One of my hobbies is learning Yiddish. Growing up Jewish in Montreal, I attended a parochial elementary school that taught Yiddish (along with French and Hebrew), but dropped it after that. A couple of years ago, I discovered a Yiddish teacher in my local area and I started taking classes for fun.
Our teacher recently introduced us to a Yiddish expression, hintish-kloog, which translates literally as “dog smartness”. It refers to a dog’s ability to sniff out and locate food in all sorts of places.
This made me think of the kind of skill required to solve operational problems during the moment. It’s a very different kind of skill than, say, constructing abstractions during software development. Instead, it’s more about employing a set of heuristics to try to diagnose the issue, hunting through our dashboards to look for useful signals. “Did something change recently? Are errors up? Is the database healthy?”
My teacher noted that that many of the more religious Jews tend to look down on owning a dog, and so hintish-kloog is meant in a pejorative sense: this isn’t the kind of intelligence that is prized by scholars. This made me think about the historical difference in prestige between development and operations work, where skilled operations work is seen as a lower form of work than skilled development work.
I’m glad that this perception of operations is changing over time, and that more software engineers are doing the work of operating their own software. Dog smartness is a survival skill, and we need more of it.
Author’s note: I initially had the Yiddish wording incorrect, this post has been updated with the correct wording.
(This post was inspired by a conversation I had with a colleague).
On the evening before the launch of the Challenger Space Shuttle, representatives from NASA and the engineering contractor Thiokol held a telecon where they were concerned about the low overnight temperatures at the launch site. The NASA and Thiokol employees discussed whether to proceed with the launch or cancel it. On the call, there’s an infamous exchange between two Thiokol executives:
It’s time to take off your engineering hat and put on your management hat.
Senior Vice President Jerry Mason to Vice President of Engineering Robert Lund
The quote implies a conflict between the prudence of engineering and management’s reckless indifference to risk. The story is more complex than this quote suggests, as the sociologist Diane Vaughan discovered in her study of NASA’s culture. Here’s a teaser of her research results:
Contradicting conventional understandings, we find that (1) in every [Flight Readiness Review], Thiokol engineers brought forward recommendations to accept risk and fly and (2) rather than amoral calculation and misconduct, it was a preoccupation with rules, norms, and conformity that governed all facets of controversial managerial decisions at Marshall during this period.
But this blog post isn’t about the Challenger, or the contrasts between engineering and management. It’s about the times when we need to change hats.
I’m a fan of the you-build-it-you-run-it approach to software services, where the software engineers are responsible for operating the software they write. But solving ops problems isn’t like solving dev problems: the tempo and the skills involved are different, and they require different mindsets.
This difference is particularly acute for a software engineer when a change that they made contributed to an ongoing incident. Incidents are high pressure situations, and even someone in the best frame of mind can struggle with the challenges of making risky decisions under uncertainty. But if you’re thinking, “Argh, the service is down, and it’s all my fault!“, then your effectiveness is going to suffer. Your head’s not going to be in the right place.
And yet, these moments are exactly when it’s most important to be able to make the context switch between dev work and ops work. If someone took an action that triggered an outage, chances are good that they’re the person on the team who is best equipped to remediate, because they have the most context about the change.
Being the one who pushed the change that takes down the service sucks. But when we are most inclined to spend mental effort blaming ourselves is exactly when we can least afford to. Instead, we have to take off the dev hat, put on the ops hat, and do we can to get our head in the game. Because blaming ourselves in the moment isn’t going to make it any easier to get that service back up.
Making the rounds is the story of how Citi accidentally transferred $900 million dollars to various hedge funds. Citi then asked the funds to reverse the mistaken transfer, and while some of the funds did, others said, “no, it’s ours, and we’re keeping it”, and Citi took them to court, and lost. The wonderful finance writer Matt Levine has the whole story. At this center of this is horrible UX associated with internal software, you can see screenshots in Levine’s writeup. As an aside, several folks on the Hacker News thread recognized the UI widgets as having been built with Oracle Forms.
However, this post isn’t about a particular internal software package with lousy UX. (There is no shortage of such software packages in the world, ask literally anyone who deals with internal software).
Instead, I’m going to explore two questions:
How come we don’t hear about these sorts of accidental financial transactions more often?
How come financial organizations like Citibank don’t invest in improving internal software UX for reducing risk?
