Recently, Salesforce released a public incident writeup for a service outage that happened in mid-May. There’s a lot of good stuff in here (DNS! A config change!), but I want to focus on one aspect of the writeup, a contributing factor described in the writeup as Subversion of the Emergency Break Fix (EBF) process.
Here are some excerpts from that section of the writeup (emphasis in the original):
An [Emergency Break Fix] is an unplanned and urgent change that is required to prevent or remediate a Severity-0, a Severity-1, or a Severity-2 incident… Non-urgent changes, i.e. those which do not require immediate attention, should not be deployed as EBFs.
…In this situation, there was no active or imminent Severity-0, Severity-1 or Severity-2 incident, so the EBF process should not have been used, and standard Salesforce stagger processes should not have been ignored.
By following an emergency process, this change avoided the extensive review scrutiny that would have occurred had it been made as a standard change under the Salesforce Change Traffic Control (CTC) process. … In this case, the engineer subverted the known policy and the appropriate disciplinary action has been taken to ensure this does not happen in the future.
“What was the engineer thinking? “ a reader wonders. I certainly did. People make decisions for reasons that make sense to them. I have no idea what the engineer’s reasoning was here, because there’s not even a hint of that reasoning alluded to here.
Is this process commonly circumvented by engineers for some reason? (i.e., was this situation actually more common than the writeup lets on?) Alternately, was the engineer facing atypical time pressure? If so, what was the nature of the time pressure?
One of the functions of public writeups is to give customers confidence in the organization’s ability to deal with future incidents. This section had the opposite effect, it filled me with dread. It communicates to me that the organization is not interested in understanding how actual work is done.
Woe be it to the next engineer caught in the double bind where there will be consequences if they don’t work quickly enough and there will be consequences if they don’t conform to a process that slows them down so much that they can’t get their work done quickly enough.
I take the opposite approach: I never write any of my reports anonymously. Instead, I explicitly specify the names of all of the people involved. I wanted to write a post on why I do that.
I understand the motivation for providing anonymity. We feel guilt and shame when our changes contribute to an incident. The safety literature refers to this as second victim phenomenon. We don’t write down an engineer’s name in a report because we don’t want to exacerbate the second victim effect. Also, the incident is about the system, not the particular engineer.
The reason I take the opposite approach of naming names is that I want to normalize the fact that incidents are aspects of the system, not the individuals. I feel like providing anonymity implicitly sends the signal that “the names are omitted to protect the guilty.”
My strategy in doing these writeups is to lean as heavily as I can into demonstrating to the reader that all actions taken by the engineers involved were reasonable in the moment. I want them to read the writeup and think, “This could have been me!”. I want to try to get the organization to a point where there is no shame in contributing to an incident, it’s an inevitable aspect of the work that we do.
In order to do this well, I try to write these up as much as possible from the perspective of the people involved. I find it really helps make the writeups look less judge-y (“normative”, in the jargon) by telling the story from the perspective of the individual, and calling attention to the systemic aspects.
And so, while I think Alex and I are both trying to get to the same place, we’re taking different routes.
We seldom have time for introspection at work. If we’re lucky, we have the opportunity to do some kind of retrospective at the end of a project or sprint. But, generally speaking, we’re too busy working to spend time examining that work.
One exception to this is incidents: organizations are willing to spend effort on introspection after an incident happens. That’s because incidents are unsettling: people feel uneasy that the system failed in a way they didn’t expect.
And so, an organization is willing to spend precious engineering cycles in order to rid itself of the uneasy feeling that comes with a system failing unexpectedly. Let’s make sure this never happens again.
Incident analysis, in the learning from incidents in software (LFI) sense, is about using an incident as an opportunity to get a better understanding of how the overall system works. It’s a kind of case study, where the case is the incident. The incident acts as a jumping-off point for an analyst to study an aspect of the system. Just like any other case study, it involves collecting and synthesizing data from multiple sources (e.g., interviews, chat transcripts, metrics, code commits).
I call it a guerrilla case study because, from the organization’s perspective, the goal is really to get closure, to have a sense that all is right with the world. People want to get to a place where the failure mode is now well-understood and measures will be put in place to prevent it from happening again. As LFI analysts, we’re exploiting this desire for closure to justify spending time examining how work is really done inside of the system.
Ideally, organizations would recognize the value of this sort of work, and would make it explicit that the goal of incident analysis is to learn as much as possible. They’d also invest in other types of studies that look into how the overall system works. Alas, that isn’t the world we live in, so we have to sneak this sort of work in where we can.
Half a league, half a league, Half a league onward, All in the valley of Death Rode the six hundred. “Forward, the Light Brigade! Charge for the guns!” he said: Into the valley of Death Rode the six hundred.
“Forward, the Light Brigade!” Was there a man dismay’d? Not tho’ the soldier knew Some one had blunder’d: Theirs not to make reply, Theirs not to reason why, Theirs but to do and die: Into the valley of Death Rode the six hundred.
Cannon to right of them, Cannon to left of them, Cannon in front of them Volley’d and thunder’d; Storm’d at with shot and shell, Boldly they rode and well, Into the jaws of Death, Into the mouth of Hell Rode the six hundred.
