A few weeks ago, I decided to estimate 90% confidence intervals for each day that I worked on developing a feature.
Here are some results over 10 days from when I started estimating until when the feature was deployed into production.
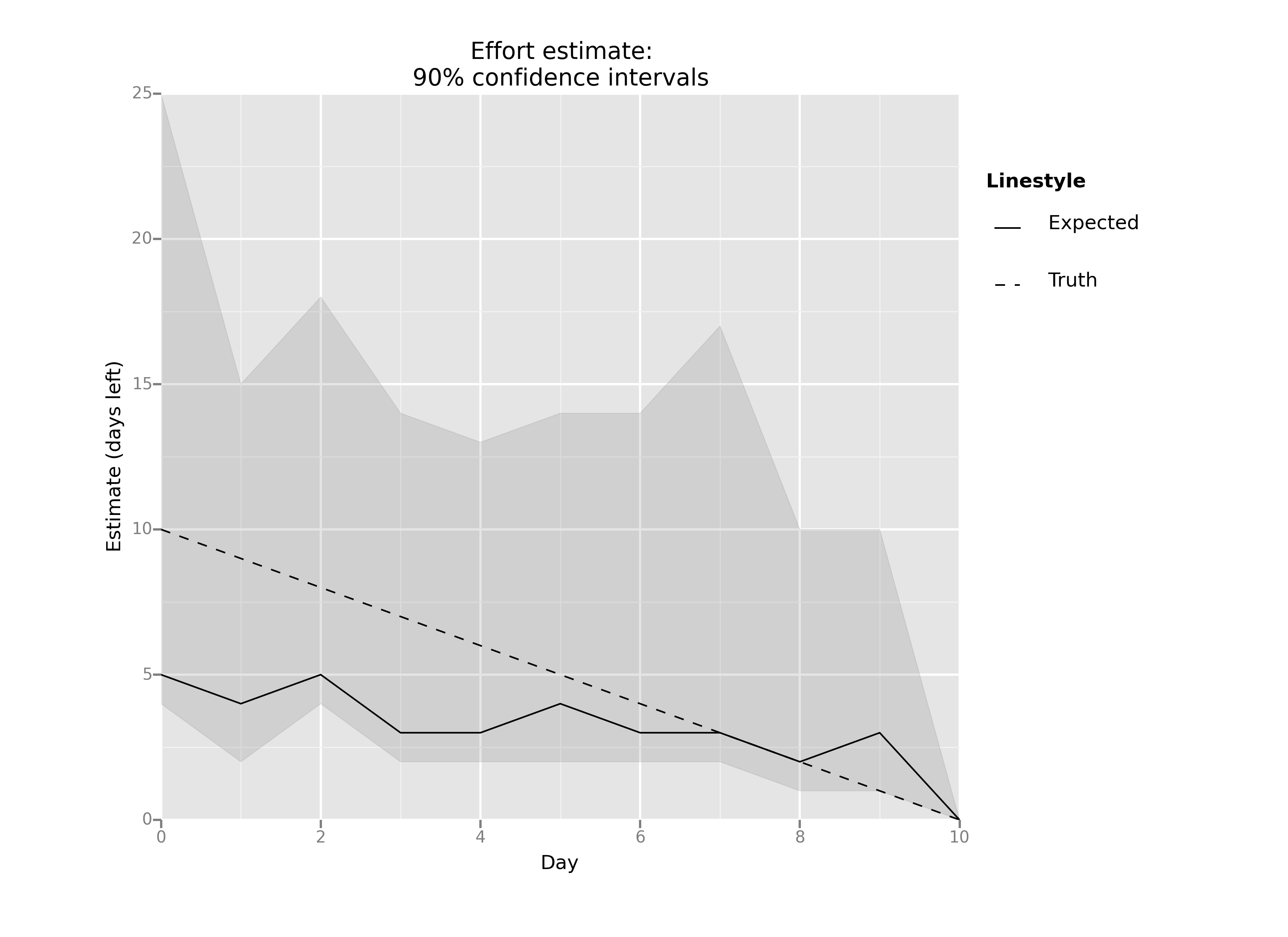
The dashed line is the “truth”: it’s what my estimate would have been if I had estimated perfectly each day. The shaded region represents my 90% confidence estimate: I was 90% confident that the amount of time left fell into that region. The solid line is the traditional pointwise effort estimate: it was my best guess as to how many days I had left before the feature would be complete.
If we subtract out the “truth” from the other lines, we can see the error in my estimate for each day:

Some observations:
- The 90% confidence interval always included the true value, which gives me hope that this an effective estimation approach.
- My pointwise estimate underestimated the true time remaining for 9 out of 10 days.
- My first pointwise estimate started off by a factor of two (estimate of 5 days versus an actual of 10 days), and got steadily better over time.
I generated these plots using IPython and the ggplot library. You can see my IPython notebook on my website with details on how these plots were made.

This is really interesting. If I read this correctly on day 0 you estimated between 4 and 25 days for the project, guessing 5 (why did you not guess the mean, i.e. 14?). It actually took 10 days. So your initial estimate was low by a factor of 2, and the upper bound was high by 2.5x.
My question is, what can you do to make that range tighter? Is this related to how experienced you are with the feature/project? That is, if you had to build the same thing again, could you do a much tighter range (say 8-12 days)? One would assume that is what the “build it twice” axiom is implying.
I generated my intervals by breaking them down into subtasks and then trying to imagine best-case and worst-case scenarios for each sub-task, and then adding them up. Similarly, the expected value estimate was the sum of the expected values of the subtasks, which was typically close to the best-case with a little bit of padding. Perhaps I should have just taken the midpoint, but I honestly thought that the distribution skewed right, and that the midpoint wasn’t the mean. It’s hard to shake the optimistic feeling that mostly nothing will go wrong.
I think that if I did the exact same task again, the bounds would be tighter. For example, it took me some additional effort because I did not understand the behavior of a new library dependency I was using. But I suspect that, for the development that I do, I won’t be able to get the bounds tighter: there’s just inherent uncertainty in the process: most features will involve something that I haven’t encountered before.
Great readd thankyou