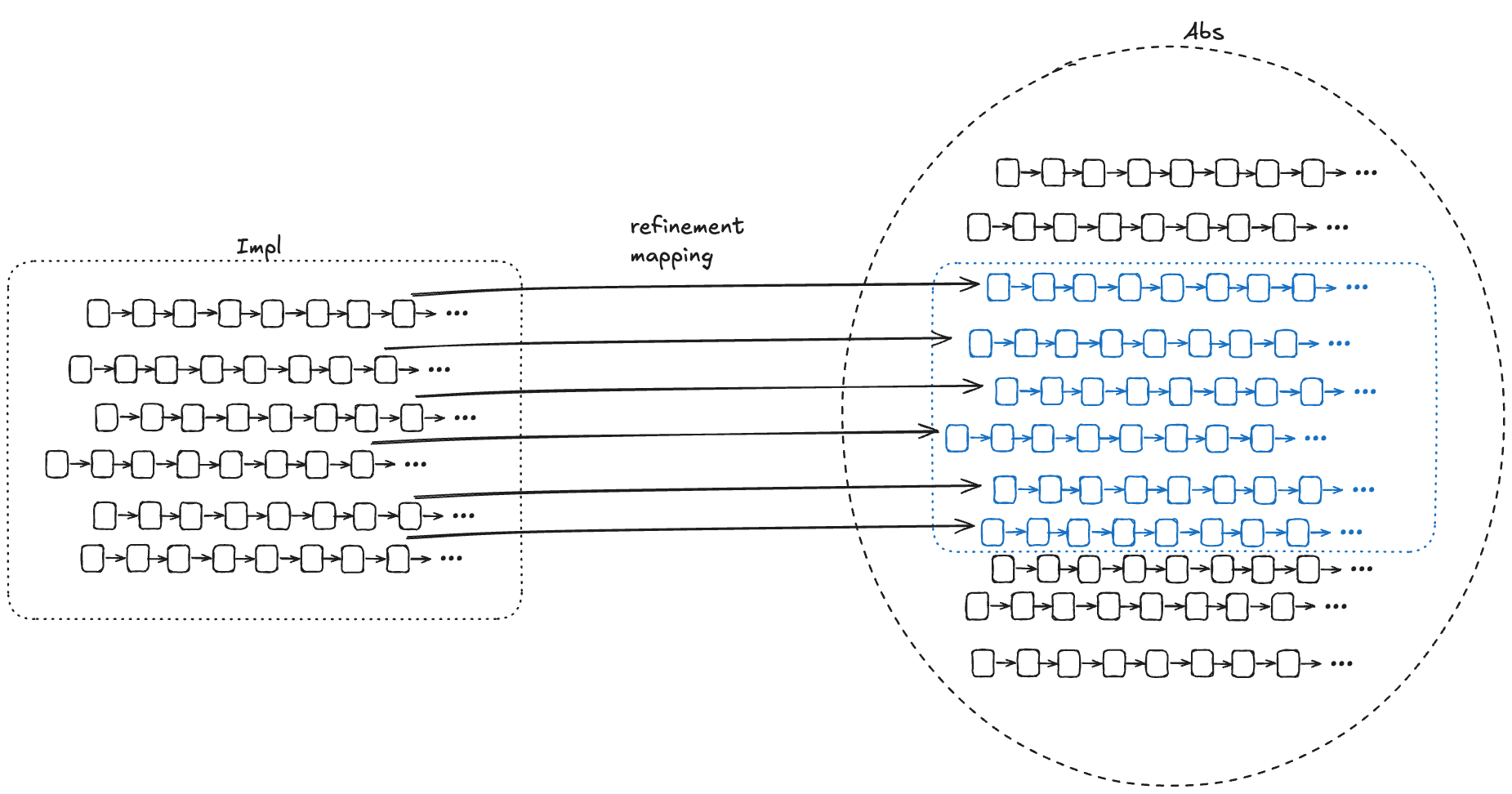
We want to be able to find a corresponding Abs behavior for every Impl behavior
One approach is to do this by construction: if we can take any behavior in Impl and construct a behavior in Abs with the same externally visible values, then we have proved that Impl implements Abs.
To prove that S1 implements S2, it suffices to prove that if S1 allows the behavior <<(e0,z0), (e1, z1), (e2, z2), …>>
where [ei is a state of the externally visible component and] the zi are internal states, then there exists internal states yi such that S2 allows <<(e0,y0), (e1, y1), (e2, y2), … >>
For each behavior B1 in Impl, if we can find values for internal variables in a behavior of Abs, B2, where the external variables of B2 match the external variables of B1, then that’s sufficient to prove that Impl implements Abs.
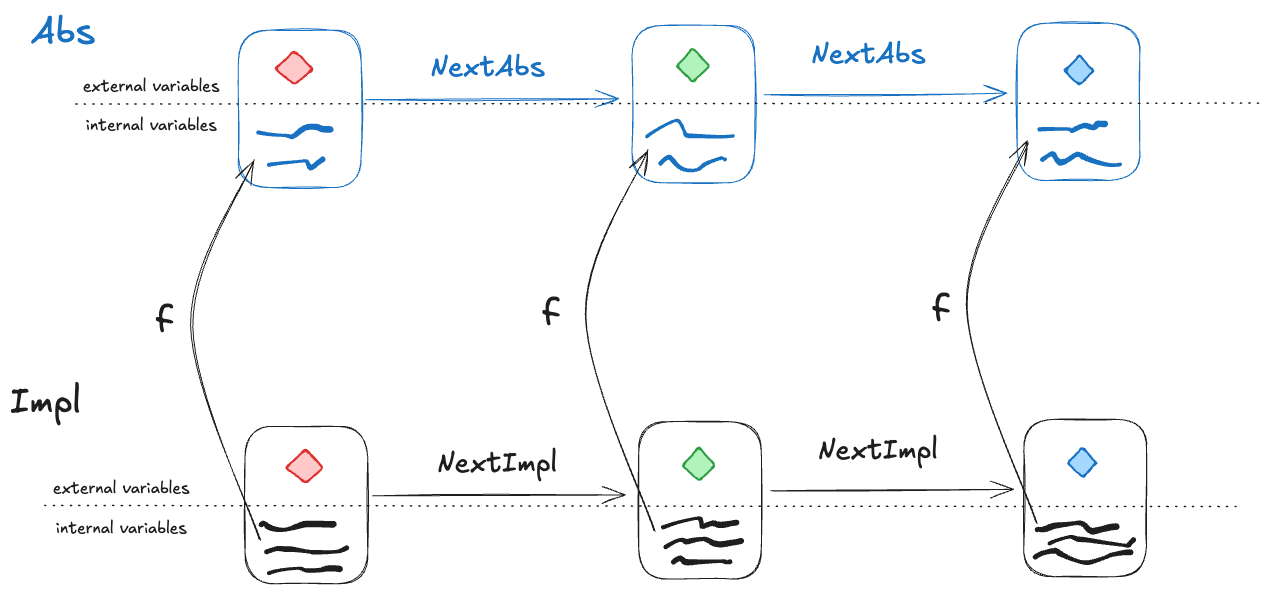
To show that Impl implements Abs, we need to find a refinement mapping, which is a function that will map every behavior in Impl to a behavior in Abs.
A refinement mapping takes a state in an Impl behavior as input and maps to an Abs state, such that:
the external variables are the same in both the Impl state and the Abs state
if a pair of states is a permitted Impl state transition, then the corresponding mapped pair of states must be a permitted Abs state transition
Or, to reword statement 2: if NextImpl is the next-state action for Impl (i.e., the set of allowed state transitions for Impl), and NextAbs is the next-state action for Abs, then under the refinement mapping, every NextImpl-step must map to a NextAbs step.
(Note: this technically isn’t completely correct, we’ll see why in the next section).
Example: our LLLQueue
We want to verify that our Python queue implementation is linearizable. We’ve modeled our Python queue in TLA+ as LLLQueue, and to prove that it’s linearizable, we need to show that a refinement mapping exists between the LLLQueue spec and the LinearizableQueue spec. This means we need to show that there’s a mapping from LLLQueue’s internal variables to LinearizableQueue’s internal variables.
We need to define the internal variables in LinearizableQueue (up, d) in terms of the variables in LLLQueue (nodes, vals, next, prev, head, tail, lock, new_tail, empty, pc, stack) in such a way that all LLLQueue behaviors are also LinearizableQueue behaviors under the mapping.
Internal variable: d
The internal variable d in LinearizableQueue is a sequence which contains the values of the queue, where the first element of the sequence is the head of the queue.
Looking back at our example LLLQueue queue:
We need a mapping that, for this example, results in: d =〈A,B,C,D 〉
I defined a recursive operator that I named Data such that when you call Data(head), it evaluates to a sequence with the values of the queue.
Internal variable: up
The variable up is a boolean flag that flips from false to true after the value has been added to the queue.
In our LLLQueue model, the new node gets added to the tail by the action E3. In PlusCal models, there’s a variable named pc (program counter) that records the current execution state of the program. You can think of pc like a breakpoint that points to the action that will be executed on the next step of the program. We want up to be true after action E3. You can see how the up mapping is defined at the bottom of the LLLQueue.tla file.
Refinement mapping and stuttering
Let’s consider a behavior of the LLLQueue spec that enqueues a single value onto the queue, with a refinement mapping to the LinearizableQueue spec:
In the LinearizableQueue spec, an enqueue operation is implemented by three actions:
EnqStart
EnqTakesEffect
EnqEnd
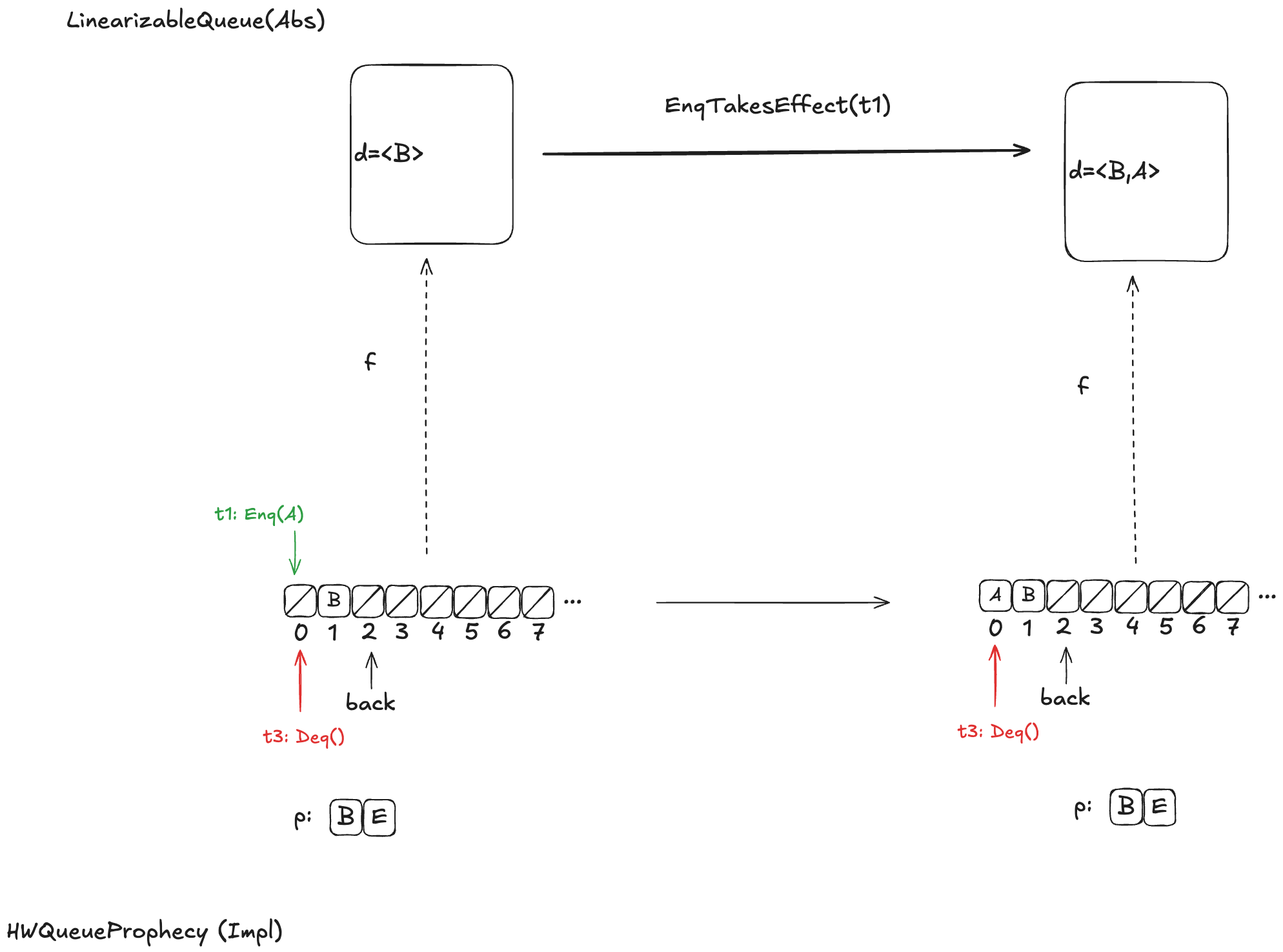
In the LLLQueue spec, an enqueue operation is implemented by seven actions: enq, e1, …, e5, enqdone. That means that the LLLQueue enqueue behavior involves eight distinct states, where the corresponding LinearizableQueue behavior involves only four distinct states. Sometimes, different LLLQueue states map to the same LinearizableQueue state. In the figure above, SI2,SI3,SI4 all map to SA2, and SI5,SI6,SI7 all map to SA3. I’ve color-coded the states in the LinearizableQueue behavior such that states that have the same color are identical.