Flash’d all their sabres bare, Flash’d as they turn’d in air Sabring the gunners there, Charging an army, while All the world wonder’d: Plunged in the battery-smoke Right thro’ the line they broke; Cossack and Russian Reel’d from the sabre-stroke Shatter’d and sunder’d. Then they rode back, but not Not the six hundred.
Cannon to right of them, Cannon to left of them, Cannon behind them Volley’d and thunder’d; Storm’d at with shot and shell, While horse and hero fell, They that had fought so well Came thro’ the jaws of Death, Back from the mouth of Hell, All that was left of them, Left of six hundred.
When can their glory fade? O the wild charge they made! All the world wonder’d. Honor the charge they made! Honor the Light Brigade, Noble six hundred!
The Charge of the Light Brigade, Alfred Lord Tennyson
One of the challenges of building distributed systems is that communications channels are unreliable. This challenge is captured in what is known as the Two Generals’ Problem. It goes something like this:
Two generals from the same army are camped at opposite sides of a valley. The enemy troops are stationed in the valley. The generals need to coordinate their attack in order to succeed. Neither general will risk their troops unless they know for certain that the other general will attack at the same time.
They only mechanism the generals have to communicate is by sending messages via carrier pigeon that fly over the valley. The problem is that enemy archers in the valley are sometimes able to shoot down these carrier pigeons, and so a general sending a message has no guarantee that it will be received by the other general.
One general sends a message to another across the valley via carrier pigeon
The first general sends the message: Let’s attack Monday at dawn, and waits for an acknowledgment. If he doesn’t get an acknowledgment, he can’t be certain the message was received, and so he can’t attack. He receives an acknowledgment in return. But now he thinks, “What if the other general doesn’t know I’ve received the acknowledgment? He knows I won’t carry out the attack unless I know for certain that he agrees to the plan, and he doesn’t know whether I’ve received an acknowledgment or not. I’d better send a message acknowledging the message.”
This becomes an infinite regress problem: it turns out that no number of acknowledgments and acknowledgment-of-acknowledgments that can ensure that the two generals have common knowledge (“I know that he knows that I know that he knows…”) when communicating over an unreliable channel.
One implicit assumption of the Two Generals’ Problem is that when a message is received, it is understood perfectly by the recipient. In the world of real systems, understanding the intent of a message is often a challenge. I’m going to call this the British General’s Problem, in honor of General Raglan.
Raglan was a British general during the Crimean War. The messages he sent to Lord Lucan at the front were misinterpreted, and these misinterpretations contributed to a disastrous attack by British Light Calvary against fortified Russian troops, famously memorialized in Alfred Lord Tennyson’s poem at the top of this post.
Lord Lucan is confused by General Raglan’s message
Tim Harford tells the story of the misunderstanding, and the different personalities involved in the affair, in the wonderful episode of the Cautionary Tales podcast The Curse of Knowledge meets the Valley of Death.
This story is a classic example of a common ground breakdown, a phenomenon described in the famous paper Common Ground and Coordination in Joint Activity by Gary Klein, Paul Feltovich, Jeffrey Bradshaw and David Woods. In the paper, the authors describe how common ground is necessary for people to coordinate effectively to achieve a shared goal. A common ground breakdown happens when a misunderstanding occurs among the people coordinating.
If you do operations work, and you’ve been involved in remediating an incident while communicating over Slack, you’ve experience the challenge of maintaining common ground. Because common ground breakdowns are common, coordination requires ongoing effort to repair this common ground. This is the topic of Laura Maguire’s PhD thesis: Controlling the Costs of Coordination in Large-scale Distributed Software Systems (which, I must admit, I haven’t yet read).
The British General’s problem is a reminder of the challenges we inevitably face in socio-technicalsystems. The real problem is not unreliable channels: it’s building and maintaining the shared understanding in order to get the coordination work done.
One of my hobbies is learning Yiddish. Growing up Jewish in Montreal, I attended a parochial elementary school that taught Yiddish (along with French and Hebrew), but dropped it after that. A couple of years ago, I discovered a Yiddish teacher in my local area and I started taking classes for fun.
Our teacher recently introduced us to a Yiddish expression, hintish-kloog, which translates literally as “dog smartness”. It refers to a dog’s ability to sniff out and locate food in all sorts of places.
This made me think of the kind of skill required to solve operational problems during the moment. It’s a very different kind of skill than, say, constructing abstractions during software development. Instead, it’s more about employing a set of heuristics to try to diagnose the issue, hunting through our dashboards to look for useful signals. “Did something change recently? Are errors up? Is the database healthy?”
My teacher noted that that many of the more religious Jews tend to look down on owning a dog, and so hintish-kloog is meant in a pejorative sense: this isn’t the kind of intelligence that is prized by scholars. This made me think about the historical difference in prestige between development and operations work, where skilled operations work is seen as a lower form of work than skilled development work.
I’m glad that this perception of operations is changing over time, and that more software engineers are doing the work of operating their own software. Dog smartness is a survival skill, and we need more of it.
Author’s note: I initially had the Yiddish wording incorrect, this post has been updated with the correct wording.
(This post was inspired by a conversation I had with a colleague).