I’ve never worked in the financial industry, so I have no personal experience with this domain. But I suspect that accidental financial transactions, while rare, do happen from time to time. But what I suspect happens most of the time is that the institution that initiated the accidental transaction reaches out and explains what happens to the other institution, and they transfer the money back.
As Levine points out, there’s no finders keepers rule in the U.S. I suspect that there aren’t any organizations that have a risk scenario with the summary, “we accidentally transfer an enormous sum of money to an organization that is legally entitled to keep it.” because that almost never happens. This wasn’t a case of fraud. This was a weird edge case in the law where the money transferred was an accidental repayment of a loan in full, when Citi just meant to make an interest payment, and there’s a specific law about this scenario (in fact, Citi didn’t really want to make a payment at all, but they had to because of a technical issue).
Can you find any other time in the past where an institution accidentally transferred funds and the recipient was legally permitted to keep the money? If so, I’d love to hear it.
And, if it really is the case that these sorts of mistakes aren’t seen as a risk, then why would an organization like Citi invest in improving the usability of their internal tools? Heck, if you read the article, you’ll see that it was actually contractors that operate the software. It’s not like Citi would be more profitable if they were able to improve the usability of this software. “Who cares if it takes a contractor 10 minutes versus 30 minutes?” I can imagine an exec saying.
Don’t get me wrong: my day job is building internal tools, so I personally believe these tools add value. And I imagine that financial institutions invest in the tooling of their algorithmic traders, because correctness and development speed go directly to their bottom lines. But the folks operating the software that initiates these sorts of transactions? That’s just grunt work, nobody’s going to invest in improving those experiences.
In short, these systems don’t fall over all of the time because the systems aren’t just made up of horrible software. They’re made up of horrible software, and human beings who can exercise judgment when something goes wrong and compensate. Most of the time, that’s good enough.
Laura Nolan of Slack recently published an excellent write-up of their Jan. 4, 2021 outage on Slack’s engineering blog.
One of the things that struck me about this writeup is the contributing factors that aren’t part of this outage. There’s nothing about a bug that somehow made its way into a production, or an accidentally incorrect configuration change, or how some corrupt data ended up in the database. On the other hand, it’s an outage story with multiple examples of saturation.
Saturation is a phrase often used by the safety science researcher David Woods: it refers to a system that is reaching the limit of what it can handle. If you’ve done software operations work, I bet you’ve encountered resource exhaustion, which is an example of saturation.
Saturation plays a big role in Woods’s model of the adaptive universe. In particular, in socio-technical systems, people will adapt in order to reduce the risk of saturation. In this post, I’m going to walk Laura’s write-up, highlighting all of the examples of saturation and how the system adopted to it. I’m going purely from the text of the original write-up, which means I’ll likely get some things wrong here.
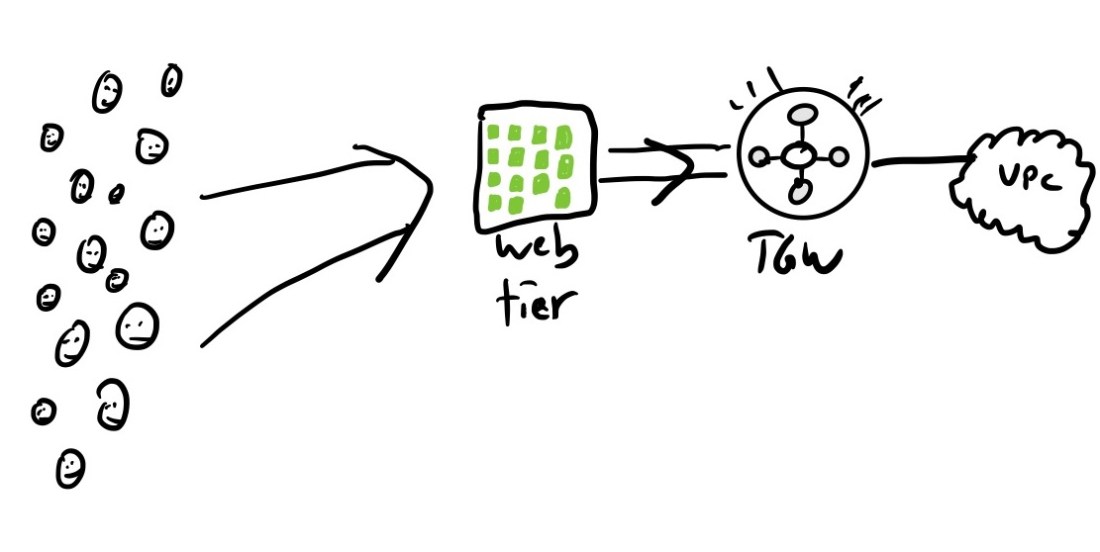
Slack runs their infrastructure on AWS. In the beginning, they (like, I presume, all small companies) started with a single AWS account. And, initially, this worked out well.