As a result, some state transitions in the refinement mapping are not LinearizableQueue actions, but are instead transitions where none of the variables change at all. These are called stuttering steps. In TLA+, stuttering steps are always permitted in all behaviors.
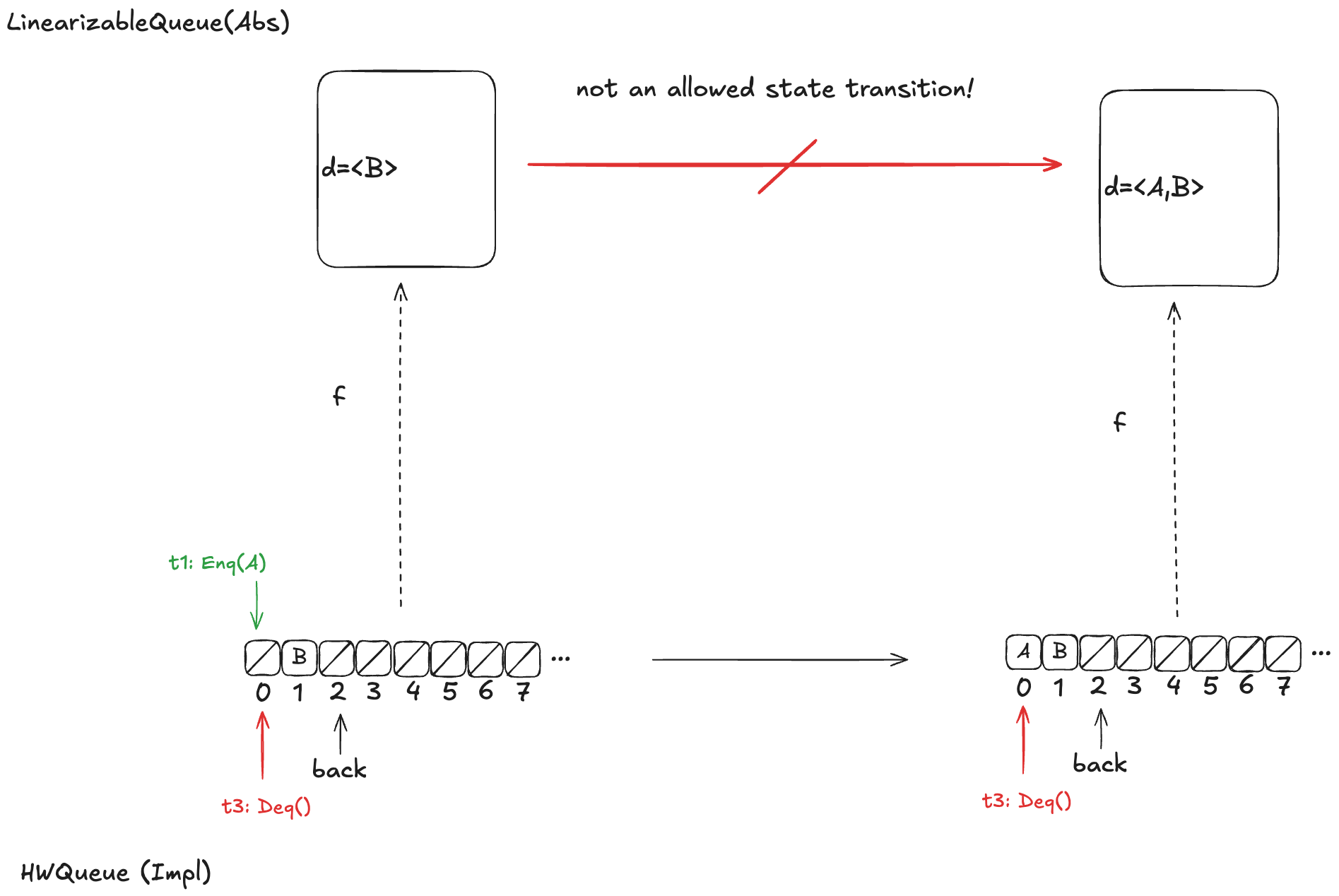
A problem with refinement mappings: the Herlihy and Wing queue
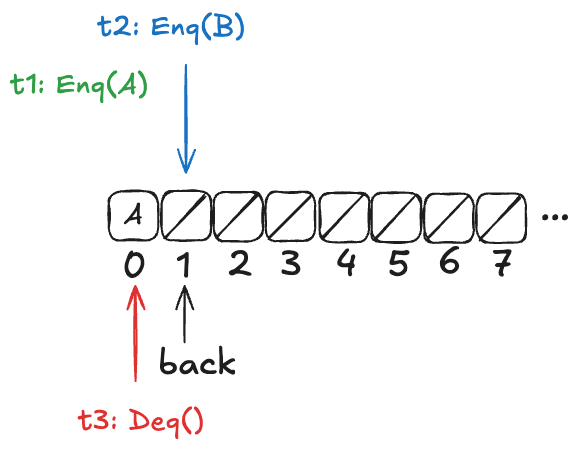
The last section of the Herlihy and Wing paper describes how to prove that a concurrent data structure’s operations are linearizable. In the process, the authors also point out a problem with refinement mappings. They illustrate the problem using a particular queue implementation, which we’ll call the “Herlihy & Wing queue”, or H&W Queue for short.
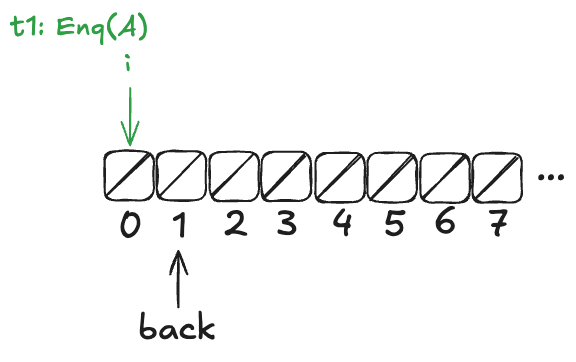
Imagine an array of infinite length, where all of the values are initially null. There’s a variable named back which points to the next available free spot in the queue.
Enqueueing
To enqueue a value onto the Herlihy & Wing queue involves two steps:
Increment the back variable
Write the value into the spot where the back variable pointed before being incremented .
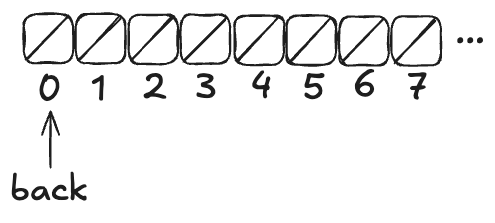
Here’s what the queue looks like after three values (A,B,C) have been enqueued:
Note how back always points to the next free spot.
Dequeueing
To dequeue, you start at index 0, and then you sweep through the array, looking for the first non-null value. Then you atomically copy that value out of the array and set the array element to null.
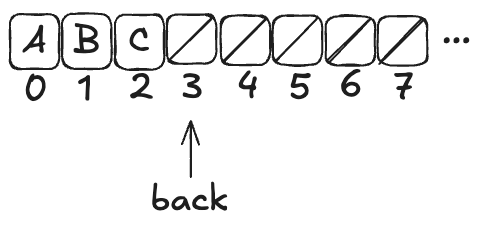
Here’s what a dequeue operation on the queue above would look like:
The Deq operation returned A, and the first element in the array has been set to null.
If you were to enqueue another value (say, D), the array would now look like this:
Note: the elements at the beginning of the queue that get set to null after a dequeue don’t get reclaimed. The authors note that this is inefficient, but the purpose of this queue is to illustrate a particular issue with refinement mappings, not to be a practical queue implementation.
H&W Queue pseudocode
Here’s the pseudocode for Herlihy & Wing queue, which I copied directly from the paper. The two operations are Enq (enqueue) and Deq (dequeue).
rep = record {back: int, items: array [item]}
Enq = proc (q: queue, x: item)
i: int := INC(q.back) % Allocate a new slot
STORE (q.items[i], x) % Fill it.
end Enq
Deq = proc (q: queue) returns (item)
while true do
range: int := READ(q.back) - 1
for i: int in 1 .. range do
x: item := SWAP(q.items[i], null)
if x ~= null then return(x) end
end
end
end Deq
This algorithm relies on the following atomic operations on shared variables:
INC – atomically increment a variable and return the pre-incremented value
STORE – atomically write an element into the array
READ – atomically read an element in the array (copy the value to a local variable)
SWAP – atomically write an element of an array and return the previous array value
H&W Queue implementation in C++
Here’s my attempt at implementing this queue using C++. I chose C++ because of its support for atomic types. C++’s atomic types support all four of the atomic operations required of the H&W queue.
Atomic operation
Description
C++ equivalent
INC
atomically increment a variable and return the pre-incremented value
My queue implementation stores pointers to objects of parameterized type T. Note the atomic types of the member variables. The back variable and elements of the items array need to be atomics because we will be invoking atomic operations on them.
template <typename T>
class Queue {
atomic<int> back;
atomic<T *> *items;
public:
Queue(int sz) : back(0), items(new atomic<T *>[sz]) {}
~Queue() { delete[] items; }
void enq(T *x);
T *deq();
};
template<typename T>
void Queue<T>::enq(T *x) {
int i = back.fetch_add(1);
std::atomic_store(&items[i], x);
}
template<typename T>
T *Queue<T>::deq() {
while (true) {
int range = std::atomic_load(&back);
for (int i = 0; i < range; ++i) {
T *x = std::atomic_exchange(&items[i], nullptr);
if (x != nullptr) return x;
}
}
}
We can write enq and deq to look more like idiomatic C++ by using the following atomic operators:
Using these operators, enq and deq look like this:
template<typename T>
void Queue<T>::enq(T *x) {
int i = back++;
items[i] = x;
}
template<typename T>
T *Queue<T>::deq() {
while (true) {
int range = back;
for (int i = 0; i < range; ++i) {
T *x = std::atomic_exchange(&items[i], nullptr);
if (x != nullptr) return x;
}
}
}
Note that this is, indeed, a linearizable queue, even though it does not use mutual exclusion: tthere are no critical sections in the algorithm.
Modeling the H&W queue in TLA+ with PlusCal
The H&W queue is straightforward to model in PlusCal. If you’re interested in learning PlusCal, it’s actually a great example to use. See HWQueue.tla for my implementation.
Refinement mapping challenge: what’s the state of the queue?