On the evening before the launch of the Challenger Space Shuttle, representatives from NASA and the engineering contractor Thiokol held a telecon where they were concerned about the low overnight temperatures at the launch site. The NASA and Thiokol employees discussed whether to proceed with the launch or cancel it. On the call, there’s an infamous exchange between two Thiokol executives:
It’s time to take off your engineering hat and put on your management hat.
Senior Vice President Jerry Mason to Vice President of Engineering Robert Lund
The quote implies a conflict between the prudence of engineering and management’s reckless indifference to risk. The story is more complex than this quote suggests, as the sociologist Diane Vaughan discovered in her study of NASA’s culture. Here’s a teaser of her research results:
Contradicting conventional understandings, we find that (1) in every [Flight Readiness Review], Thiokol engineers brought forward recommendations to accept risk and fly and (2) rather than amoral calculation and misconduct, it was a preoccupation with rules, norms, and conformity that governed all facets of controversial managerial decisions at Marshall during this period.
But this blog post isn’t about the Challenger, or the contrasts between engineering and management. It’s about the times when we need to change hats.
I’m a fan of the you-build-it-you-run-it approach to software services, where the software engineers are responsible for operating the software they write. But solving ops problems isn’t like solving dev problems: the tempo and the skills involved are different, and they require different mindsets.
This difference is particularly acute for a software engineer when a change that they made contributed to an ongoing incident. Incidents are high pressure situations, and even someone in the best frame of mind can struggle with the challenges of making risky decisions under uncertainty. But if you’re thinking, “Argh, the service is down, and it’s all my fault!“, then your effectiveness is going to suffer. Your head’s not going to be in the right place.
And yet, these moments are exactly when it’s most important to be able to make the context switch between dev work and ops work. If someone took an action that triggered an outage, chances are good that they’re the person on the team who is best equipped to remediate, because they have the most context about the change.
Being the one who pushed the change that takes down the service sucks. But when we are most inclined to spend mental effort blaming ourselves is exactly when we can least afford to. Instead, we have to take off the dev hat, put on the ops hat, and do we can to get our head in the game. Because blaming ourselves in the moment isn’t going to make it any easier to get that service back up.
Making the rounds is the story of how Citi accidentally transferred $900 million dollars to various hedge funds. Citi then asked the funds to reverse the mistaken transfer, and while some of the funds did, others said, “no, it’s ours, and we’re keeping it”, and Citi took them to court, and lost. The wonderful finance writer Matt Levine has the whole story. At this center of this is horrible UX associated with internal software, you can see screenshots in Levine’s writeup. As an aside, several folks on the Hacker News thread recognized the UI widgets as having been built with Oracle Forms.
However, this post isn’t about a particular internal software package with lousy UX. (There is no shortage of such software packages in the world, ask literally anyone who deals with internal software).
Instead, I’m going to explore two questions:
How come we don’t hear about these sorts of accidental financial transactions more often?
How come financial organizations like Citibank don’t invest in improving internal software UX for reducing risk?
I’ve never worked in the financial industry, so I have no personal experience with this domain. But I suspect that accidental financial transactions, while rare, do happen from time to time. But what I suspect happens most of the time is that the institution that initiated the accidental transaction reaches out and explains what happens to the other institution, and they transfer the money back.
As Levine points out, there’s no finders keepers rule in the U.S. I suspect that there aren’t any organizations that have a risk scenario with the summary, “we accidentally transfer an enormous sum of money to an organization that is legally entitled to keep it.” because that almost never happens. This wasn’t a case of fraud. This was a weird edge case in the law where the money transferred was an accidental repayment of a loan in full, when Citi just meant to make an interest payment, and there’s a specific law about this scenario (in fact, Citi didn’t really want to make a payment at all, but they had to because of a technical issue).
Can you find any other time in the past where an institution accidentally transferred funds and the recipient was legally permitted to keep the money? If so, I’d love to hear it.
And, if it really is the case that these sorts of mistakes aren’t seen as a risk, then why would an organization like Citi invest in improving the usability of their internal tools? Heck, if you read the article, you’ll see that it was actually contractors that operate the software. It’s not like Citi would be more profitable if they were able to improve the usability of this software. “Who cares if it takes a contractor 10 minutes versus 30 minutes?” I can imagine an exec saying.
Don’t get me wrong: my day job is building internal tools, so I personally believe these tools add value. And I imagine that financial institutions invest in the tooling of their algorithmic traders, because correctness and development speed go directly to their bottom lines. But the folks operating the software that initiates these sorts of transactions? That’s just grunt work, nobody’s going to invest in improving those experiences.
In short, these systems don’t fall over all of the time because the systems aren’t just made up of horrible software. They’re made up of horrible software, and human beings who can exercise judgment when something goes wrong and compensate. Most of the time, that’s good enough.
Laura Nolan of Slack recently published an excellent write-up of their Jan. 4, 2021 outage on Slack’s engineering blog.
One of the things that struck me about this writeup is the contributing factors that aren’t part of this outage. There’s nothing about a bug that somehow made its way into a production, or an accidentally incorrect configuration change, or how some corrupt data ended up in the database. On the other hand, it’s an outage story with multiple examples of saturation.
Saturation is a phrase often used by the safety science researcher David Woods: it refers to a system that is reaching the limit of what it can handle. If you’ve done software operations work, I bet you’ve encountered resource exhaustion, which is an example of saturation.