In the beginning, Slack’s AWS footprint fit nicely into one account and VPC: that’s one happy cloud!
As our customer base grew and the tool evolved, we developed more services and built more infrastructure as needed. However, everything we built still lived in one big AWS account. This is when our troubles started. Having all our infrastructure in a single AWS account led to AWS rate-limiting issues, cost-separation issues, and general confusion for our internal engineering service teams.
That cloud isn’t looking so happy anymore
The above quote makes reference to three different categories of saturation. The first is a traditional sort of limit we software folks think of: they were running into AWS rate limits associated with an individual AWS account.
The other two limits are cognitive: the system made it harder for humans to deal with separating out costs and, it led to confusion for internal teams. I still see these as a form of saturation: as a system gets more difficult for humans to deal with, it effectively increases the cost of using the system, and it makes errors more likely.
And so, the Slack Cloud Engineering team adapted to meet this saturation risk by adopting AWS child accounts. From the linked blog post again:
Now the service teams could request their own AWS accounts and could even peer their VPCs with each other when services needed to talk to other services that lived in a different AWS account.
Multiple happy child accounts
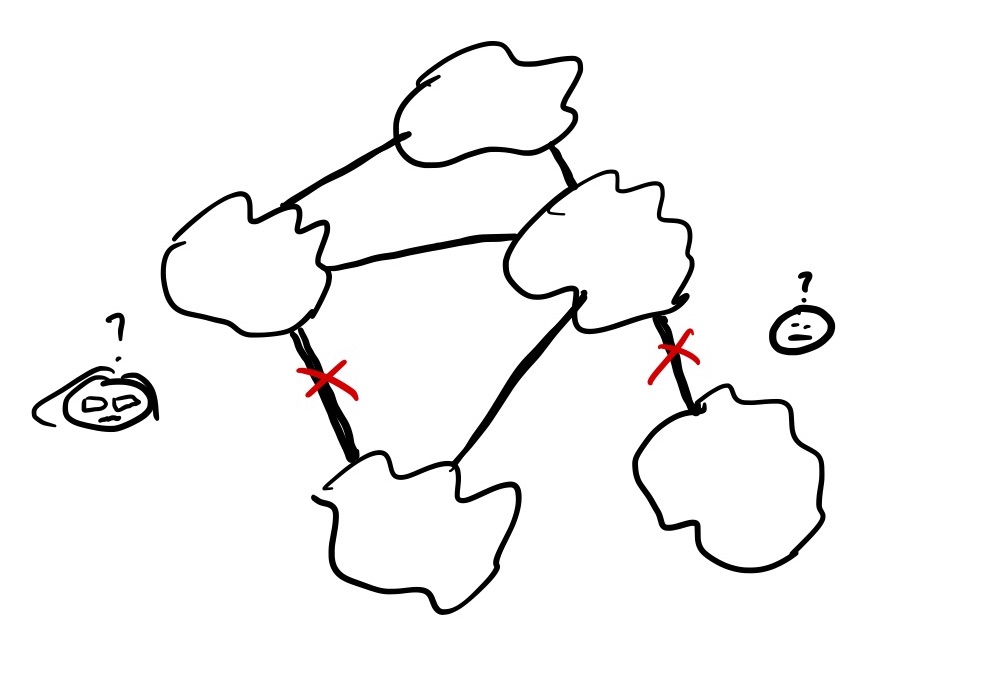
With continued growth, they eventually reached saturation again. Once again, this was the “it’s getting too hard” sort of saturation:
Having hundreds of AWS accounts became a nightmare to manage when it came to CIDR ranges and IP spaces, because the mis-management of CIDR ranges meant that we couldn’t peer VPCs with overlapping CIDR ranges. This led to a lot of administrative overhead.