Note how the enq method isn’t an atomic operation. Rather, it’s made up of two atomic operations:
Increment back
Store the element in the array
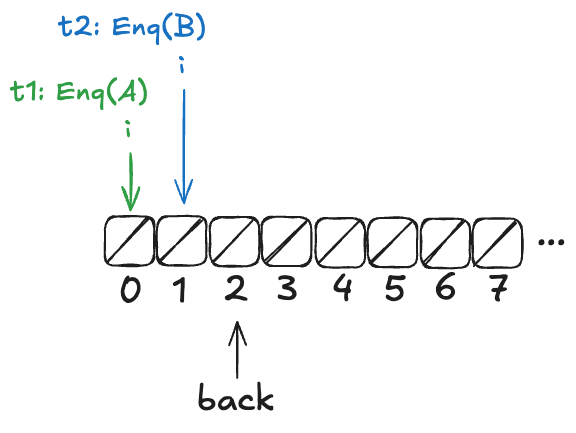
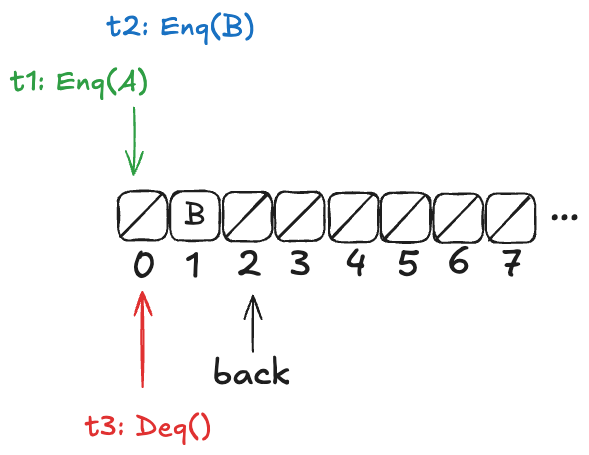
Now, imagine that a thread, t1, comes along, to enqueue a value to the queue. It starts off by incrementing back.
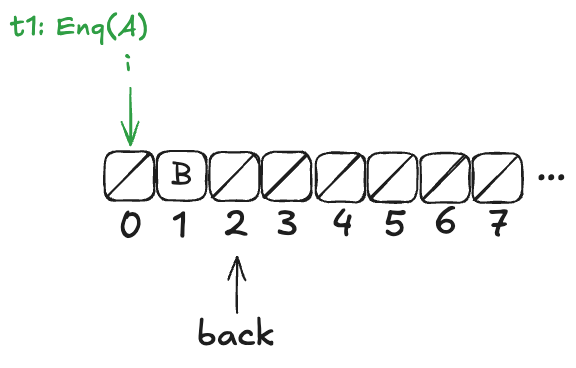
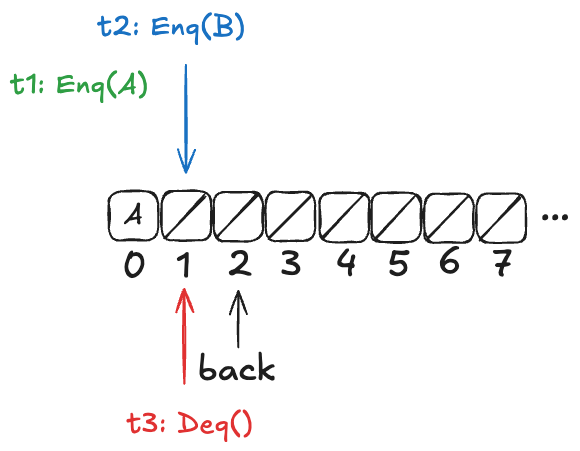
But before it can continue, a new thread, t2, gets scheduled, which also increments back:
t2 then completes the operation:
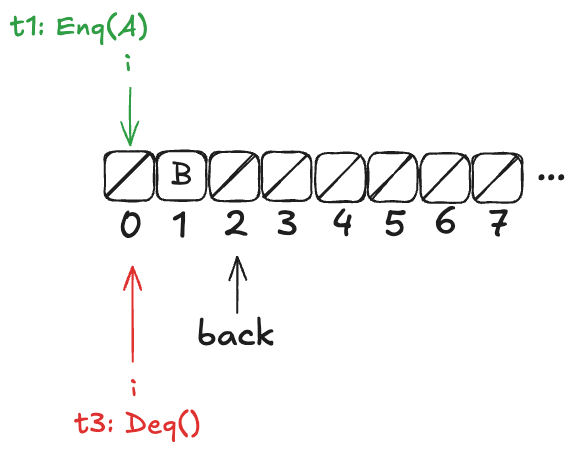
Finally, a new thread, t3, comes along that executes the dequeue operation:
Example state of the H&W queue
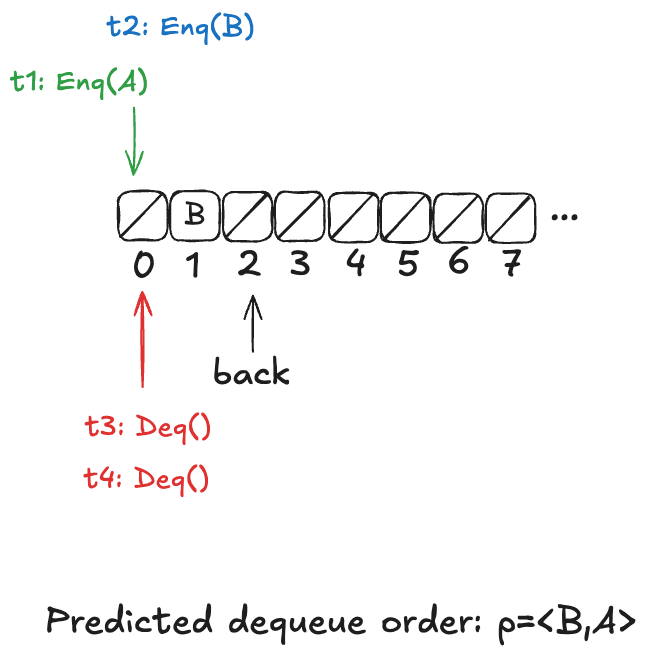
Now, here’s the question: What value will the pending Deq() operation return: A or B?
The answer: it depends on how the threads t1 and t3 will be scheduled. If t1 is scheduled first, it will write A to position 0, and then t3 will read it. On the other hand, if t3 is scheduled first, it will advance its i pointer to the next non-null value, which is position 1, and return B.
Recall back in the section “Modeling a queue with TLA+ > The internal variables” that our model for a linearizable queue had an internal variable, named d, that contained the elements of the queue in the order in which they had been enqueued.
If we were to write a refinement mapping of this implementation to our linearizable specification, for the state above, we’d have to decide whether the mapping for the above state should be. The problem is that no such refinement mapping exists.
Here are the only options that make sense for the example above:
d =〈B〉
d =〈A,B〉
d =〈B,A〉
As a reminder, here are the valid state transitions for the LinearizableQueue spec.
Option 1: d =〈B〉
Let’s say we define our refinement mapping by using the populated elements of the queue. That would result in a mapping of d =〈B〉.
The problem is that if t1 gets scheduled first and adds value A to array position 0, then an element will be added to the head of d. But the only LinearizableQueue action that adds an element to d is EnqTakeEffect, which adds a value to the to the end of d. There is no LinearizableQueue action that allows prepending to d, so this cannot be a valid refinement mapping.
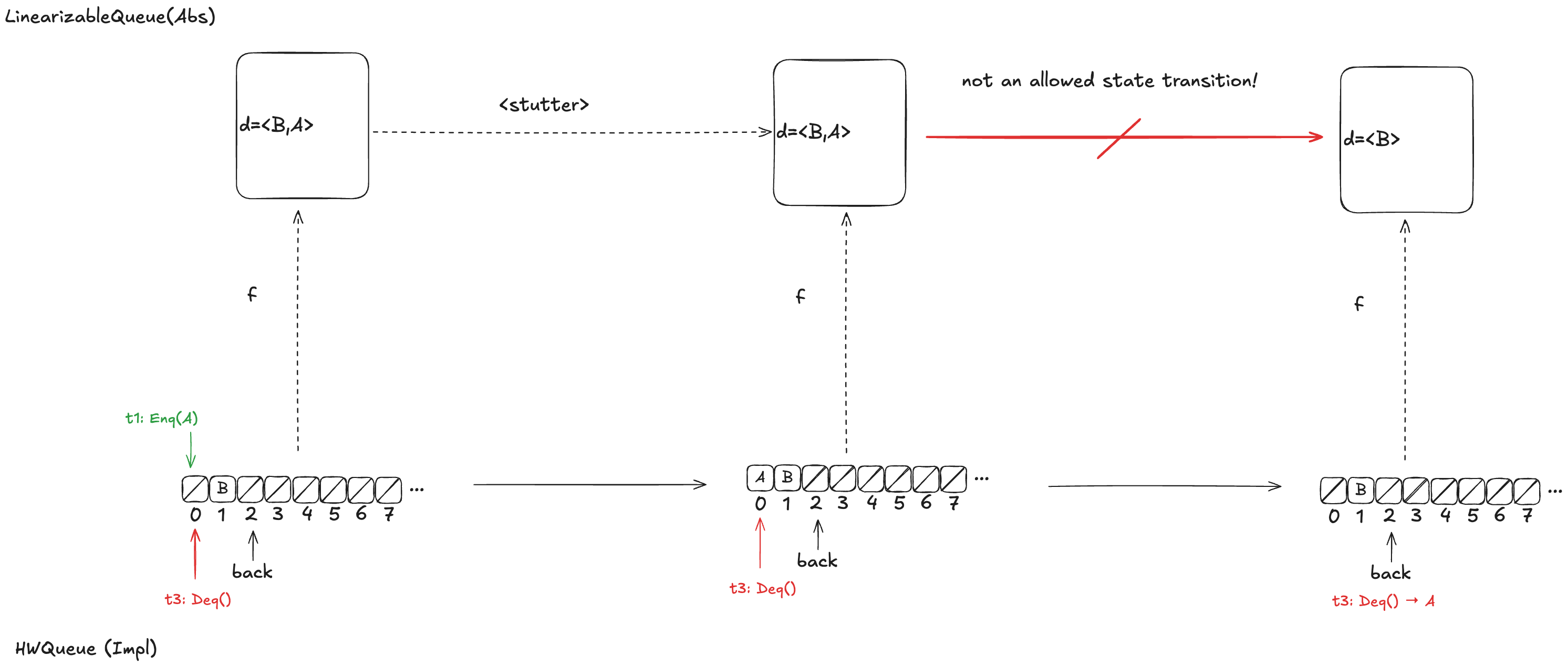
Option 2: d =〈A,B〉
Let’s say we had chosen instead a refinement mapping of d =〈A,B〉for the state above. In that case, if t3 gets scheduled first, then it will result in a value being removed from the end of d, which is not one of the actions of the LinearizableQueueSpec, which means that this can’t be a valid refinement mapping either.
Option 3: d =〈B,A〉
Finally, assume we had chosen d =〈B,A〉as our refinement mapping. Then, if t1 gets scheduled first, and then t3, we will end up with a state transition that removes an element from the end of d, which is not a LinearizableQueue action.
Whichever refinement mapping we choose, it is possible that the resulting behavior will violate the LinearizableQueue spec. This means that we can’t come up with a refinement mapping where every behavior of Impl maps to a valid behavior of Abs, even though Impl implements a linearizable queue!
What Lamport and others believed at the time was that this type of refinement mapping always existed if Impl did indeed implement Abs. With this counterexample, Herlihy & Wing demonstrated that this was not always the case.
Elements in H&W queue aren’t totally ordered
In a typical queue implementation, there is a total ordering of elements that have been enqueued. The odd thing about the Herlihy & Wing queue is that this isn’t the case.
If we look back at our example above:
If t1 is scheduled first, A is dequeued next. If t3 is scheduled first, B is dequeued next.
Either A or B might be dequeued next, depending on the ordering of t1 and t3. Here’s another example where the value dequeued next depends on the ordering of the threads t1 and t3.
If t2 is scheduled first, B is dequeued next. If t3 is scheduled first, A is dequeued next.
However, there are also scenarios where there is a clear ordering among values that have been added to the queue. Consider a case similar to the one above, except that t2 has not yet incremented the back variable:
In this configuration, A is guaranteed to be dequeued before B. More generally, if t1 writes A to the array before t2 increments the back variable, then A is guaranteed to be dequeued before B.
In the linearizability paper, Herlihy & Wing use a mapping approach where they identify a set of possible mappings rather than a single mapping.
Let’s think back to this scenario:
If t1 is scheduled first, A is dequeued next. If t3 is scheduled first, B is dequeued next.
In the scenario above, in the Herlihy and Wing approach, the mapping would be to the set of all possible values of queue.
queue ∈ {〈B〉,〈A,B〉, 〈B,A〉}
Lamport took a different approach to resolving this issue. He rescued the idea of refinement mappings by introducing a concept called prophecy variables
Prophecy
The Herlihy & Wing queue’s behavior is non-deterministic: we don’t know the order in which values will be dequeued, because it depends on the scheduling of the threads. But imagine if we know in advance the order in which the values were dequeued.