Saturation plays a big role in Woods’s model of the adaptive universe. In particular, in socio-technical systems, people will adapt in order to reduce the risk of saturation. In this post, I’m going to walk Laura’s write-up, highlighting all of the examples of saturation and how the system adopted to it. I’m going purely from the text of the original write-up, which means I’ll likely get some things wrong here.
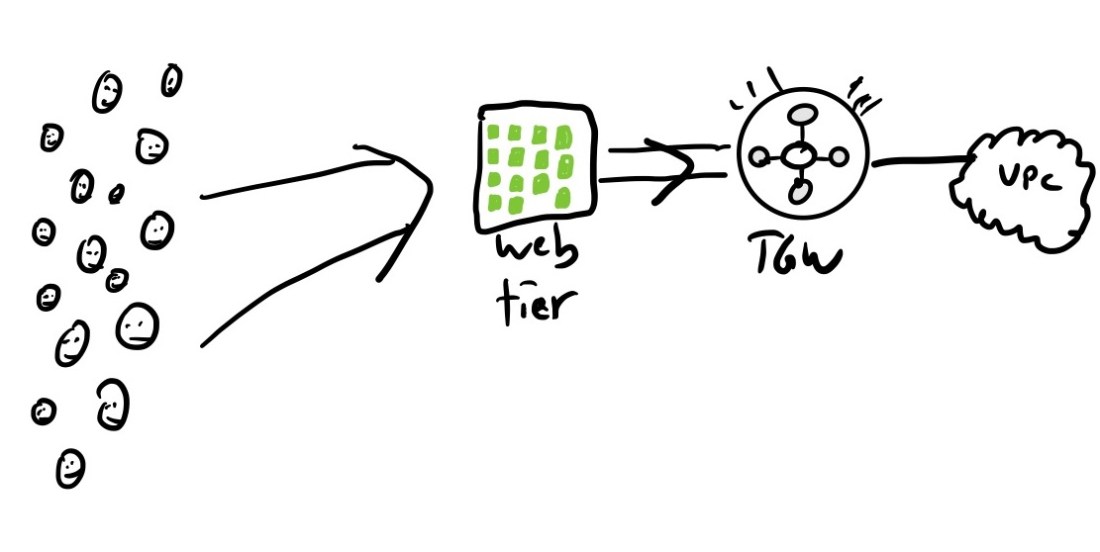
Slack runs their infrastructure on AWS. In the beginning, they (like, I presume, all small companies) started with a single AWS account. And, initially, this worked out well.
In the beginning, Slack’s AWS footprint fit nicely into one account and VPC: that’s one happy cloud!
As our customer base grew and the tool evolved, we developed more services and built more infrastructure as needed. However, everything we built still lived in one big AWS account. This is when our troubles started. Having all our infrastructure in a single AWS account led to AWS rate-limiting issues, cost-separation issues, and general confusion for our internal engineering service teams.
That cloud isn’t looking so happy anymore
The above quote makes reference to three different categories of saturation. The first is a traditional sort of limit we software folks think of: they were running into AWS rate limits associated with an individual AWS account.
The other two limits are cognitive: the system made it harder for humans to deal with separating out costs and, it led to confusion for internal teams. I still see these as a form of saturation: as a system gets more difficult for humans to deal with, it effectively increases the cost of using the system, and it makes errors more likely.
And so, the Slack Cloud Engineering team adapted to meet this saturation risk by adopting AWS child accounts. From the linked blog post again:
Now the service teams could request their own AWS accounts and could even peer their VPCs with each other when services needed to talk to other services that lived in a different AWS account.
Multiple happy child accounts
With continued growth, they eventually reached saturation again. Once again, this was the “it’s getting too hard” sort of saturation:
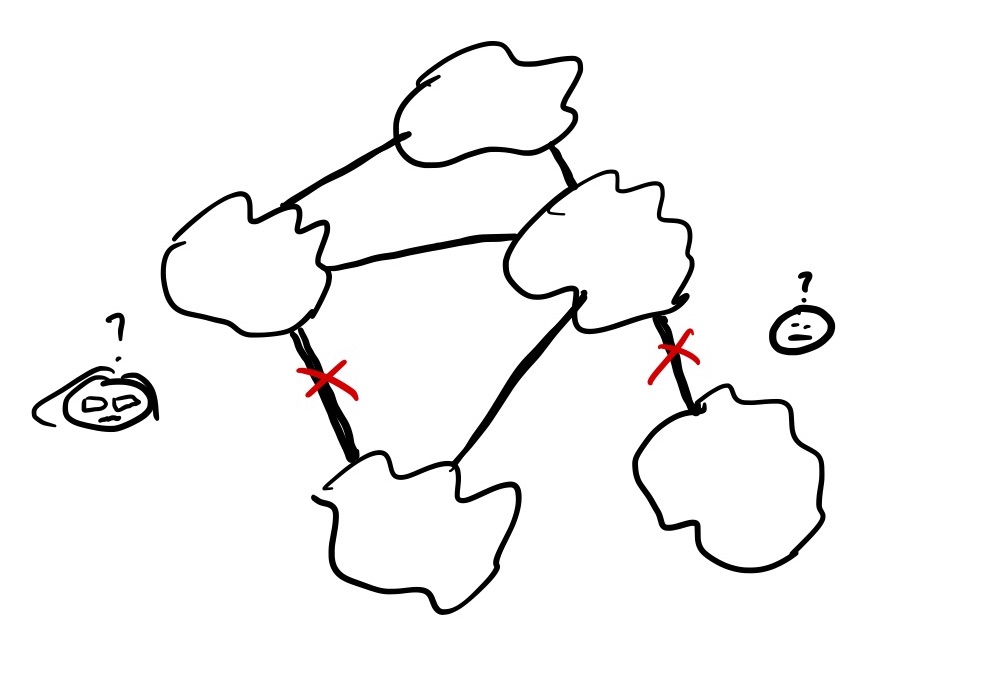
Having hundreds of AWS accounts became a nightmare to manage when it came to CIDR ranges and IP spaces, because the mis-management of CIDR ranges meant that we couldn’t peer VPCs with overlapping CIDR ranges. This led to a lot of administrative overhead.