VPC peering with multiple VPCs increases the cognitive load on the networking engineers
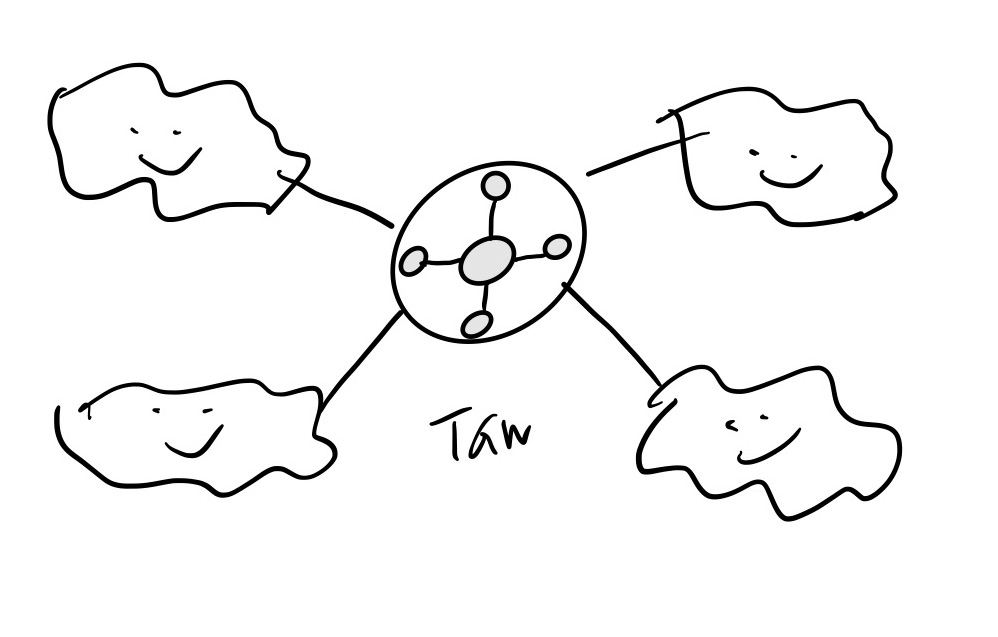
To deal with this risk of saturation, the cloud engineering team adapted again. They reached for new capabilities: AWS shared VPCs and AWS Transit Gateway Inter-Region Peering. By leveraging these technologies, they were able to design a network architecture that addressed their problems:
This solved our earlier issue of constantly hitting AWS rate limits due to having all our resources in one AWS account. This approach seemed really attractive to our Cloud Engineering team, as we could manage the IP space, build VPCs, and share them with our child account owners. Then, without having to worry about managing any of the overhead of setting up VPCs, route tables, or network access lists, teams were able to utilize these VPCs and build their resources on top of them.
Example of a transit gateway connecting multiple VPCs. Obviously, this does not accurately depict Slack’s actual network architecture.
Fast forward several months later. From Laura Nolan’s post:
On January 4th, one of our Transit Gateways became overloaded. The TGWs are managed by AWS and are intended to scale transparently to us. However, Slack’s annual traffic pattern is a little unusual: Traffic is lower over the holidays, as everyone disconnects from work (good job on the work-life balance, Slack users!). On the first Monday back, client caches are cold and clients pull down more data than usual on their first connection to Slack. We go from our quietest time of the whole year to one of our biggest days quite literally overnight. Our own serving systems scale quickly to meet these kinds of peaks in demand (and have always done so successfully after the holidays in previous years). However, our TGWs did not scale fast enough.
Traffic surge overwhelms the transit gateway
This is as clear an example of saturation as you can get: the incoming load increased faster than the transit gateways were able to cope. What’s really fascinating from this point on is the role that saturation plays in interactions with the rest of the system.
As too many of us know, clients experience a saturated network as an increase in latency. When network latency goes up, the threads in a service spend more of their time sitting there waiting for the bits to come over the network, which means that CPU utilization goes down.
Slack’s web tier autoscales on CPU utilization, so when the network started dropping packets, the instances in the web tier spent more of their time blocked, and CPU went down, which triggered the AWS autoscaler to downscale the web tier.
A server’s CPU utilization falls as it waits for packets that are being dropped by the overloaded transit gateway
However, the web tier has a scaling policy that rapidly upscales if thread utilization gets too high. (At Netflix, we use the term hammer rule to describe these type of emergency scale-up rule).