It turns out that if we can predict the order in which the values would be dequeued, then we can do a refinement mapping to the our LinearizableQueue model.
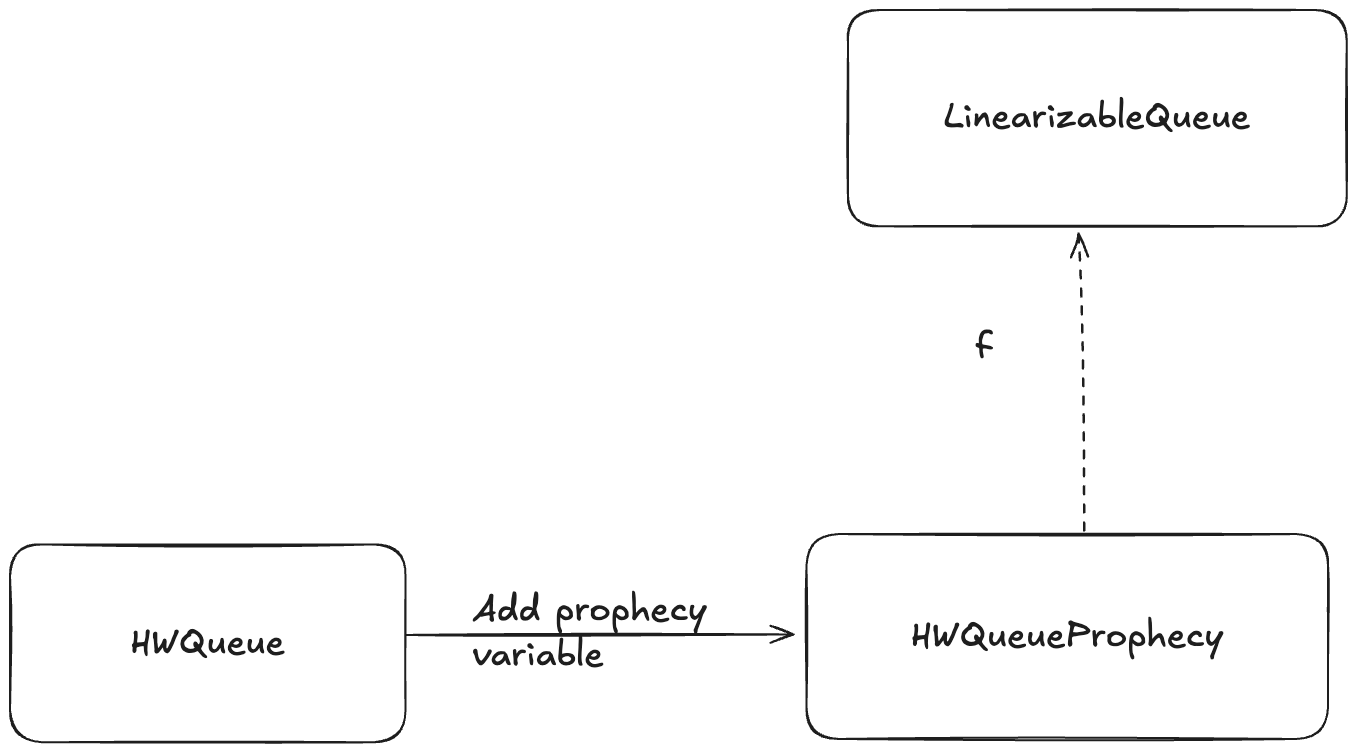
This is the idea behind prophecy variables: we predict certain values that we need for refinement mapping.
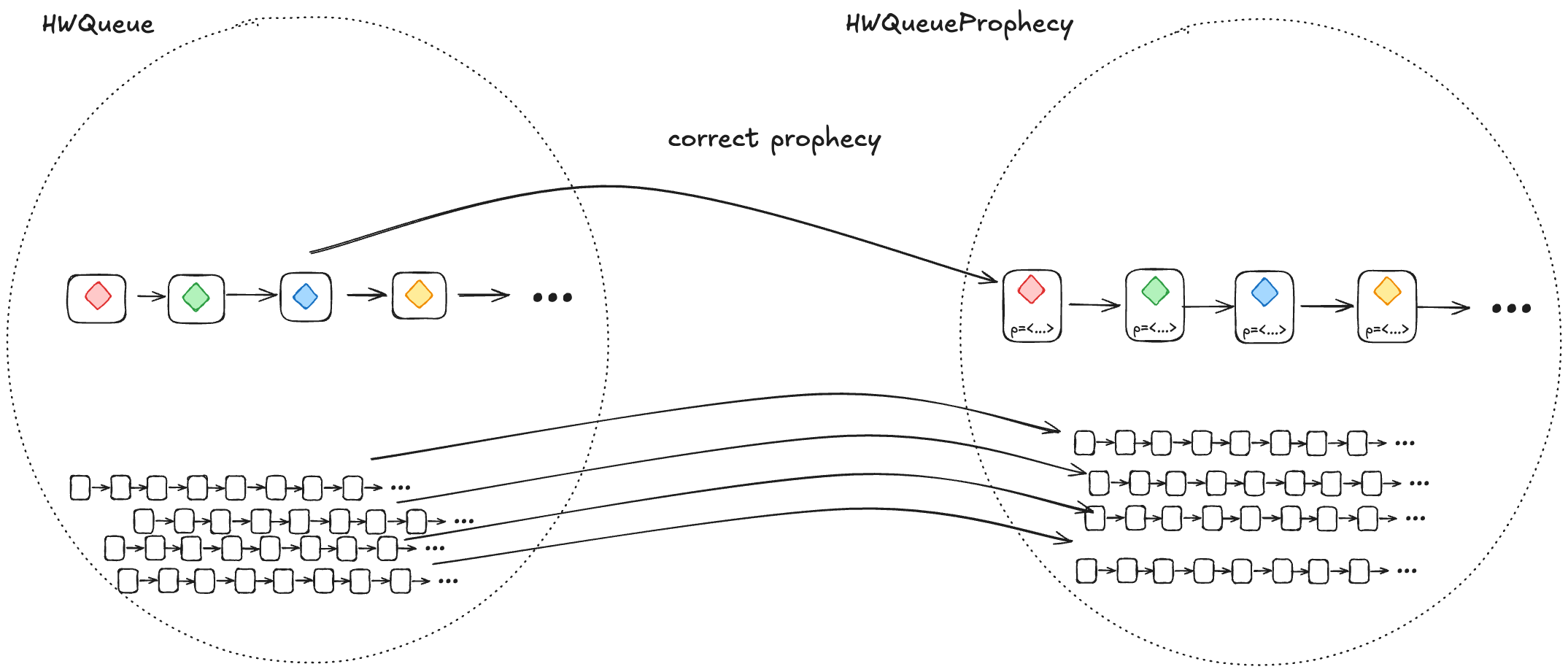
Adding a prophecy variable gives us another specification (one which has a new variable), and this is the specification where we can define a refinement mapping. For example, we add a prophecy to our HWQueue model and call the new model HWQueueProphecy.
In HWQueueProphecy, we maintain a sequence of the predicted order in which values will be dequeued. Every time a thread invokes the enqueue operation, we add a new value to our sequence of predicted dequeue operations.
The predicted value is chosen at random from the set of all possible values: it is not necessarily related to either the value currently being enqueued or the current state of the queue.
Now, these predictions might not actually come true. In fact, they almost certainly won’t come true, because we’re much more likely to predict at least one value incorrectly. In the example above, the actual dequeueing order will be〈A,B,C〉, which is different from the predicted dequeueing order of〈Q,W,E〉
However, the refinement mapping will still work, even though the predictions will often be wrong, if we set things up correctly. We’ll tackle that next.
Prophecy requirements
We want to show that HWQueue implements LinearizableQueue. But it’s only HWQueueProphecy that we can show implements LinearizableQueue using a refinement mapping.
1. A correct prophecy must exist for every HWQueue behavior
Every behavior in HWQueue must have a corresponding behavior in HWQueueProphecy. That correspondence happens when the prophecy accurately predicts the dequeueing order.
This means that, for each behavior in HWQueue, there must be a behavior in HWQueueProphecy which is identical except that the HWQueueProphecy behaviors have an additional p variable with the prophecy.
To ensure that a correct prophecy always exists, we just make sure that we always predict from the set of all possible values.
In the case of HWQueueProphecy, we are always enqueueing values from the set {A,…,Z}, and so as long as we draw predictions from the set {A,…,Z}, we are guaranteed that the correct prediction is among the set we are predicting from.
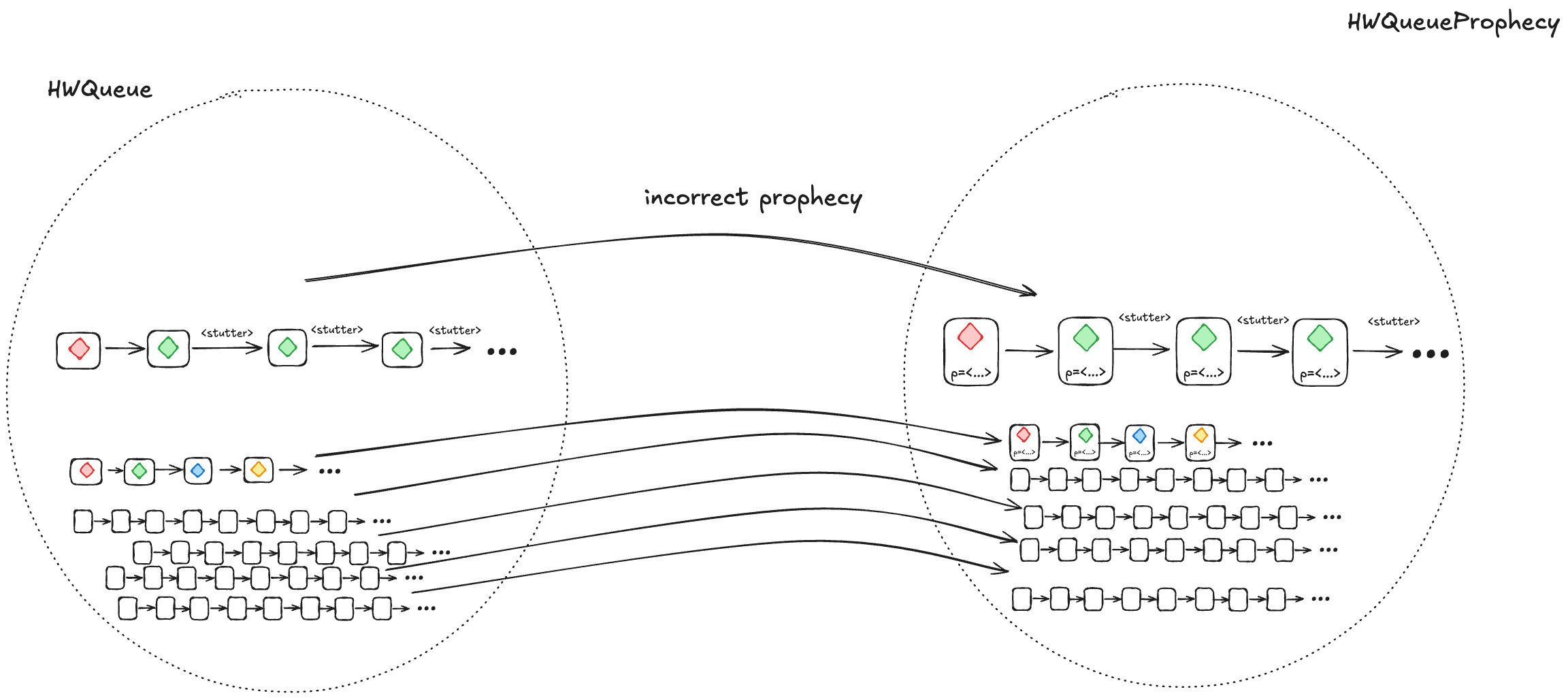
2. Every HWQueueProphecybehaviorwith an incorrect prophecy must correspond to at least one HWQueue behavior
Most of the time, our predictions will be incorrect. We need to ensure that, when we prophesize incorrectly, the resulting behavior is still a valid HWQueue behavior, and is also still a valid LinearizableQueue behavior under refinement.