VPC peering with multiple VPCs increases the cognitive load on the networking engineers
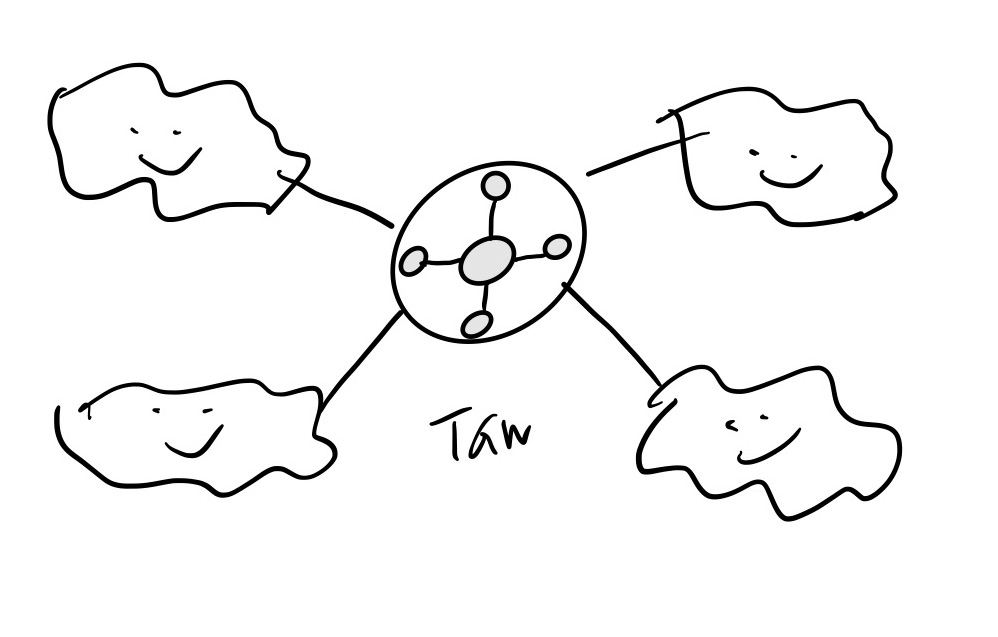
To deal with this risk of saturation, the cloud engineering team adapted again. They reached for new capabilities: AWS shared VPCs and AWS Transit Gateway Inter-Region Peering. By leveraging these technologies, they were able to design a network architecture that addressed their problems:
This solved our earlier issue of constantly hitting AWS rate limits due to having all our resources in one AWS account. This approach seemed really attractive to our Cloud Engineering team, as we could manage the IP space, build VPCs, and share them with our child account owners. Then, without having to worry about managing any of the overhead of setting up VPCs, route tables, or network access lists, teams were able to utilize these VPCs and build their resources on top of them.
Example of a transit gateway connecting multiple VPCs. Obviously, this does not accurately depict Slack’s actual network architecture.
Fast forward several months later. From Laura Nolan’s post:
On January 4th, one of our Transit Gateways became overloaded. The TGWs are managed by AWS and are intended to scale transparently to us. However, Slack’s annual traffic pattern is a little unusual: Traffic is lower over the holidays, as everyone disconnects from work (good job on the work-life balance, Slack users!). On the first Monday back, client caches are cold and clients pull down more data than usual on their first connection to Slack. We go from our quietest time of the whole year to one of our biggest days quite literally overnight. Our own serving systems scale quickly to meet these kinds of peaks in demand (and have always done so successfully after the holidays in previous years). However, our TGWs did not scale fast enough.
Traffic surge overwhelms the transit gateway
This is as clear an example of saturation as you can get: the incoming load increased faster than the transit gateways were able to cope. What’s really fascinating from this point on is the role that saturation plays in interactions with the rest of the system.
As too many of us know, clients experience a saturated network as an increase in latency. When network latency goes up, the threads in a service spend more of their time sitting there waiting for the bits to come over the network, which means that CPU utilization goes down.
Slack’s web tier autoscales on CPU utilization, so when the network started dropping packets, the instances in the web tier spent more of their time blocked, and CPU went down, which triggered the AWS autoscaler to downscale the web tier.
A server’s CPU utilization falls as it waits for packets that are being dropped by the overloaded transit gateway
However, the web tier has a scaling policy that rapidly upscales if thread utilization gets too high. (At Netflix, we use the term hammer rule to describe these type of emergency scale-up rule).