Too many threads are in use, waiting for those packets. Time for the scale-up hammer!
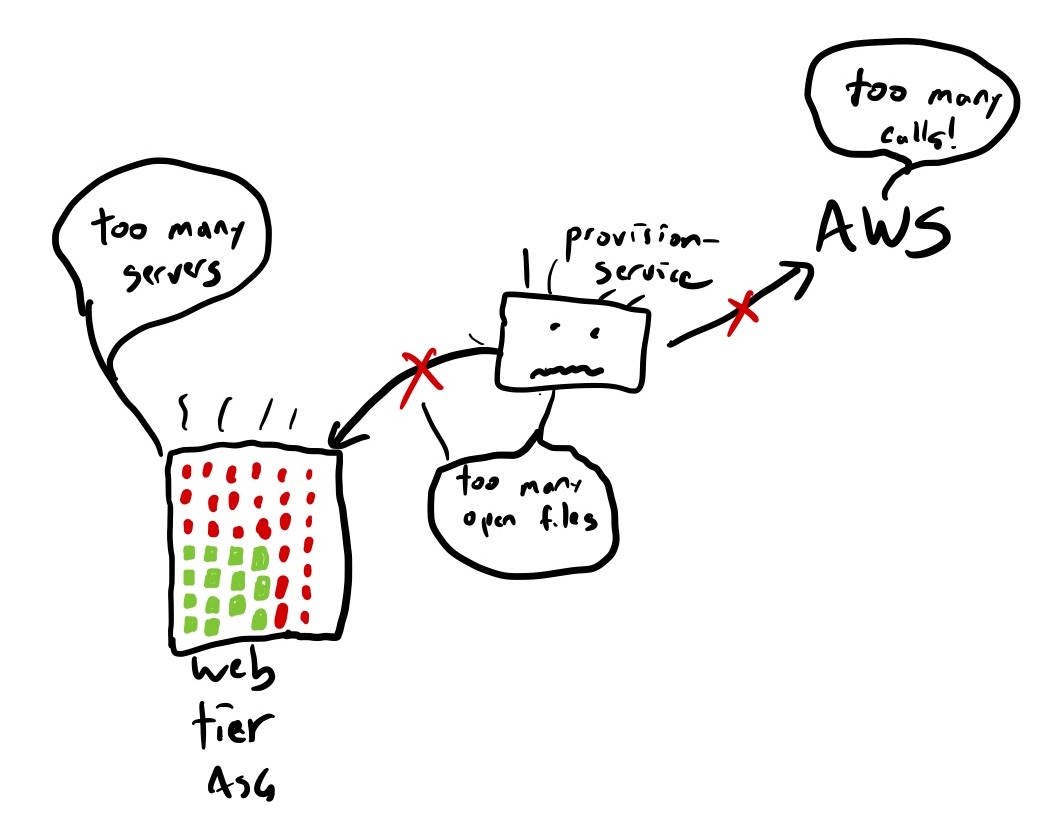
Once the new instances come online, an internal Slack service named provision-service is responsible for setting up these new instances so that they can serve traffic. And here, we see more saturation issues (emphasis mine).
Provision-service needs to talk to other internal Slack systems and to some AWS APIs. It was communicating with those dependencies over the same degraded network, and like most of Slack’s systems at the time, it was seeing longer connection and response times, and therefore was using more system resources than usual. The spike of load from the simultaneous provisioning of so many instances under suboptimal network conditions meant that provision-service hit two separate resource bottlenecks (the most significant one was the Linux open files limit, but we also exceeded an AWS quota limit).
While we were repairing provision-service, we were still under-capacity for our web tier because the scale-up was not working as expected. We had created a large number of instances, but most of them were not fully provisioned and were not serving. The large number of broken instances caused us to hit our pre-configured autoscaling-group size limits, which determine the maximum number of instances in our web tier.
The provision service is saturated, as is the autoscaling group, although many of the instances aren’t serving traffic because they aren’t fully provisioned.
Through a combination of robustness mechanisms (load balancer panic mode, retries, circuit breakers) and the actions of human operators, the system is restored to health.
As operators, we strive to keep our systems far from the point of saturation. As a consequence, we generally don’t have much experience with how the system behaves as it approaches saturation. And that makes these incidents much harder to deal with.
Making things worse, we can’t ever escape the risk of saturation. Often we won’t know that a limit exists until the system breaches it.