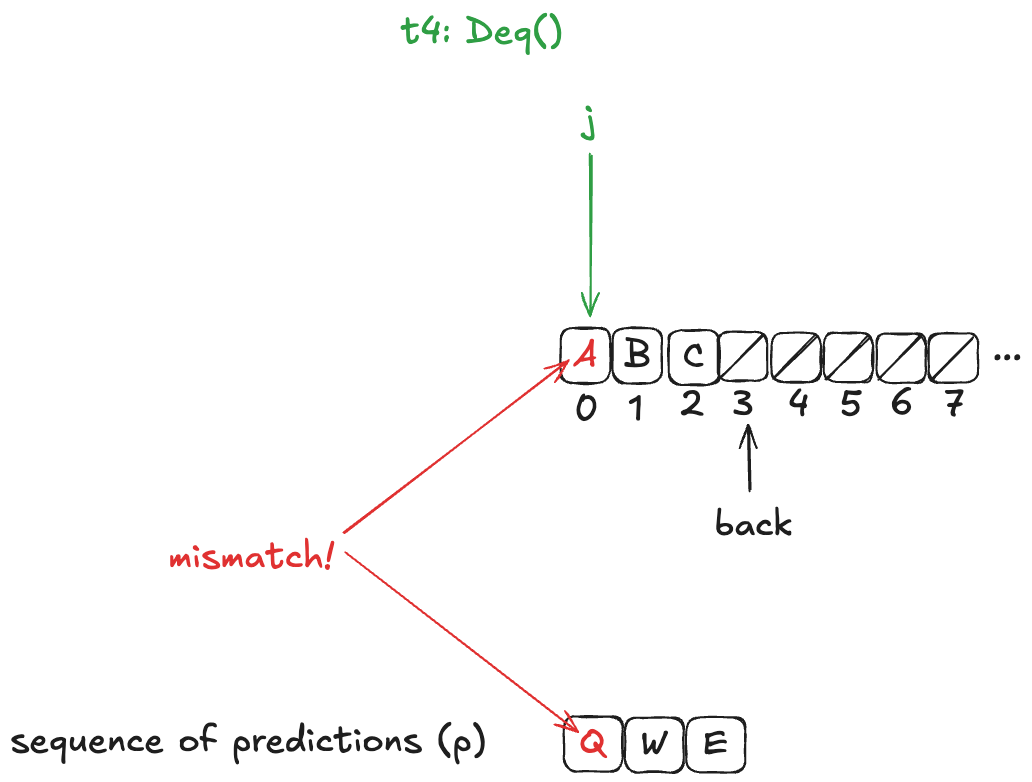
We do this by writing our HWQueueProphecy specification such that, if our prediction turns out to be incorrect (e.g., we predict A as the next value to be dequeued, and the next value that will actually be dequeued is B), we disallow the dequeue from happening.
In other words, we disallow state transitions that would violate our predictions.
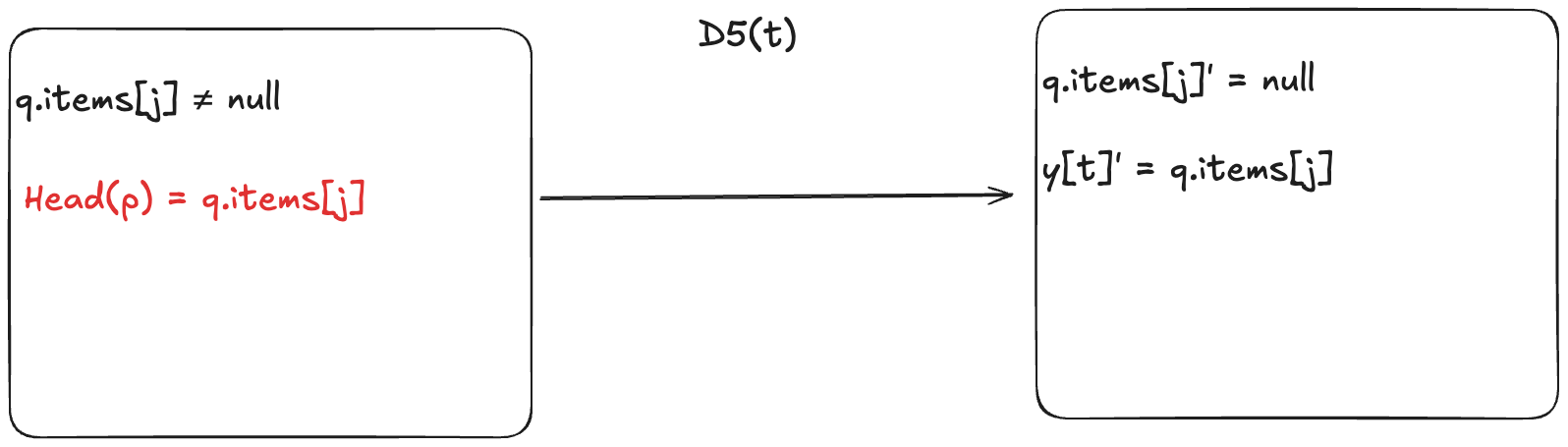
This means we add a new enabling condition to one of the dequeue actions. Now, for the dequeueing thread to remove the value from the array, it has to match the next value in the predicted sequence. In HWQueueProphecy, the name of the action that does this is D5, where t is id of the thread doing the dequeueing.
An incorrect prophecy blocks the dequeueing from actually happening. In the case of HWQueueProphecy, we can still enqueue values (since we don’t make any predictions on enqueue order, only dequeue order, so there’s nothing to block).
But let’s consider the more interesting case where an incorrect prophecy results in deadlock, where no actions are enabled anymore. This means that the only possible future steps in the behavior are stuttering steps, where the values never change.
When a prophecy is incorrect, it can result in deadlock, where all future steps are stuttering steps. These are still valid behaviors.
However, if we take a valid behavior of a specification, and we add stuttering steps, the resulting behavior is always also a valid behavior of the specification. So, the resulting behaviors are guaranteed to be in the set of valid HWQueue behaviors.
Using the prophecy to do the refinement mapping
Let’s review what we were trying to accomplish here. We want to figure out a refinement mapping from HWQueueProphecy to LinearizableQueue such that every state transition satisfies the LinearizableQueue specification.
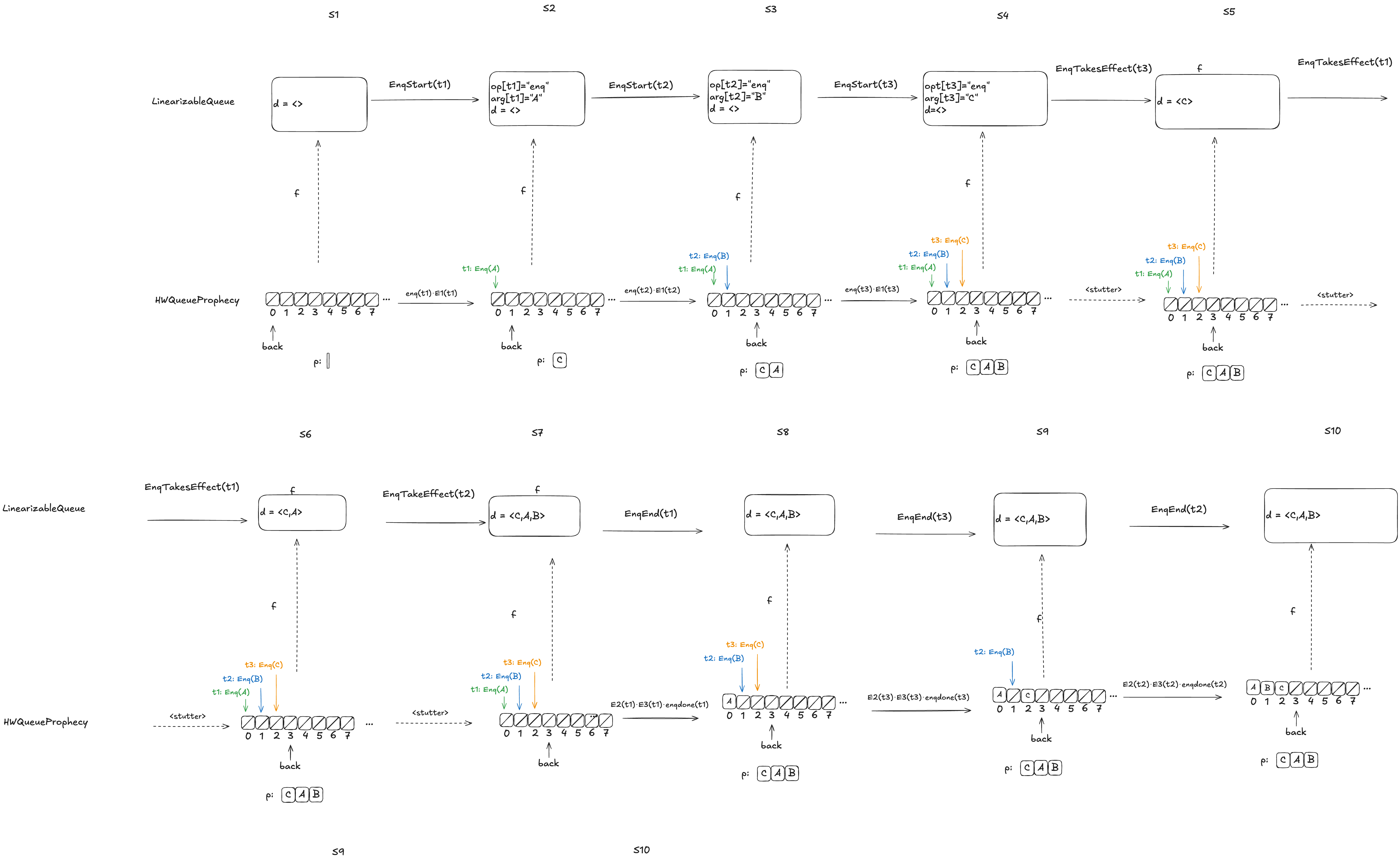
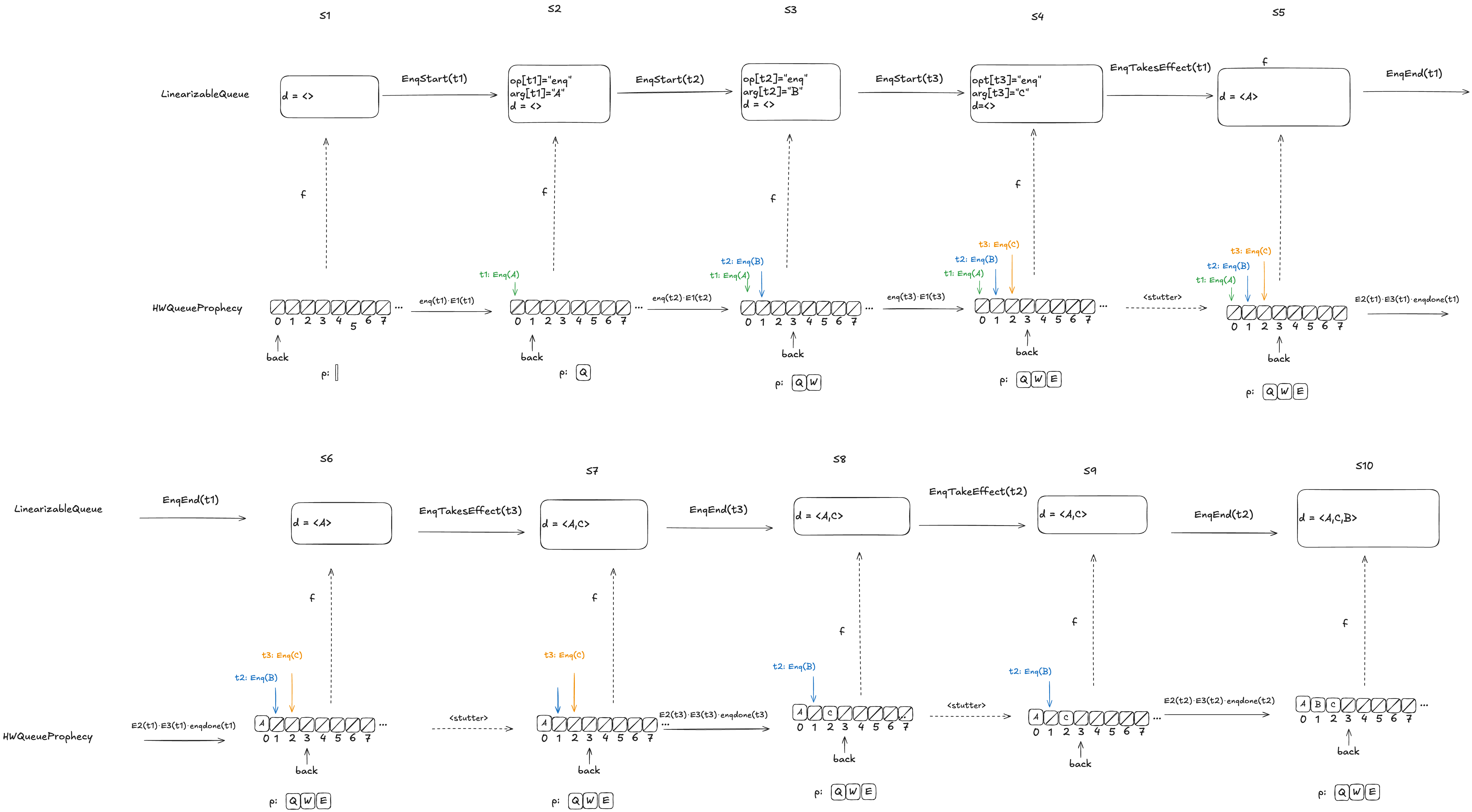
Here’s an example, where the value B has been enqueued, the value A is in the process of being enqueued, and no values have been dequeued yet.