Too many threads are in use, waiting for those packets. Time for the scale-up hammer!
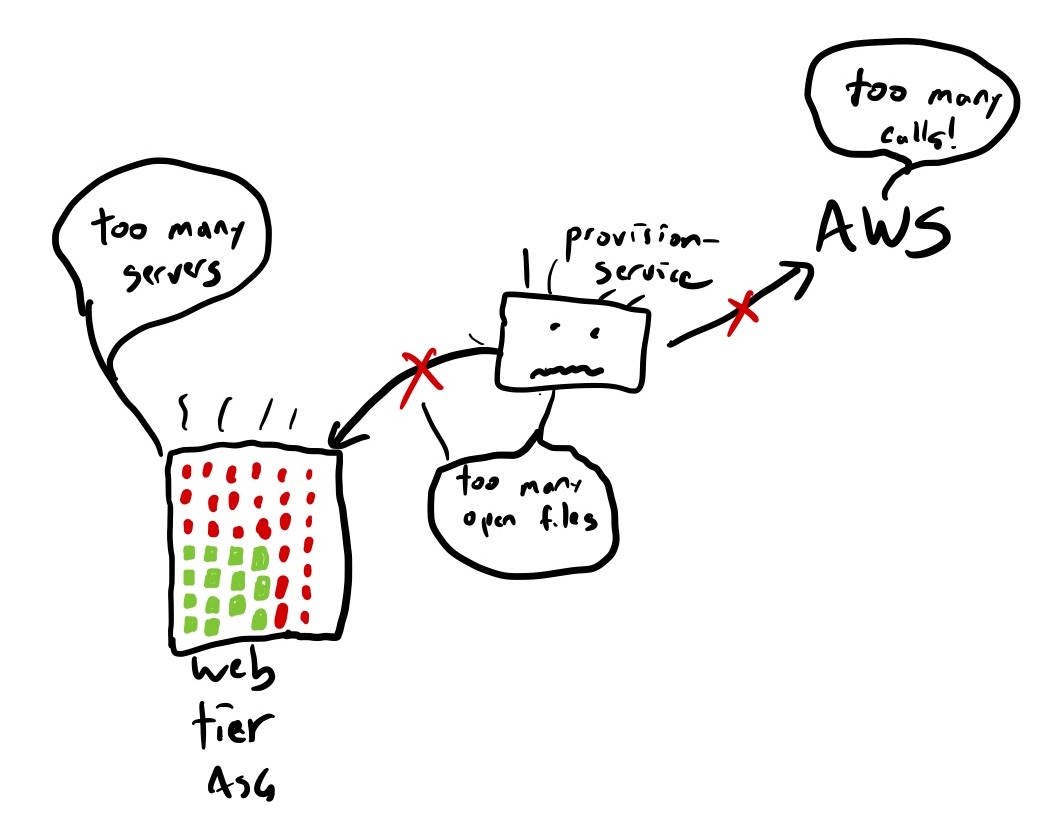
Once the new instances come online, an internal Slack service named provision-service is responsible for setting up these new instances so that they can serve traffic. And here, we see more saturation issues (emphasis mine).
Provision-service needs to talk to other internal Slack systems and to some AWS APIs. It was communicating with those dependencies over the same degraded network, and like most of Slack’s systems at the time, it was seeing longer connection and response times, and therefore was using more system resources than usual. The spike of load from the simultaneous provisioning of so many instances under suboptimal network conditions meant that provision-service hit two separate resource bottlenecks (the most significant one was the Linux open files limit, but we also exceeded an AWS quota limit).
While we were repairing provision-service, we were still under-capacity for our web tier because the scale-up was not working as expected. We had created a large number of instances, but most of them were not fully provisioned and were not serving. The large number of broken instances caused us to hit our pre-configured autoscaling-group size limits, which determine the maximum number of instances in our web tier.
The provision service is saturated, as is the autoscaling group, although many of the instances aren’t serving traffic because they aren’t fully provisioned.
Through a combination of robustness mechanisms (load balancer panic mode, retries, circuit breakers) and the actions of human operators, the system is restored to health.
As operators, we strive to keep our systems far from the point of saturation. As a consequence, we generally don’t have much experience with how the system behaves as it approaches saturation. And that makes these incidents much harder to deal with.
Making things worse, we can’t ever escape the risk of saturation. Often we won’t know that a limit exists until the system breaches it.
Here’s a question that all of us software developers face: How can we best use our knowledge about the past behavior of our system to figure out where we should be investing our time?
One approach is to use a technique from the SRE world called error budgets. Here are a few quotes from the How to Use Error Budgets chapter of Alex Hidalgo’s book: Implementing Service Level Objectives:
Measuring error budgets over time can give you great insight into the risk factors that impact your service, both in terms of frequency and severity. By knowing what kinds of events and failures are bad enough to burn your error budget, even if just momentarily, you can better discover what factors cause you the most problems over time. p71 [emphasis mine]
The basic idea is straightforward. If you have error budget remaining, ship new features and push to production as often as you’d like; once you run out of it, stop pushing feature changes and focus on relaiability instead. p87
Error budgets give you ways to make decisions about your service, be it a single microservice or your company’s entire customer-facing product. They also give you indicators that tell you when you can ship features, what your focus should be, when you can experiment, and what your biggest risk factors are. p92
The goal is not to only react when your users are extremely unhappy with you—it’s to have better data to discuss where work regarding your service should be moving next. p354
That sounds reasonable, doesn’t it? Look at what’s causing your system to break, and if it’s breaking too often, use that as a signal to address those issues that are breaking it. If you’ve been doing really well reliability-wise, an error budget gives you margin to do some riskier experimentation in production like chaos engineering or production load testing.
I have two issues with this approach, a smaller one and a larger one. I’ll start with the smaller one.
First, I think that if you work on a team where the developers operate their own code (you-build-it, you-run-it), and where the developers have enough autonomy to say, “We need to focus more development effort on increasing robustness”, then you don’t need the error budget approach to help you decide when and where to spend your engineering effort. The engineers will know where the recurring problems are because they feel the operational pain, and they will be able to advocate for addressing those pain points. This is the kind of environment that I am fortunate enough to work in.
I understand that there are environments where the developers and the operators are separate populations, or the developers aren’t granted enough autonomy to be able to influence where engineering time is spent, and that in those environments, an error budget approach would help. But I don’t swim in those waters, so I won’t say any more about those contexts.
To explain my second concern, I need to digress a little bit to talk about Herbert Heinrich.
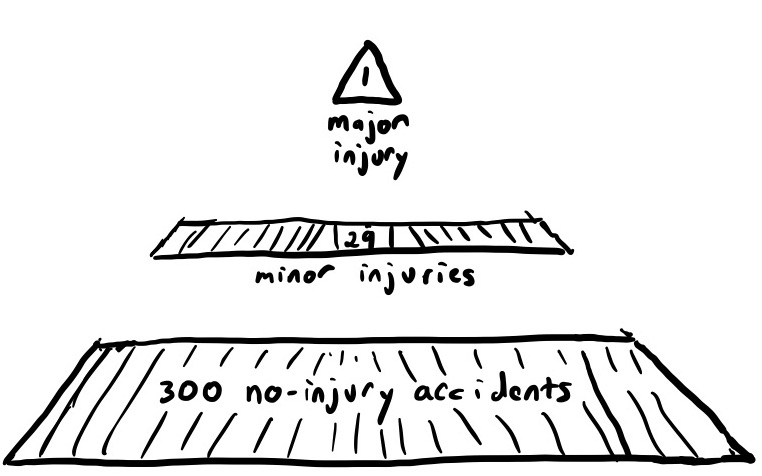
Herbert Heinrich worked for the Travelers Insurance Company in the first half of the twentieth century. In the 1920s, he did a study of workplace accidents, examining thousands of claims made by companies that held insurance policies with Travelers. In 1931, he published his findings in a book: Industrial Accident Prevention: A Scientific Approach.
Heinrich’s work showed a relationship between the rates of near misses (no injury), minor injuries, and major injuries. Specifically: for every major injury, there are 29 minor injuries, and 300 no-injury accidents. This finding of 1:29:300 became known as the accident triangle.
One implication of the accident triangle is that the rate of minor issues gives us insight into the rate of major issues. In particular, if we reduce the rate of minor issues, we reduce the risk of major ones. Or, as Heinrich put it: Moral—prevent the accidents and the injuries will take care of themselves.
Heinrich’s work has since been criticized, and subsequent research has contradicted Heinrich’s findings. I won’t repeat the criticisms here (see Foundations of Safety Science by Sidney Dekker for details), but I will cite counterexamples mentioned in Dekker’s book:
So, what does any of this have to do with error budgets? At a glance, error budgets don’t seem related to Heinrich’s work at all. Heinrich was focused on safety, where the goal is to reduce injuries as much as possible, in some cases explicitly having a zero goal. Error budgets are explicitly not about achieving zero downtime (100% reliability), they’re about achieving a target that’s below 100%.
Here are the claims I’m going to make:
Large incidents are much more costly to organizations than small ones, so we should work to reduce the risk of large incidents.
Error budgets don’t help reduce risk of large incidents.
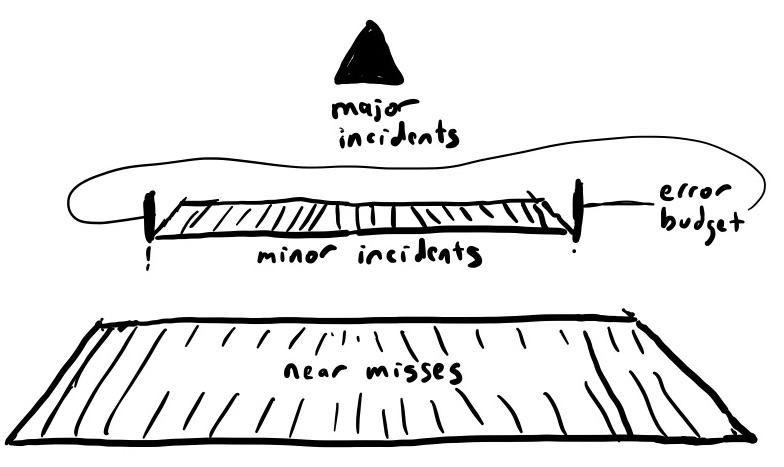
Here’s Heinrich’s triangle redrawn:
An error-budget-based approach only provides information on the nature of minor incidents, because those are the ones that happen most often. Near misses don’t impact the reliability metrics, and major incidents blow them out of the water.