Defining how to do this mapping is not obvious, and I’m not going to explain it here, as it would take up way too much space, and this post is already much too long. Instead, I will defer interested readers to section 6.5 of Lamport’s book A Science of Concurrent Programs, which describes how to do the mapping. See also my POFifopq.tla spec, which is my complete implementation of his description.
But I do want to show you something about it.
Enqueue example
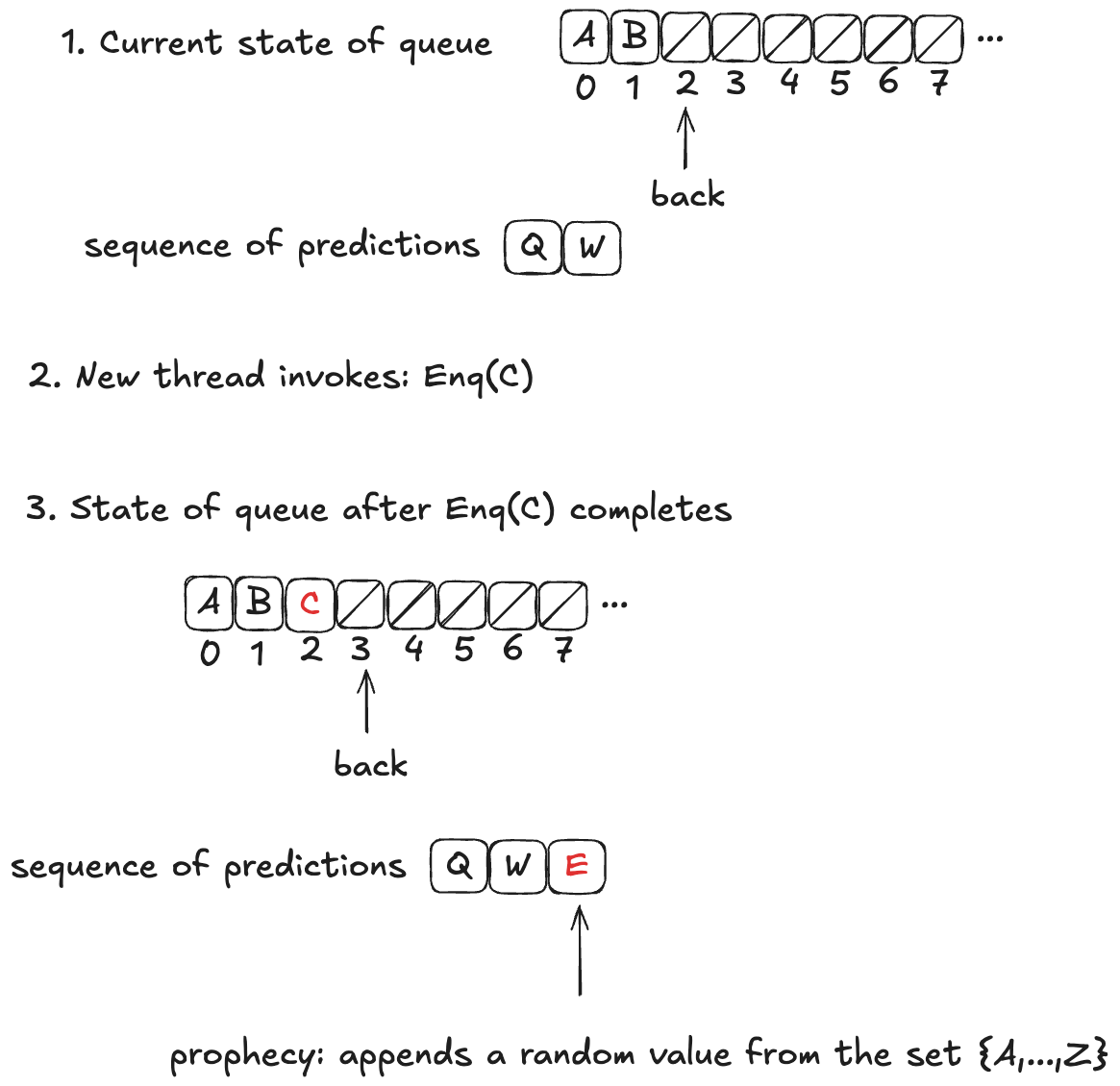
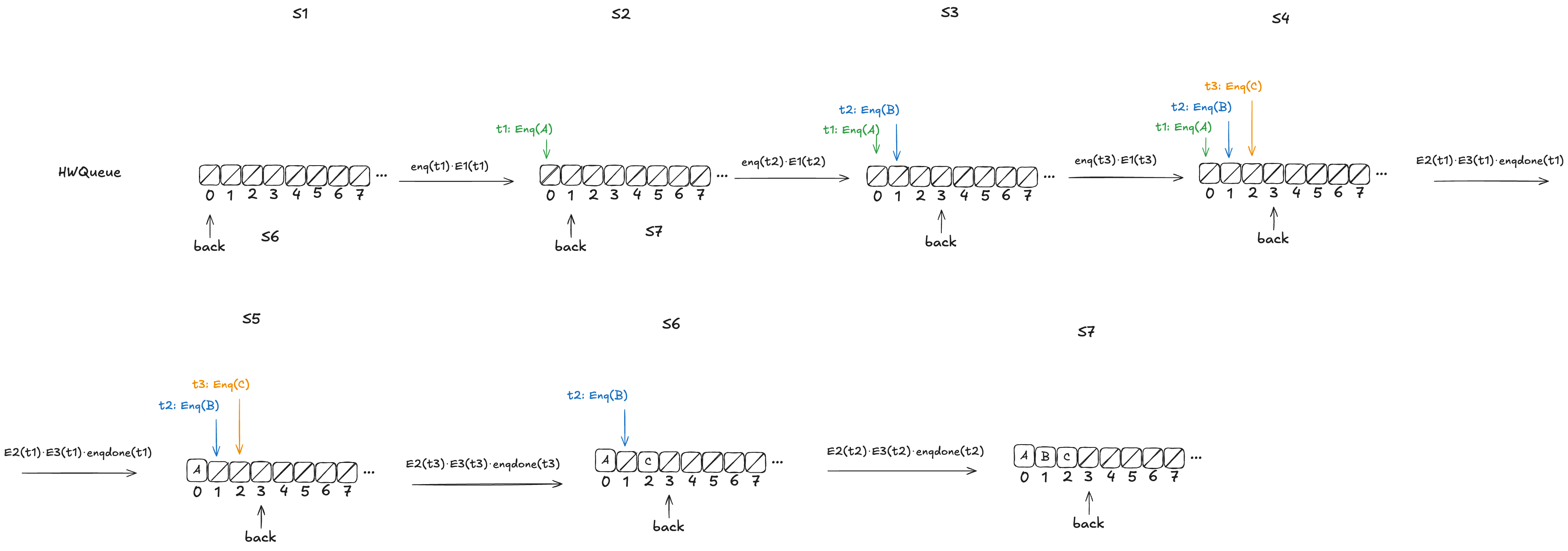
Let’s consider this HWQueue behavior, where we are concurrently enqueueing three values (A,B,C):
These enqueue operations all overlap each other, like this:
The refinement mapping will depend on the predictions.
Here’s an example where the predictions are consistent with the values being enqueued. Note how the state of the mapping ends up matching the predicted values.
Notice how in the final state (S10), the refinement mapping d=〈C,A,B〉is identical to the predicted dequeue ordering: p=〈C,A,B〉.
Here the predicted dequeue values p=〈Q,W,E〉can never be fulfilled, and the refinement mapping in this case, d=〈A,C,B〉matches the order in which overlapping enqueue operations complete.
The logic for determining the mapping varies depending on whether it is possible for the predictions to be fulfilled. For more details on this, see A Science of Concurrent Programs.
For the dequeueing case, if the value to be dequeued matches the first prediction in p, then we execute the dequeue and we remove the prediction from p. (We’ve already discussed the behavior if the value to be dequeued doesn’t match the prediction).
Coda
Phew! There was a lot of content in this post, including definitions and worked out examples. It took me a long time to grok a lot of this material, so I suspect that even an interested reader won’t fully absorb it on the first read. But if you got all of the way here, you’re probably interested enough in TLA+ that you’ll continue to read further on it. I personally find that it helps to have multiple explanations and examples, and I’ve tried to make an effort to present these concepts a little differently than other sources, so hopefully you’ll find it useful to come back here after reading elsewhere.
A Science of Concurrent Programs. Leslie Lamport. This is a self-published book on how to use TLA to model concurrent algorithms. This book documents how to use prophecy variables to implement the refinement mapping for the linearizable queue in the Herlihy and Wing paper.
Consistency Models. Linearizability is a consistency models, but there are multiple other ones. Kyle Kingsbury provides a good overview of the different models on his Jepsen site.
I’m sure you’ve heard the slogan “safety first”. It is a statement of values for an organization, but let’s think about how to define what it should mean explicitly. Here’s how I propose to define safety first, in the context of a company. I’ll assume the company is in the tech (software) industry, since that’s the one I know best. So, in this context, you can think of “safety” as being about avoiding system outages, rather than about, say, avoiding injuries on a work site.
Here we go:
A tech company is a safety first company if any engineer has the ability to extend a project deadline, provided that the engineer judges in the moment that they need additional time in order to accomplish the work more safely (e.g., by following an onerous procedure for making a change, or doing additional validation work that is particular time-intensive).
This ability to extend the deadline must be:
automatic
unquestioned
consequence-free
Automatic. The engineer does not to explicitly ask someone else for permission before extending the deadline.
Unquestioned. Nobody is permitted to ask the engineer “why did you extend the deadline?” after-the-fact.
Consequence-free. This action cannot be held against the engineer. For example, it cannot be a factor in a performance review.
Now, anyone who has worked in management would say to me, “Lorin, this is ridiculous. If you give people the ability to extend deadlines without consequence, then they’re just going to use this constantly, even if there isn’t any benefit to safety. It’s going to drastically harm the organization’s ability to actually get anything done”.
And, the truth is, they’re absolutely right. We all work under deadlines, and we all know that if there was a magical “extend deadline” button that anyone could press, that button would be pressed a lot, and not always for the purpose of improving safety. Organizations need to execute, and if anybody could introduce delays, this would cripple execution.
But this response is exactly the reason why safety first will always be a lie. Production pressure is an unavoidable reality for all organizations. Because of this, the system will always push back against delays, and that includes delays for the benefit of safety. This means engineers will always face double binds, where they will feel pressure to execute on schedule, but will be punished if they make decisions that facilitate execution but reduce safety.
Safety is never first in organization: it’s always one of a number of factors that trade off against each other. And those sorts of tradeoff decisions happen day-to-day and moment-to-moment.
Remember that the next time someone is criticized for “not being careful enough” after a change brings down production.
The other day, The Future of TLA+ (pdf) hit Hacker News. TLA+ is a specification language: it is intended for describing the desired behavior of a system. Because it’s a specification language, you don’t need to specify implementation details to describe desired behavior. This can be confusing to experienced programmers who are newcomers to TLA+, because when you implement something in a programming language, you can always use either a compiler or an interpreter to turn it into an executable. But specs written in a specification language aren’t executable, they’re descriptions of permitted behaviors.
Just for fun, here’s an example: a TLA+ specification for a program that solves the twin prime conjecture. According to this spec, when the program runs, it will set the answer variable to either “yes” if the twin prime conjecture is true, or “no” if the conjecture is false.
Unfortunately, if I was to try to write a program that implements this spec, I don’t know whether answer should be set to “yes” or “no”: the conjecture has yet to be proven or disproven. Despite this, have still formally specified its behavior!
There’s a lot we simply don’t know about how reliability work was prioritized inside of CrowdStrike, but I’m going to propose a little thought experiment about the incident where I make some assumptions.
First, let’s assume that the CrowdStrike incident was the first time they had an incident that was triggered by a Rapid Response Content update, which is a config update. We’ll assume that previous sensor issues that led to Linux crashes were related to a sensor release, which is a code update.
Next, let’s assume that CrowdStrike focuses their reliability work on addressing the identified root cause of previous incidents.
Finally, let’s assume that none of the mitigations documented in their RCA were identified as action items that addressed the root cause of any incidents they experienced before this big one.
If these three assumptions are true, then it explains why these mitigations weren’t done previously. Because they didn’t address the root causes of previous incidents, and they focus their post-incident work on identifying the root cause of previous incidents. Now, I have no idea if any of these assumptions are actually true, but they sound plausible enough for this thought experiment to hold.
This thought experiment demonstrates the danger of focusing post-incident work on addressing the root causes of previous incidents: it acts to obscure other risks in the system that don’t happen to fit into the root cause analysis. After all, issues around validation of the channel files or staging of deploys were not really the root cause of any of the incidents before this one. The risks that are still in your system don’t care about what you have labeled “the real root cause” of the previous incident, and there’s no reason to believe that whatever gets this label is the thing that is most likely to bite you in the future.
I propose (cheekily) to refer to the prioritize-identifying-and-addressing-the-root-cause–of-previous-incidents thinking as the “CrowdStrike” approach to reliability work.
I put “CrowdStrike” in quotes because, in a sense, this really isn’t about them at all: I have no idea if the assumptions in this thought experiment are true. But my motivation for using this phrase is more about using CrowdStrike as a symbol that’s become salient to our industry then about the particular details of that company.
Are you on the lookout for the many different signals of risk in your system, or are you taking the “CrowdStrike” approach to reliability work?
CrowdStrike has released their final (sigh) External Root Cause Analysis doc. The writeup contains some more data on the specific failure mode. I’m not going to summarize it here, mostly because I don’t think I’d add any value in doing so: my knowledge of this system is no better than anyone else reading the report. I must admit, though, that I couldn’t helping thinking of number eleven in Alan Perlis’s epigrams in programming.
If you have a procedure with ten parameters, you probably missed some.
What I wanted to do instead with this blog is call out the last two of the “findings and mitigations” in the doc:
Template Instance validation should expand to include testing within the Content Interpreter
Template Instances should have staged deployment
This echos the chorus of responses I heard online in the aftermath of the outage. “Why didn’t they test these configs before deployment? How could they not stage their deploys?”
And this is my biggest disappointment with this writeup: it doesn’t provide us with insight into how the system got to this point.
Here are the types of questions I like to ask to try to get at this.
Had a rapid response content update ever triggered a crash before in the history of the company? If not, why do you think this type of failure (crash related to rapid response content) has never bitten the company before?If so, what happened last time?
Was there something novel about the IPC template type? (e.g., was this the first time the reading of one field was controlled by the value of another?)
How is generation of the test template instances typically done? Was the test template instance generation here a typical case or an exceptional one? If exceptional, what was different? If typical, how come it has never led to problems before?
Before the incident, had customers ever asked for the ability to do staged rollouts? If so, how was that ask prioritized relative to other work?
Was there any planned work to improve reliabilitybeforethe incident happened?What type of work was planned? How far along was it? How did you prioritize this work?
I know I’m a broken record here, but I’ll say it again. Systems reach the current state that they’re in because, in the past, people within the system made rational decisions based on the information they had at the time, and the constraints that they were operating under. The only way to understand how incidents happen is to try and reconstruct the path that the system took to get here, and that means trying to as best as you can to recreate the context that people were operating under when they made those decisions.
In particular, availability work tends to go to the areas where there was previously evidence of problems. That tends to be where I try to pick at things. Did we see problems in this area before? If we never had problems in this area before, what was different this time?
If we did see problems in the past, and those problems weren’t addressed, then that leads to a different set of questions. There are always more problems than resources, which means that orgs have to figure out what they’re going to prioritize (say “quarterly planning” to any software engineer and watch the light fade from their eyes). How does prioritization happen at the org?
It’s too much to hope for a public writeup to ever give that sort of insight, but I was hoping for something more about the story of “How we got here” in their final writeup. Unfortunately, it looks like this is all we get.
The last post I wrote mentioned in passing how Java’s ReentrantLock class is implemented as a modified version of something called a CLH lock. I’d never heard of a CLH lock before, and so I thought it would be fun to learn more about it by trying to model it. My model here is based on the implementation described in section 3.1 of the paper Building FIFO and Priority-Queueing Spin Locks from Atomic Swap by Travis Craig.
This type of lock is a first-in-first-out (FIFO) spin lock. FIFO means that processes acquire the lock in order in which they requested it, also known as first-come-first-served. A spin lock is a type of lock where the thread runs in a loop continually checking the state of a variable to determine whether it can take the lock. (Note that Java’s ReentrantLock is not a spin lock, despite being based on CLH).
Also note that I’m going to use the terms process and thread interchangeably in this post. The literature generally uses the term process, but I prefer thread because of the shared-memory nature of the lock.
Visualizing the state of a CLH lock
I thought I’d start off by showing you what a CLH data structure looks like under lock contention. Below is a visualization of the state of a CLH lock when:
There are three processes (P1, P2, P3)
P1 has the lock
P2 and P3 are waiting on the lock
The order that the lock was requested in is: P1, P2, P3
The paper uses the term requests to refer to the shared variables that hold the granted/pending state of the lock, those are the boxes with the sharp corners. The head of the line is at the left, and the end of the line is at the right, with a tail pointer pointing to the final request in line.
Each process owns two pointers: watch and myreq. These pointers each point to a request variable.
If I am a process, then my watch pointer points to a request that’s owned by the process that’s ahead of me in line. The myreq pointer points to the request that I own, which is the request that the process behind in me line will wait on. Over time, you can imagine the granted value propagating to the right as the processes release the lock.
This structure behaves like a queue, where P1 is at the head and P3 is at the tail. But it isn’t a conventional linked list: the pointers don’t form a chain.
Requesting the lock
When a new process requests the lock, it:
points its watch pointer to the current tail
creates a new pending request object and points to it with its myreq pointer
updates the tail to point to this new object
Releasing the lock
To release the lock, a process sets the value of its myreq request to granted. (It also takes ownership of the watch request, setting myreq to that request, for future use).
Modeling desired high-level behavior
Before we build our CLH model, let’s think about how we’ll verify if our model is correct. One way to do this is to start off with a description of the desired behavior of our lock without regard to the particular implementation details of CLH.
What we want out of a CLH lock is a lock that preserves the FIFO ordering of the requests. I defined a model I called FifoLock that has just the high-level behavior, namely:
it implements mutual exclusion
threads are granted the lock in first-come-first-served order
Execution path
Here’s the state transition diagram for each thread in my model. The arrows are annotated with the name of the TLA+ sub-actions in the model.
FIFO behavior
To model the FIFO behavior, I used a TLA+ sequence to implement a queue. The Request action appends the thread id to a sequence, and the Acquire action only grants the lock to the thread at the head of the sequence:
Now let’s build an actual model of the CLH algorithm. Note that I called these processes instead of threads because that’s what the original paper does, and I wanted to stay close to the paper in terminology to help readers.
The CLH model relies on pointers. I used a TLA+ function to model pointers. I defined a variable named requests that maps a request id to the value of the request variable. This way, I can model pointers by having processes interact with request values using request ids as a layer of indirection.
---- MODULE CLH ----
...
CONSTANTS NProc, GRANTED, PENDING, X
first == 0 \* Initial request on the queue, not owned by any process
Processes == 1..NProc
RequestIDs == Processes \union {first}
VARIABLES
requests, \* map request ids to request state
...
TypeOk ==
/\ requests \in [RequestIDs -> {PENDING, GRANTED, X}]
...
(I used “X” to mean “don’t care”, which is what Craig uses in his paper).
The way the algorithm works, there needs to be an initial request which is not owned by any of the process. I used 0 as the Request id for this initial request and called it first.
The myreq and watch pointers are modeled as functions that map from a process id to a request id. I used -1 to model a null pointer.
The state-transition diagram for each process in our CLH model is similar to the one in our abstract (FifoLock) model. The only real difference is that requesting the lock is done in two steps:
Update the request variable to pending (MarkPending)
Append the request to the tail of the queue (EnqueueRequest)
We want to verify that our CLH model always behaves in a way consistent with our FifoLock model. We can check this in using the model checker by specifying what’s called a refinement mapping. We need to show that:
We can create a mapping from the CLH model’s variables to the FifoLock model’s variables.
Every valid behavior of the CLH model satisfies the FifoLock specification under this mapping.
The mapping
The FifoLock model has two variables, state and queue.
The state variable is a function that maps each thread id to the state of that thread in its state machine. The dashed arrows show how I defined the state refinement mapping:
Note that two states in the CLH model (ready, to-enqueue) map to one state in FifoLock (ready).
For the queue mapping, I need to take the CLH representation (recall it looks like this)…
…and define a transformation so that I end up with a sequence that looks like this, which represents the queue in the FifoLock model:
<<P1, P2, P3>>
To do that, I defined a helper operator called QueueFromTail that, given a tail pointer in CLH, constructs a sequence of ids in the right order.
Unowned(request) ==
~ \E p \in Processes : myreq[p] = request
\* Need to reconstruct the queue to do our mapping
RECURSIVE QueueFromTail(_)
QueueFromTail(rid) ==
IF Unowned(rid) THEN <<>> ELSE
LET tl == CHOOSE p \in Processes : myreq[p] = rid
r == watch[tl]
IN Append(QueueFromTail(r), tl)
In my CLH.cfg file, I added this line to check the refinement mapping:
PROPERTY
Refinement
Note again what we’re doing here for validation: we’re checking if our more detailed model faithfully implements the behavior of a simpler model (under a given mapping). Note that we’re using TLA+ to serve two different purposes.
To specify the high-level behavior that we consider correct (our behavioral contract)
To model a specific algorithm (our implementation)
Because TLA+ allows us to choose the granularity of our model, we can use it for both high-level specs of desired behavior and low-level specifications of an algorithm.
Recently, some of my former colleagues wrote a blog post on the Netflix Tech Blog about a particularly challenging performance issue they ran into in production when using the new virtual threads feature of Java 21. Their post goes into a lot of detail on how they conducted their investigation and finally figured out what the issue was, and I highly recommend it. They also include a link to a simple Java program that reproduces the issue.
I thought it would be fun to see if I could model the system in enough detail in TLA+ to be able to reproduce the problem. Ultimately, this was a deadlock issue, and one of the things that TLA+ is good at is detecting deadlocks. While reproducing a known problem won’t find any new bugs, I still found the exercise useful because it helped me get a better understanding of the behavior of the technologies that are involved. There’s nothing like trying to model an existing system to teach you that you don’t actually understand the implementation details as well as you thought you did.
This problem only manifested when the following conditions were all present in the execution:
virtual threads
platform threads
All threads contending on a lock
some virtual threads trying to acquire the lock when inside a synchronized block
some virtual threads trying to acquire the lock when not inside a synchronized block
To be able to model this, we need to understand some details about:
virtual threads
synchronized blocks and how they interact with virtual threads
Java lock behavior when there are multiple threads waiting for the lock
Virtual threads
Virtual threads are very well-explained in JEP 444, and I don’t think I can really improve upon that description. I’ll provide just enough detail here so that my TLA+ model makes sense, but I recommend that you read the original source. (Side note: Ron Pressler, one of the authors of JEP 444, just so happens to be a TLA+ expert).
If you want to write a request-response style application that can handle multiple concurrent requests, then programming in a thread-per-request style is very appealing, because the style of programming is easy to reason about.