Heinrich’s work assumed a fixed ratio between minor accidents and major ones: reduce the rate of minor accidents and you’d reduce the rate of major ones. By focusing on reliability metrics as a primary signal for providing insight into system risk, you only get information about these minor incidents. But, if there’s no relationship between minor incidents and major ones, then maintaining a specific reliability level doesn’t address the issues around major incidents at all.
An error-budget-based approach to reliability implicitly assumes there is a connection between reliability metrics and the risk of a large incident. This is the thread that connects to Heinrich: the unstated idea that doing the robustness work to address the problems exposed by the smaller incidents will decrease the risk of the larger incidents.
In general, I’m skeptical about relying on predefined metrics, such as reliability, for getting insight into the risks of the system that could lead to big incidents. Instead, I prefer to focus on signals, which are not predefined metrics but rather some kind of information that has caught your attention that suggests that there’s some aspect of your system that you should dig into a little more. Maybe it’s a near-miss situation where there was no customer impact at all, or maybe it was an offhand remark made by someone in Slack. Signals by themselves don’t provide enough information to tell you where unseen risks are. Instead, they act as clues that can help you figure out where to dig to get more details. This is what the Learning from Incidents in Software movement is about.
I’m generally skeptical of metrics-based approaches, like error budgets, because they reify. The things that get measured are the things that get attention. I prefer to rely on qualitative approaches that leverage the experiment judgment of engineers. The challenge with qualitative approaches is that you need to expose the experts to the information they need (e.g., putting the software engineers on-call), and they need the space to dig into signals (e.g., allow time for incident analysis).
Scott Nasello recently introduced me to Dr. Hannah Harvey’s The Art of Storytelling. I’m about halfway through her course, and I absolutely love it, and I keep thinking about it in the context of learning from incidents. While I have long been an advocate of using narrative structure when writing up incidents, Harvey’s course focuses on oral storytelling, which is a very different sort of format.
In this context, I was thinking about an operational surprise that happened on my team a few months ago, so that I could use it as raw material to construct an oral story about it. But, as I reflected on it, and read my own (lengthy) writeup, I realized that there was one thing I didn’t fully understand about what happened.
During the operational surprise, when we attempted to remediate the problem by deploying a potential fix into production, we hit a latent bug that had been merged into the main branch ten days earlier. As i was re-reading the writeup, there was something I didn’t understand. How did it come to be that we went ten days without promoting that code from the main branch of our repo to the production environment?
To help me make sense of what happened, I drew a diagram of the development events that lead up to the surprise. Fortunately, I had documented those events thoroughly in the original writeup. Here’s the diagram I created. I used this diagram to get some insight into how bug T2, which was merged into our repo on day 0, did not manifest in production until day 10.
This diagram will take some explanation, so bear with me.
There are four bugs in this story, denoted T1,T2, A1, A2. The letters indicate the functionality associated with the PR that introduced them:
T1, T2 were both introduced in a pull request (PR) related to refactoring of some functionality related to how our service interacts with Titus.
A1, A2 were both introduced in a PR related to adding functionality around artifact metadata.
Note that bug T1 masked T2, and bug A1 masked A2.
There are three vertical lines, which show how the bugs propagated to different environments.
main (repo) represents code in the main branch of our repository.
staging represents code that has been deployed to our staging environment.
prod represents code that has been deployed to our production environment.
Here’s how the colors work:
gray indicates that the bug is present in an environment, but hasn’t been detected
red indicates that the effect of a bug has been observed in an environment. Note that if we detect a bug in the prod environment, that also tells us that the bug is in staging and the repo.
green indicates the bug has been fixed
If a horizontal line is red, that means there’s a known bug in that environment. For example, when we detect bug T1 in prod on day 1, all three lines go red, since we know we have a bug.
A horizontal line that is purple means that we’ve pinned to a specific version. We unpinned prod on day 10 before we deployed.
The thing I want to call out in this diagram is the color in the staging line. once the staging line turns red on day 2, it only turns black on day 5, which is the Saturday of a long weekend, and then turns red again on the Monday of the long weekend. (Yes, some people were doing development on the Saturday and testing in staging on Monday, even though it was a long weekend. We don’t commonly work on weekends, that’s a different part of the story).
During this ten day period, there was only a brief time when staging was in a state we thought was good, and that was over a weekend. Since we don’t deploy on weekends unless prod is in a bad state, it makes sense that we never deployed from staging to prod until day 10.
The larger point I want to make here is that getting this type of insight from an operational surprise is hard, in the sense that it takes a lot of effort. Even though I put in the initial effort to capture the development activity leading up to the surprise when I first did the writeup, I didn’t gain the above insight until months later, when I tried to understand this particular aspect of it. I had to ask a certain question (how did that bug stay latent for so long), and then I had to take the raw materials of the writeup that I did, and then do some diagramming to visualize the pattern of activity so I could understand it. In retrospect, it was worth it. I got a lot more insight here than: “root cause: latent bug”.
Now I just need to figure out how to tell this as a story without the benefit of a diagram.