The problem with thread-per-request is that each individual thread consumes a non-trivial amount of system resources (most notably, dedicated memory for the call stack of each thread). If you have too many threads, then you can start to see performance issues. But in thread-per-request model, the number of concurrent requests your application service is capped by the number of threads. The number of threads your system can run can become the bottleneck.
You can avoid the thread bottleneck by writing in an asynchronous style instead of thread-per-request. However, async code is generally regarded as more difficult for programmers to write than thread-per-request.
Virtual threads are an attempt to keep the thread-per-request programming model while reducing the resource cost of individual threads, so that programs can run comfortably with many more threads.
The general approach of virtual threads is referred to as user-modethreads. Traditionally, threads in Java are wrappers around operating-system (OS) level threads, which means there is a 1:1 relationship between a thread from the Java programmer’s perspective and the operating system’s perspective. With user-mode threads, this is no longer true, which means that virtual threads are much “cheaper”: they consume fewer resources, so you can have many more of them. They still have the same API as OS level threads, which makes them easy to use by programmers who are familiar with threads.
However, you still need the OS level threads (which JEP 444 refers to as platform threads), as we’ll discuss in the next session.
How virtual threads actually run: carriers
For a virtual thread to execute, the scheduler needs to assign a platform thread to it. This platform thread is called the carrier thread, and JEP 444 uses the term mounting to refer to assigning a virtual thread to a carrier thread. The way you set up your Java application to use virtual threads is that you configure a pool of platform threads that will back your virtual threads. The scheduler will assign virtual threads to carrier threads to the pool.
A virtual thread may be assigned to different platform threads throughout the virtual thread’s lifetime: the scheduler is free to unmount a virtual thread from one platform thread and then later mount the virtual thread onto a different platform thread.
Importantly, a virtual thread needs to be mounted to a platform thread in order to run. If it isn’t mounted to a carrier thread, the virtual thread can’t run.
Synchronized
While virtual threads are new to Java, the synchronized statement has been in the language for a long time. From the Java docs:
A synchronized statement acquires a mutual-exclusion lock (§17.1) on behalf of the executing thread, executes a block, then releases the lock. While the executing thread owns the lock, no other thread may acquire the lock.
final class RealSpan extends Span {
...
final PendingSpans pendingSpans;
final MutableSpan state;
@Override public void finish(long timestamp) {
synchronized (state) {
pendingSpans.finish(context, timestamp);
}
}
In the example method above, the effect of the synchronized statement is to:
Acquire the lock associated with the state object
Execute the code inside of the block
Release the lock
(Note that in Java, every object is associated with a lock). This type of synchronization API is sometimes referred to as a monitor.
Synchronized blocks are relevant here because they interact with virtual threads, as described below.
Virtual threads, synchronized blocks, and pinning
Synchronized blocks guarantee mutual exclusion: only one thread can execute inside of the synchronized block. In order to enforce this guarantee, the Java engineers made the decision that, when a virtual thread enters a synchronized block, it must be pinned to its carrier thread. This means that the scheduler is not permitted to unmount a virtual thread from a carrier until the virtual thread exits the synchronized block.
ReentrantLock as FIFO
The last piece of the puzzle is related to the implementation details of a particular Java synchronization primitive: the ReentrantLock class. What’s important here is how this class behaves when there are multiple threads contending for the lock, and the thread that currently holds the lock releases it.
The relevant implementation detail is that this lock is a FIFO: it maintains a queue with the identity of the threads that are waiting on the lock, ordered by arrival. As you can see in the code, after a thread releases a lock, the next thread in line gets notified that the lock is free.
VirtualThreads is the set of virtual threads that execute the application logic. CarrierThreads is the set of platform threads that will act as carriers for the virtual threads. To model the failure mode that was originally observed in the blog post, I also needed to have platform threads that will execute the application logic. I called these FreePlatformThreads, because these platform threads are never bound to virtual threads.
I called the threads that directly execute the application logic, whether virtual or (free) platform, “work threads”:
schedule – function that describe how work threads are mounted to platform threads
inSyncBlock – the set of virtual threads that are currently inside a synchronized block
pinned – the set of carrier threads that are currently pinned to a virtual thread
lockQueue – a queue of work threads that are currently waiting for the lock
My model only models a single lock, which I believe is this lock in the original scenario. Note that I don’t model the locks associated with the synchronization blocks, because there was no contention associated with those locks in the scenario I’m modeling: I’m only modeling synchronization for the pinning behavior.
Program counters
Each worker thread can take one of two execution paths through the code. Here’s a simplified view of the two different code possible paths: the left code path is when a thread enters a synchronized block before it tries to acquire the lock, and the right code path is when a thread does not enter a synchronized block before it tries to acquire the lock.
This is conceptually how my model works, but I modeled the left-hand path a little differently than this diagram. The program counters in my model actually transition back from “to-enter-sync” to “ready”, and they use a separate state variable (inSyncBlock) to determine whether to transition to the to-exit-sync state at the end. The other difference is that the program counters in my model also will jump directly from “ready” to “locked” if the lock is currently free. But showing those state transitions directly would make the above diagram harder to read.
The lock
The FIFO lock is modeled as a TLA+ sequence of work threads. Note that I don’t need to actually model whether the lock is held or not. My model just checks that the thread that wants to enter the critical section is at the head of the queue, and when it leaves the critical section, it gets removed from the head. The relevant actions look like this:
To check if a thread has the lock, I just check if it’s in a state that requires the lock:
\* A thread has the lock if it's in one of the pc that requires the lock
HasTheLock(thread) == pc[thread] \in {"locked", "in-critical-section"}
I also defined this invariant that I checked with TLC to ensure that only the thread at the head of the lock queue can be in any of these states.
HeadHasTheLock ==
\A t \in WorkThreads : HasTheLock(t) => t = Head(lockQueue)
Pinning in synchronized blocks
When a virtual thread enters a synchronized block, the corresponding carrier thread gets marked as pinned. When it leaves a synchronized block, it gets unmarked as pinned.
\* We only care about virtual threads entering synchronized blocks
EnterSynchronizedBlock(virtual) ==
/\ pc[virtual] = "to-enter-sync"
/\ pinned' = pinned \union {schedule[virtual]}
...
ExitSynchronizedBlock(virtual) ==
/\ pc[virtual] = "to-exit-sync"
/\ pinned' = pinned \ {schedule[virtual]}
The scheduler
My model has an action named Mount that mounts a virtual thread to a carrier thread. In my model, this action can fire at any time, whereas in the actual implementation of virtual threads, I believe that thread scheduling only happens at blocking calls. Here’s what it looks like:
\* Mount a virtual thread to a carrier thread, bumping the other thread
\* We can only do this when the carrier is not pinned, and when the virtual threads is not already pinned
\* We need to unschedule the previous thread
Mount(virtual, carrier) ==
LET carrierInUse == \E t \in VirtualThreads : schedule[t] = carrier
prev == CHOOSE t \in VirtualThreads : schedule[t] = carrier
IN /\ carrier \notin pinned
/\ \/ schedule[virtual] = NULL
\/ schedule[virtual] \notin pinned
\* If a virtual thread has the lock already, then don't pre-empt it.
/\ carrierInUse => ~HasTheLock(prev)
/\ schedule' = IF carrierInUse
THEN [schedule EXCEPT ![virtual]=carrier, ![prev]=NULL]
ELSE [schedule EXCEPT ![virtual]=carrier]
/\ UNCHANGED <<lockQueue, pc, pinned, inSyncBlock>>
My scheduler also won’t pre-empt a thread that is holding the lock. That’s because, in the original blog post, nobody was holding the lock during deadlock, and I wanted to reproduce that specific scenario. So, if a thread gets a lock, the scheduler won’t stop it from releasing the lock. And, yet, we can still get a deadlock!
Only executing while scheduled
Every action is only allowed to fire if the thread is scheduled. I implemented it like this:
IsScheduled(thread) == schedule[thread] # NULL
\* Every action has this pattern:
Action(thread) ==
/\ IsScheduled(thread)
....
Finding the deadlock
Here’s the config file I used to run a simulation. I had defined three virtual threads, two carrier threads, and one free platform threads.
And, indeed, the model checker finds a deadlock! Here’s what the trace looks like in the Visual Studio Code plugin.
Note how virtual thread V2 is in the “requested” state according to its program counter, and V2 is at the head of the lockQueue, which means that it is able to take the lock, but the schedule shows “V2 :> NULL”, which means that the thread is not scheduled to run on any carrier threads.
And we can see in the “pinned” set that all of the carrier threads {C1,C2} are pinned. We also see that the threads V1 and V3 are behind V2 in the lock queue. They’re blocked waiting for the lock, and they’re holding on to the carrier threads, so V2 will never get a chance to execute.
One of the workhorses of the modern software world is the key-value store. there are key-value services such as Redis or Dynamo, and some languages build key-value data structures right in to the language (examples include Go, Python and Clojure). Even relational databases, which are not themselves key-value stores, are frequently built on top of a data structure that exposes a key-value interface.
Key-value data structures are often referred to as maps or dictionaries, but here I want to call attention to the less-frequently-used term associative array. This term evokes the associative nature of the store: the value that we store is associated with the key.
When I work on an incident writeup, I try to capture details and links to the various artifacts that the incident responders used in order to diagnose and mitigate the incident. Examples of such details include:
dashboards (with screenshots that illustrate the problem and links to the dashboard)
names of feature flags that were used or considered for remediation
relevant Slack channels where there was coordination (other than the incident channel)
Why bother with these details? I see it as a strategy to tackle the problem that Woods and Cook refer to in Perspectives on Human Error: Hindsight Biases and Local Rationality as the problem of inert knowledge. There may be information about that we learned at some point, but we can’t bring it to bear when an incident is happening. However, we humans are good at remembering other incidents! And so, my hope is that when an operational surprise happens, someone will remember “Oh yeah, I remember reading about something like this when incident XYZ happened”, and then they can go look up the incident writeup to incident XYZ and see the details that they need to help them respond.
In other words, the previous incidents act as keys, and the content of the incident write-ups act as the value. If you make the incident write-ups memorable, then people may just remember enough about them to look up the write-ups and page in details about the relevant tools right when they need them.
Below is a screenshot of Vizceral, a tool that was built by a former teammate of mine at Netflix. It provides a visualization of the interactions between the various microservices.
Vizceral uses moving dots to depict how requests are currently flowing through the Netflix microservice architecture. Vizceral is able to do its thing because of the platform tooling, which provides support for generating a visualization like this by exporting a standard set of inter-process communication (IPC) metrics.
What you don’t see depicted here are the interactions between those microservices and the telemetry platform that ingest these metrics. There’s also logging and tracing data, and those get shipped off-box via different channels, but none of those channels show up in this diagram.
In fact, this visualization doesn’t represent interactions with any of the platform services. You won’t see bubbles that represent the compute platform or the CI/CD platform represented in a diagram like this, even though those platform services all interact with these application services in important ways.
I call the first category of interactions, the ones between the application services, as first-class, and the second category, the ones where the interactions involve platform services, as second-class. It’s those second-class interactions that I want to say more about.
These second-class interactions tend to have a large blast radius, because successful platforms by their nature have a large blast radius. There’s a reason why there’s so much havoc out in the world when AWS’s us-east-1 region has a problem: because so many services out there are using us-east-1 as a platform. Similarly, if you have a successful platform within your organization, then by definition it’s going to see a lot of use, which means that if it experiences a problem, it can do a lot of damage.
These platforms are generally more reliable than the applications that run atop them, because they have to be: platforms naturally have higher reliability requirements than the applications that run atop them. They have these requirements because they have a large blast radius. A flaky platform is a platform that contributes to multiple high-severity outages, and systems that contribute to multiple high-severity outages are the systems were reliability work gets prioritized.
And a reliable system is a system whose details you aren’t aware of, because you don’t need to be. If my car is very reliable, then I’m not going to build an accurate mental model of how my car works, because I don’t need to: it just works. In her book Human-Machine Reconfigurations: Plans and Situated Actions, the anthropologist Lucy Suchman used the term representation to describe the activity of explicitly constructing a mental model of how a piece of technology works, and she noted that this type of cognitive work only happens when we run into trouble. As Suchman puts it:
[R]epresentation occurs when otherwise transparent activity becomes in some way problematic
Hence the irony: these second-class interactions tend not to be represented in our system models when we talk about reliability, because they are generally not problematic.
And so we are lulled into a false sense of security. We don’t think about how the plumbing works, because the plumbing just works. Until the plumbing breaks. And then we’re in big trouble.